Back to Journals » Journal of Multidisciplinary Healthcare » Volume 19
Modeling Behavioral Determinants of Following and Verifying AI-Generated Health Advice: The Roles of eHealth Literacy, Cognitive Load, and Technology Self-Efficacy
Authors Alhur AA ![]() , Alnasser B
, Alnasser B ![]()
Received 19 November 2025
Accepted for publication 15 May 2026
Published 6 June 2026 Volume 2026:19 582741
DOI https://doi.org/10.2147/JMDH.S582741
Checked for plagiarism Yes
Review by Single anonymous peer review
Peer reviewer comments 4
Editor who approved publication: Professor Tilakavati Karupaiah
Anas Ali Alhur,1 Badr Alnasser2
1Department of Health Informatics, College of Public Health and Health Informatics, University of Ha’il, Ha’il, Saudi Arabia; 2Department of Health Management, College of Public Health and Health Informatics, University of Ha’il, Ha’il, Saudi Arabia
Correspondence: Anas Ali Alhur, Department of Health Informatics, College of Public Health and Health Informatics, University of Ha’il, Ha’il, Saudi Arabia, Email [email protected]
Background: The rapid expansion of generative artificial intelligence (GenAI) systems such as ChatGPT, Google Gemini, and Claude is transforming how individuals access and interpret health information. While these tools enhance accessibility and engagement, they also introduce risks related to misinformation, hallucination, and automation bias, raising concerns about how users evaluate and act on AI-generated advice.
Objective: This study examines the psychological and cognitive determinants influencing whether individuals follow or verify AI-generated health advice, focusing on the roles of eHealth literacy, cognitive load, and technology self-efficacy within the context of Saudi Arabia’s digital health transformation.
Methods: A cross-sectional online survey was conducted among 487 Saudi adults with prior experience using GenAI for health-related purposes. Validated instruments, including the eHealth Literacy Scale (eHEALS), Cognitive Load Scale, and Computer and Information Technology Self-Efficacy Scale, were employed. Structural Equation Modeling (SEM) was used to test direct, mediating, and moderating relationships.
Results: Verification intention was positively predicted by eHealth literacy (β = 0.36, p < 0.001) and technology self-efficacy (β = 0.25, p < 0.001), while both reduced reliance on unverified AI advice. Cognitive load increased following behavior (β = 0.29, p < 0.001) and reduced verification (β = – 0.27, p < 0.001). Cognitive load partially mediated the relationship between eHealth literacy and verification, while technology self-efficacy mitigated the negative impact of cognitive load. The model explained 56% of the variance in verification and 44% in following intentions.
Conclusion: eHealth literacy and technology self-efficacy support critical evaluation of AI-generated health information, whereas cognitive load acts as a barrier to informed decision-making. These findings highlight the need for user-centered AI design strategies—such as simplified outputs and verification prompts—and targeted literacy initiatives to promote safe and effective use of AI in healthcare.
Keywords: generative artificial intelligence, AI-generated health advice, eHealth literacy, cognitive load, technology self-efficacy, Saudi Arabia
Introduction
The rise of generative artificial intelligence (GenAI) represents a major shift in how individuals access, interpret, and use health information in digital environments. Unlike traditional information systems, GenAI models generate responses through probabilistic language modeling trained on large-scale datasets, enabling them to produce context-aware, conversational outputs rather than retrieving static information. Conversational systems such as ChatGPT, Google Gemini, and Claude can generate natural, human-like responses to complex health-related queries, allowing personalized guidance to reach a broad and diverse audience.1–3 These systems can synthesize biomedical knowledge, simulate empathetic communication, and present information in accessible language, making them increasingly valuable tools for public health communication and patient education.4–6
The adoption of GenAI in healthcare has accelerated globally, and this transformation is particularly evident in Saudi Arabia. Under Saudi Vision 2030, artificial intelligence has become a central pillar in national efforts to modernize healthcare systems, improve service efficiency, expand digital access, and strengthen patient engagement.7,8 As part of this transformation, AI-driven platforms are increasingly integrated into digital health ecosystems, shaping how individuals seek and interpret health information. However, the persuasive and human-like nature of GenAI outputs introduces new challenges related to information accuracy, user trust, and behavioral responses, especially in rapidly evolving digital health environments such as Saudi Arabia.
A key concern is that GenAI systems do not generate knowledge through direct verification of evidence but through statistical pattern recognition. Although the responses produced are often coherent and contextually appropriate, they may include inaccuracies, biases, or fabricated details—a phenomenon commonly referred to as hallucination.9,10 In practice, this creates a critical dilemma: users may act on incorrect information without verification, while excessive skepticism may lead them to dismiss valid advice. In the Saudi context, where digital health adoption is expanding rapidly and trust in institutional authority often shapes decision-making, understanding how individuals navigate this balance between trust and verification is particularly important.11,12
Trust plays a central role in shaping human interaction with intelligent systems. Appropriate trust allows users to benefit from automation while maintaining critical judgment, whereas misplaced trust can lead to automation bias—the tendency to accept algorithmic outputs without sufficient scrutiny.13 The concept of calibrated trust explains how individuals adjust their reliance on technology based on perceived reliability.14 Prior research indicates that trust in AI systems is influenced by perceptions of accuracy, transparency, and ethical design.15,16 However, there remains limited empirical evidence on how these perceptions translate into concrete behaviors, particularly in the context of health-related decision-making where users must choose whether to follow or verify AI-generated advice. This gap is especially relevant in Saudi Arabia, where cultural norms related to authority, expertise, and technology acceptance may shape user responses in distinct ways.
eHealth literacy represents a critical factor influencing how individuals engage with AI-generated health information. It refers to the ability to locate, evaluate, and apply digital health information effectively.17 Individuals with higher levels of eHealth literacy are generally better equipped to assess the credibility of online content and integrate it into informed decision-making processes.18 However, even highly literate users may be influenced by the fluency and persuasive tone of GenAI outputs, which can reduce critical evaluation.19 In addition, Cognitive Load Theory suggests that when information is complex, dense, or poorly structured, it imposes a burden on working memory, limiting users’ capacity for analytical reasoning.20,21 Under such conditions, individuals may rely on heuristic cues—such as language fluency or perceived authority—rather than systematically evaluating the content. In digital health environments in Saudi Arabia, where users vary widely in digital competence, these cognitive constraints may significantly shape how AI-generated health advice is interpreted and used.
Another important determinant of user behavior is technology self-efficacy, defined as an individual’s confidence in their ability to effectively use and evaluate digital technologies.22 Extensive research has shown that higher self-efficacy is associated with greater persistence, motivation, and analytical engagement when interacting with technology.23,24 Users with strong technological confidence are more likely to critically assess AI-generated outputs, whereas those with lower self-efficacy may experience uncertainty or cognitive fatigue, increasing their reliance on automated recommendations. In the Saudi context, where digital transformation initiatives are expanding access to AI tools across diverse population groups, variations in technology self-efficacy may play a significant role in shaping user behavior and decision-making.
Despite the rapid integration of GenAI into healthcare systems, empirical research examining the behavioral dynamics of trust, verification, and decision-making remains limited. Existing studies have largely focused on general technology acceptance or attitudes toward AI, rather than specific evaluative behaviors such as whether users choose to follow or verify AI-generated advice.25,26 Furthermore, most research has been conducted in Western settings, with limited attention to non-Western contexts where cultural, social, and technological factors may influence user behavior differently.27 In Saudi Arabia, where national strategies emphasize digital health innovation and AI adoption, there is a clear need to understand the cognitive and psychological mechanisms that guide user interactions with AI systems. Generating such evidence is essential for informing the design of ethical guidelines, user-centered AI systems, and policy frameworks that promote safe and responsible engagement with AI-generated health information.
Study Aim
This study examines the behavioral factors that shape whether individuals follow or verify AI-generated health advice. It focuses on how eHealth literacy, cognitive load, and technology self-efficacy interact to influence user behavior. Drawing on cognitive load theory, self-efficacy theory, and trust calibration models, the research seeks to explain these behavioral processes and support the design of AI systems that encourage thoughtful, informed engagement with digital health information.
Theoretical Framework and Hypotheses
Understanding why individuals either follow or verify AI-generated health advice requires an integrative view of cognition, confidence, and trust. The conceptual framework underpinning this study synthesizes three complementary theories: the eHealth Literacy Framework, Cognitive Load Theory, and Self-Efficacy Theory. Together, these frameworks explain how cognitive capacity, informational demands, and self-perceived competence interact to determine the depth of user engagement with AI-generated content.17–23
Building on these perspectives, the study proposes that users with higher eHealth literacy and self-efficacy are more capable of managing cognitive demands, calibrating trust appropriately, and engaging in verification-oriented behaviors. In contrast, lower literacy and self-efficacy are expected to increase cognitive load and promote automatic compliance.
Hypotheses
H1: eHealth literacy positively predicts the intention to verify AI-generated health advice. H2: eHealth literacy negatively predicts the intention to follow AI-generated health advice without verification. H3: Cognitive load negatively influences the intention to verify AI-generated health advice. H4: Cognitive load positively influences the intention to follow AI-generated health advice without verification. H5: Cognitive load mediates the relationship between eHealth literacy and verification behavior. H6: Technology self-efficacy positively predicts the intention to verify AI-generated health advice. H7: Technology self-efficacy negatively predicts the intention to follow AI-generated health advice without verification. H8: Technology self-efficacy moderates the relationship between cognitive load and verification behavior, such that the negative effect of cognitive load is weaker among users with higher self-efficacy.
Conceptual Model
The proposed conceptual model, as shown in Figure 1, integrates these relationships to explain user behavior when interacting with GenAI chatbots. eHealth literacy and technology self-efficacy act as enabling factors, cognitive load functions as a processing constraint, and following versus verification intentions represent behavioral outcomes. This framework underscores that trust in GenAI should be balanced—strong enough to encourage engagement but calibrated to prevent overreliance or neglect of critical reasoning.
 |
Figure 1 Conceptual Model Illustrating the Hypothesized Relationships Among eHealth Literacy, Cognitive Load, and Behavioral Intentions to Follow or Verify AI-Generated Health Advice. |
Theoretical Framework and Hypotheses Development
Understanding why individuals choose to follow or verify AI-generated health advice is an increasingly important area of inquiry within digital health psychology. A key aspect of this behavioral process lies in how cognitive effort, self-confidence, and trust jointly shape decision-making in AI-mediated environments. Investigating these interrelationships provides valuable insights into how users evaluate, accept, or question algorithmic outputs—an issue that has received considerable attention in human–AI interaction research over the past decade.
The conceptual framework underpinning this study synthesizes three complementary theoretical perspectives. The eHealth Literacy Framework conceptualizes individuals’ ability to locate, appraise, and apply health information from digital sources.17,18 Cognitive Load Theory explains how information complexity, presentation style, and task demands influence mental effort and the quality of decision-making.20,21 Self-Efficacy Theory posits that individuals’ confidence in their competence governs their persistence, adaptability, and engagement with challenging cognitive tasks.22,23 Taken together, these frameworks may provide a comprehensive explanation of how people process AI-generated health information: users with higher eHealth literacy and stronger technological self-efficacy are generally better equipped to manage cognitive demands, calibrate trust, and engage in verification-oriented rather than compliance-based behaviors.
eHealth Literacy and Behavioral Response
eHealth literacy has been widely recognized as a fundamental property of effective digital health engagement. It provides the cognitive foundation that enables individuals to interpret, compare, and critically evaluate online health information. Previous studies have documented that individuals with higher literacy levels are more capable of distinguishing credible content from misinformation and integrating multiple cues in decision-making.18 In contrast, users with limited literacy often rely on surface characteristics such as fluency, authority tone, or technical jargon, which may inadvertently be mistaken for accuracy.
Recent developments in AI-based health communication have heightened the need for renewed attention to eHealth literacy. The ability to interrogate AI-generated outputs, identify potential biases, and cross-check recommendations is crucial for maintaining informed agency. Consequently, greater eHealth literacy should foster verification intentions while reducing the tendency toward passive acceptance.
H1: eHealth literacy positively predicts users’ intention to verify AI-generated health advice. H2: eHealth literacy negatively predicts users’ intention to follow AI-generated health advice without verification.
Cognitive Load as a Mediating Mechanism
Cognitive load, defined as the total mental effort required to process information, remains a central construct in explaining technology-mediated decision-making. Within the context of AI-driven health communication, cognitive load encompasses both intrinsic load (arising from task complexity) and extraneous load (arising from suboptimal information presentation).20 When users are exposed to lengthy, ambiguous, or dense AI responses, their cognitive capacity for systematic reasoning diminishes, increasing reliance on heuristic cues such as perceived expertise or writing style.21
A growing body of evidence suggests that elevated cognitive load may therefore discourage verification and instead promote uncritical acceptance of AI-generated advice. Conversely, manageable levels of cognitive load are likely to enhance comprehension and support analytical evaluation. It can therefore be assumed that cognitive load not only exerts a direct influence on user behavior but also serves as a mediating mechanism linking eHealth literacy to verification tendencies.
H3: Cognitive load negatively influences the intention to verify AI-generated health advice. H4: Cognitive load positively influences the intention to follow AI-generated health advice without verification. H5: Cognitive load mediates the relationship between eHealth literacy and verification behavior.
Technology Self-Efficacy and Critical Engagement
Technology self-efficacy, a major area of interest in applied behavioral science, refers to users’ confidence in their ability to interact with and evaluate technological systems effectively.22–24 Several studies have shown that individuals with strong self-efficacy engage more actively with technology, demonstrate higher persistence, and display more reflective decision-making behaviors. By contrast, low self-efficacy is associated with avoidance, overreliance on automated outputs, and reduced analytical engagement.
An implication of this is the possibility that self-efficacy acts as both a direct predictor and a moderator of cognitive processing in AI-mediated communication. High self-efficacy may not only enhance verification intentions directly but also buffer the detrimental effects of cognitive load, sustaining users’ ability to process information critically even under complex conditions.
H6: Technology self-efficacy positively predicts the intention to verify AI-generated health advice. H7: Technology self-efficacy negatively predicts the intention to follow AI-generated health advice without verification. H8: Technology self-efficacy moderates the relationship between cognitive load and verification behavior, such that the negative influence of cognitive load is weaker among users with higher self-efficacy.
Conceptual Model
The proposed conceptual model shown in Figure 1 integrates these theoretical relationships to explain behavioral outcomes in GenAI–user interactions. eHealth literacy and technology self-efficacy operate as enabling factors that enhance cognitive regulation and trust calibration, whereas cognitive load represents a processing constraint that can either impede or mediate these effects. The behavioral outcomes—verification and following intentions—capture the extent to which users act reflectively or automatically when faced with AI-generated health recommendations.
Taken together, this framework highlights that trust in AI is not inherently problematic but must be appropriately calibrated. Excessive skepticism may hinder engagement, while overreliance can compromise safety. Balancing these dynamics requires both cognitive capability and technological confidence—qualities that this model seeks to quantify and explain empirically.
Methodology
Research Design and Setting
This study employed a cross-sectional quantitative research design using an online survey to examine the behavioral determinants influencing users’ intentions to follow or verify AI-generated health advice. This design is well suited for capturing individual differences in perceptions, cognitive processes, and technology-related behaviors within a naturalistic, non-clinical setting. Cross-sectional surveys are widely used in health informatics and behavioral research due to their efficiency in collecting attitudinal and behavioral data from large populations at a single point in time.
Data were collected between March and June 2025 across the Kingdom of Saudi Arabia (KSA), a country undergoing rapid digital transformation under the Vision 2030 Health Sector Reform Program. Ethical approval was obtained from the Research Ethics Committee (REC) at the University of Hail (Approval No. H-2025-357). All procedures adhered to the ethical principles outlined in the Declaration of Helsinki and Saudi national research ethics guidelines.
Participants and Sampling
Participants were adults aged 18 years or older residing in Saudi Arabia who had prior experience using at least one generative AI platform (eg., ChatGPT, Google Gemini, or Claude) for health-related purposes. Eligibility criteria included basic digital literacy, proficiency in Arabic or English, and voluntary consent to participate.
A convenience sampling approach was used to recruit participants through online platforms, including Twitter/X, LinkedIn, WhatsApp academic networks, and institutional mailing lists. This approach enabled efficient access to a diverse population of AI users; however, it may limit the generalizability of findings to the broader population.
The required sample size was calculated using Cochran’s formula for large populations (95% confidence level, 5% margin of error), yielding a minimum of 385 participants. To account for incomplete responses, the target sample size was set at 500. A total of 516 responses were collected, of which 487 valid responses were retained after data screening.
While the final sample included participants from varied demographic backgrounds, it was relatively skewed toward male respondents and individuals with higher education levels. This distribution should be considered when interpreting the generalizability of the findings.
Instrument Development
The survey instrument was developed by adapting validated scales aligned with the study’s conceptual framework. The questionnaire comprised five sections: demographics, eHealth literacy, cognitive load, technology self-efficacy, and behavioral intention.
eHealth literacy was measured using the eight-item eHealth Literacy Scale (eHEALS),17,18 rated on a five-point Likert scale (1 = strongly disagree to 5 = strongly agree). Cognitive load was assessed using the Cognitive Load Scale developed by Leppink et al (2013), capturing both intrinsic and extraneous load across seven items measured on a seven-point Likert scale.
Technology self-efficacy was measured using the Computer and Information Technology Self-Efficacy Scale (CITSE),22 consisting of eight items rated on a five-point Likert scale. Behavioral intentions were measured using a six-item scale adapted from the automation trust literature,13,14,25 comprising two subdimensions: following intention and verification intention.
All survey items were translated into Arabic and back-translated into English using a standardized forward–backward translation procedure to ensure linguistic and cultural equivalence. Content validity was assessed by three bilingual experts in digital health and behavioral psychology. A pilot study (n = 40) was conducted to evaluate clarity and reliability, with all constructs demonstrating strong internal consistency (Cronbach’s α > 0.80).
Data Collection Procedure
Data were collected using a secure online survey administered via Google Forms, accessible on both desktop and mobile devices. Participants were provided with an information sheet outlining the study purpose, confidentiality measures, and their rights. Electronic informed consent was obtained prior to participation.
To ensure data quality, the survey included attention-check items and was configured to limit duplicate submissions. No personally identifiable information (eg., names or IP addresses) was collected. The average completion time was approximately 7 minutes.
Data Analysis
Data were analyzed using IBM SPSS (version 29) and AMOS (version 29). The analysis followed three stages: preliminary analysis, measurement model evaluation, and structural model testing.
Preliminary analysis included screening for missing data, outliers, and normality. Descriptive statistics (means, standard deviations, frequencies) were calculated. Reliability was assessed using Cronbach’s alpha, composite reliability (CR), and average variance extracted (AVE).
Confirmatory Factor Analysis (CFA) was conducted to evaluate the measurement model. Model fit was assessed using standard indices: χ2/df < 3.0, Comparative Fit Index (CFI) ≥ 0.90, Tucker–Lewis Index (TLI) ≥ 0.90, and Root Mean Square Error of Approximation (RMSEA) ≤ 0.08. Convergent validity was established when AVE > 0.50, and discriminant validity was assessed using the Fornell–Larcker criterion and the Heterotrait–Monotrait ratio (HTMT).
Structural Equation Modeling (SEM) with 2000 bootstrapped samples was used to test the hypothesized relationships (H1–H8), including direct, mediating, and moderating effects. Mediation was assessed through indirect path analysis, and moderation was examined using an interaction term (cognitive load × technology self-efficacy). Statistical significance was set at p < 0.05.
The supplementary appendices provide additional methodological and statistical details in numerical order. Appendix 1 presents item-level descriptive statistics for the eHEALS, intrinsic cognitive load, extraneous cognitive load, and technology self-efficacy scales. Appendix 2 presents item-level descriptive statistics for the verification intention and the following intention scales. Appendix 3 summarizes scale reliability, convergent validity, discriminant validity, and inter-construct correlations. Appendix 4 provides the measurement and structural model fit indices, standardized SEM path estimates, mediation results, moderation results, and explained variance values. Appendix 5 includes the full survey items used in the study.
Ethical Considerations
This study was reviewed and approved by the Research Ethics Committee (REC) at the University of Hail (Approval No. H-2025-357). All participants provided electronic informed consent prior to participation. The consent form explicitly stated that participation was voluntary, that respondents could withdraw from the study at any time without penalty, and that no incentives were offered.
To maintain confidentiality and data integrity, no identifying information (eg., names, IP addresses) was collected. All responses were stored securely, anonymized, and analyzed in aggregate form only.
The study adhered to the ethical principles of autonomy, beneficence, confidentiality, and non-maleficence, in alignment with the Saudi national research ethics guidelines and the Declaration of Helsinki for research involving human participants.
Results
Participant Characteristics
After data screening and exclusion of incomplete responses, 487 valid cases were retained for analysis. Table 1 summarizes the demographic profile of participants. The sample was predominantly male (68.2%), with most respondents aged 25–44 years (67.8%) and holding at least a bachelor’s degree (74.3%). More than half (58.5%) reported using generative AI (GenAI) systems such as ChatGPT, Gemini, or Claude on a weekly basis, and nearly one-third (31.4%) had previously sought AI-generated health information within the preceding three months.
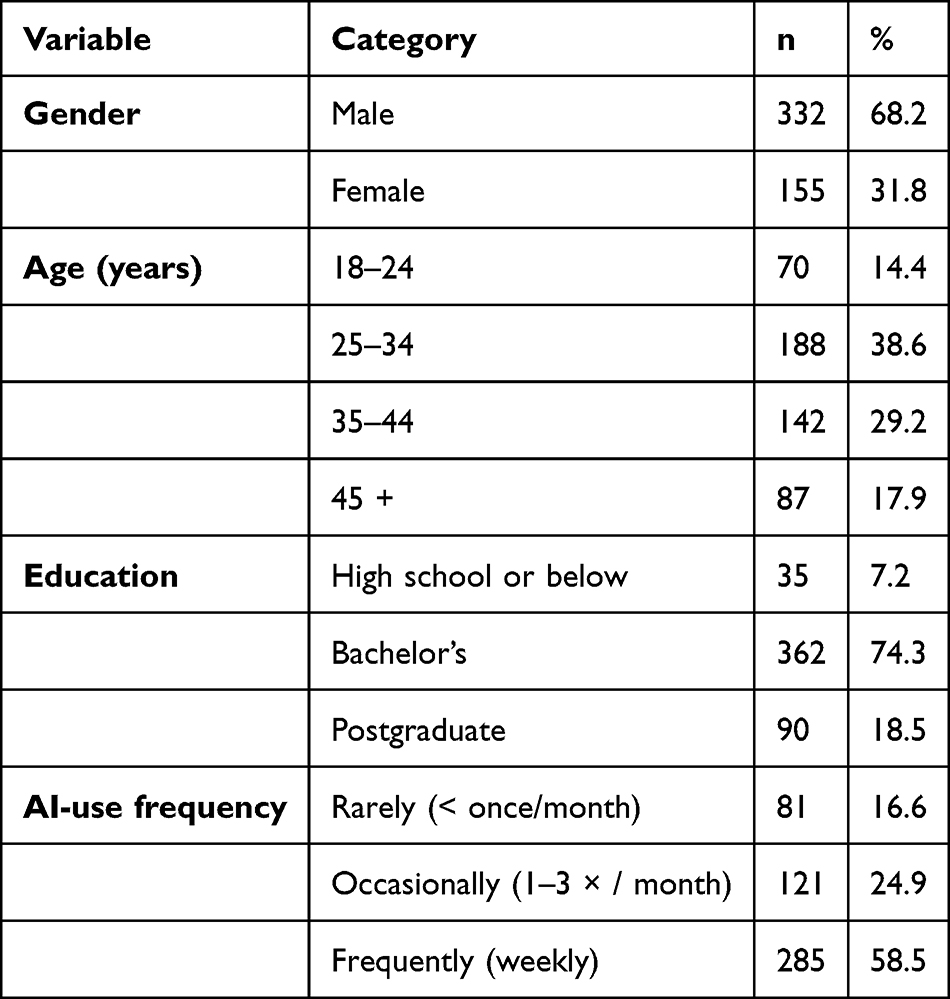 |
Table 1 Demographic Characteristics of Respondents (N = 487) |
Reliability and Descriptive Statistics
All scales demonstrated excellent internal consistency (Cronbach’s α = 0.85–0.92). Table 2 presents the descriptive statistics and reliability indicators. Overall, participants reported moderate-to-high eHealth literacy and technology self-efficacy, alongside relatively lower perceived cognitive load. Male respondents displayed marginally higher self-efficacy and verification tendencies (M = 4.18) compared with females (M = 4.02),
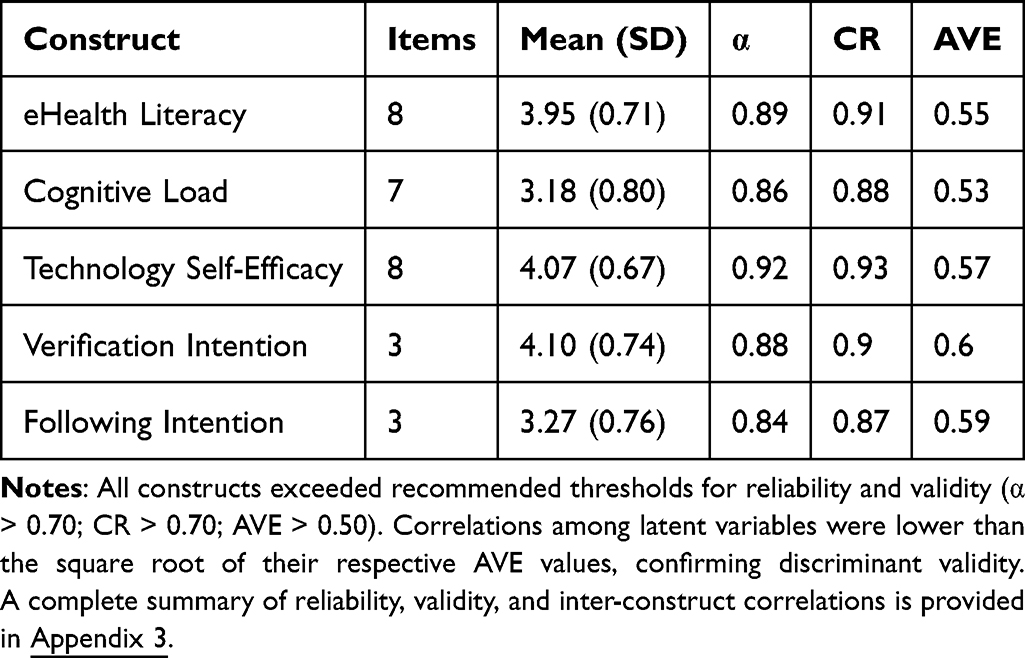 |
Table 2 Descriptive Statistics and Reliability Indicators |
…although the differences were not statistically significant (p > 0.05). Detailed item-level descriptive statistics for eHealth literacy, cognitive load, and technology self-efficacy are provided in Appendix 1. Item-level descriptive statistics for verification and following intention measures are provided in Appendix 2.
Measurement Model Evaluation
Confirmatory factor analysis (CFA) was conducted to evaluate the adequacy of the measurement model comprising five latent constructs: eHealth literacy, cognitive load, technology self-efficacy, verification intention, and following intention. The model demonstrated a good fit to the data: χ2 = 406.12, df = 214, χ2/df = 1.90, CFI = 0.952, TLI = 0.944, RMSEA = 0.043 (90% CI: 0.037–0.050), SRMR = 0.038.
All standardized factor loadings were statistically significant (p < 0.001) and ranged from 0.64 to 0.88, providing strong evidence for convergent validity and satisfactory construct representation. In addition, all constructs exceeded recommended reliability and validity thresholds (CR > 0.70; AVE > 0.50), confirming the measurement model’s robustness prior to structural analysis.
Structural Model Evaluation
The Structural Equation Model of Behavioral Determinants Influencing Following and Verification of AI-Generated Health Advice, shown in Figure 2. The hypothesized structural model also achieved an excellent level of fit: χ2 = 454.85, df = 237, χ2/df = 1.92, CFI = 0.947, TLI = 0.937, RMSEA = 0.044, SRMR = 0.041.
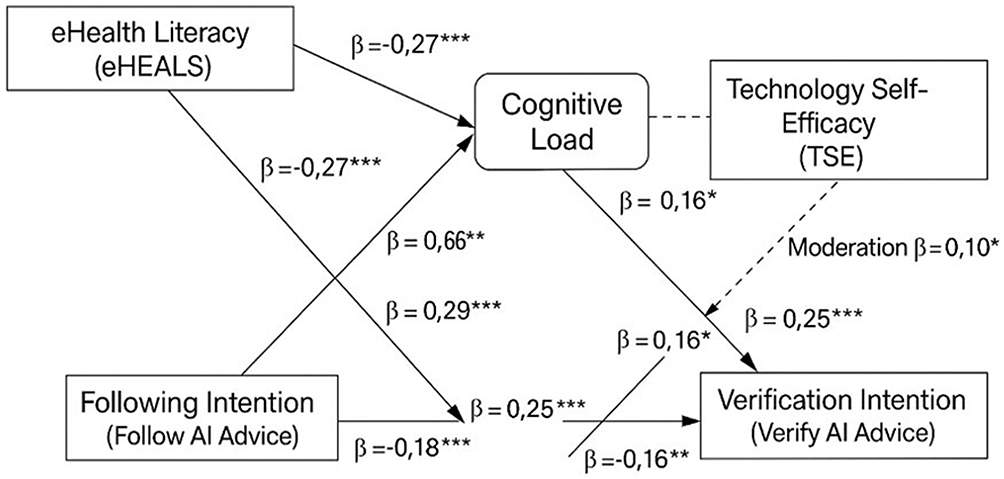 |
Figure 2 Structural Equation Model of Behavioral Determinants Influencing Following and Verification of AI-Generated Health Advice. Notes: Standardized path coefficients (β) are presented along the arrows. Solid lines indicate direct effects, whereas dashed lines indicate moderating effects. * p < 0.05. ** p < 0.01. *** p < 0.001. |
As shown in Table 3, all proposed direct, indirect, and moderating relationships were statistically significant in the expected directions. The final model explained 56% of the variance in verification intention and 44% in following intention, indicating strong explanatory power for behavioral responses toward AI-generated health advice. A complete summary of model fit indices and standardized SEM path estimates is provided in Appendix 4.
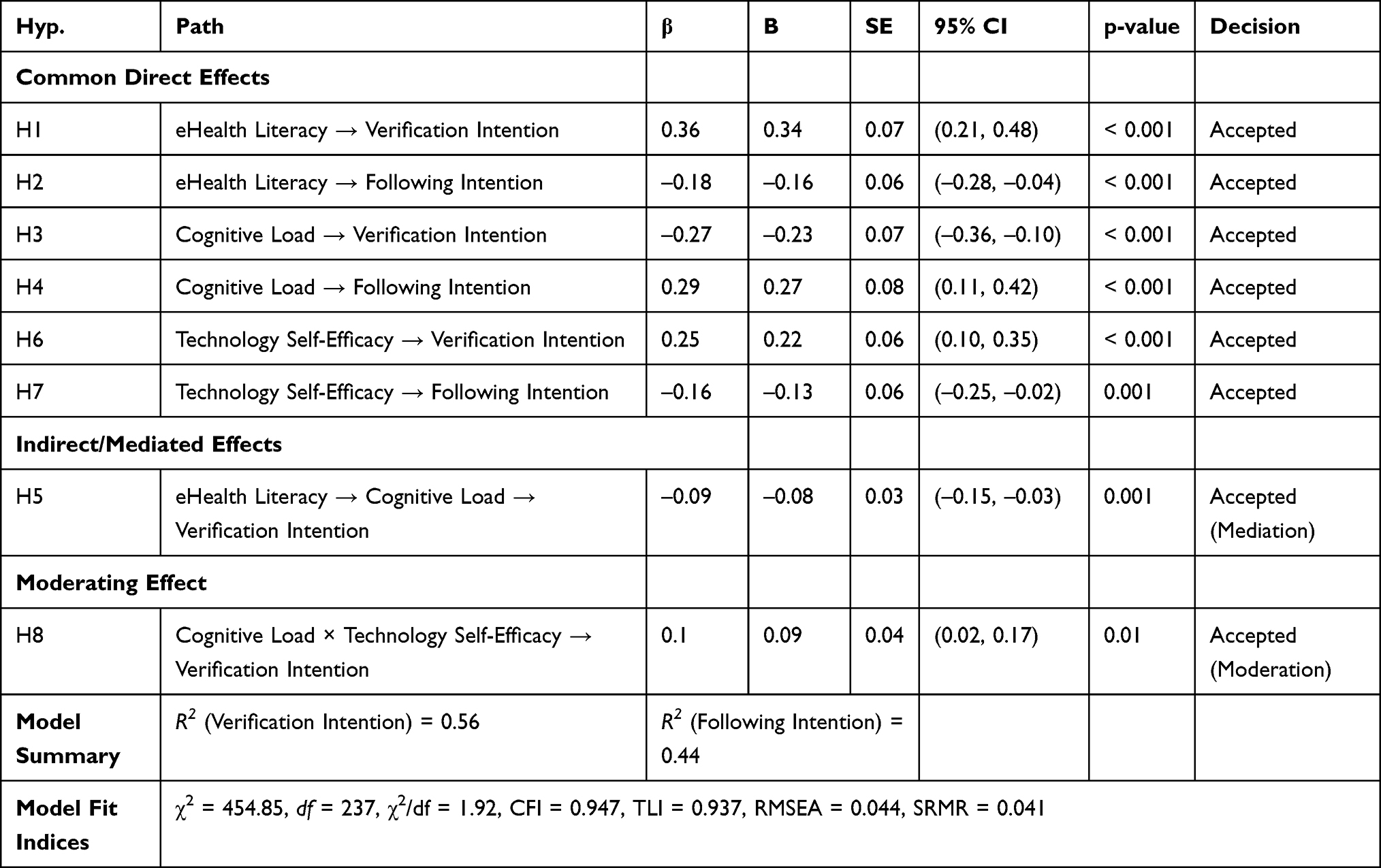 |
Table 3 Standardized and Unstandardized Path Estimates, Confidence Intervals, and Significance Values for Hypothesized Relationships in the Structural Model (N = 487) |
Mediation and Moderation Effects
Bootstrapped analysis (2,000 resamples) confirmed a partial mediation of cognitive load in the literacy–verification link (β = –0.09, 95% CI [–0.17, –0.04]). Users with higher eHealth literacy reported lower perceived cognitive load, which increased their verification intention.
The interaction between cognitive load and self-efficacy was significant (β = 0.10, p = 0.010). Simple-slope analysis indicated that at high self-efficacy, the negative slope between cognitive load and verification intention flattened considerably, suggesting that confident users maintained analytical engagement despite mental effort. Detailed direct, indirect, and moderated effects are presented in Appendix 4.
Discussion
This study examined how eHealth literacy, cognitive load, and technology self-efficacy shape individuals’ intentions to verify or follow AI-generated health advice within the context of Saudi Arabia’s rapidly evolving digital health ecosystem. Drawing on the eHealth Literacy Framework, Cognitive Load Theory, and Self-Efficacy Theory, the findings provide empirical insight into the cognitive and psychological mechanisms that govern user engagement with generative AI systems. The structural model demonstrated strong explanatory power, offering a nuanced understanding of how users navigate trust, verification, and decision-making when interacting with AI-mediated health information in a digitally transforming society.
The findings underscore the central role of eHealth literacy in shaping user behavior. Individuals with higher literacy levels were more likely to verify AI-generated health information and less likely to accept it without critical evaluation. This aligns with prior research demonstrating that digital literacy enhances individuals’ ability to assess the credibility of online information and engage in analytical reasoning when interacting with algorithmic outputs.6,9,10,18,19 In the Saudi context, where national initiatives are actively promoting digital health engagement under Vision 2030, these findings highlight the importance of strengthening population-level eHealth literacy as a foundational component of safe AI adoption. Enhancing literacy may be particularly important for populations with limited digital experience, who may be more vulnerable to automation bias and misinformation.
Cognitive load emerged as a key mechanism influencing behavioral responses. Higher levels of cognitive load were associated with reduced verification and increased reliance on AI-generated advice, supporting the assumptions of Cognitive Load Theory.20,21 When AI-generated content is complex, lengthy, or ambiguous, users may experience mental fatigue, leading them to rely on heuristic cues such as language fluency or perceived authority. This pattern reflects cognitive offloading, where individuals increasingly depend on automated systems when cognitive effort is high.25–29 Within Saudi Arabia’s diverse user population—characterized by varying levels of digital literacy and technological familiarity—these cognitive constraints may significantly influence how AI-generated health information is processed and acted upon.
From a practical standpoint, these findings highlight the importance of designing AI systems that minimize unnecessary cognitive burden. Features such as concise outputs, structured formatting, clear segmentation of information, and transparent sourcing can support users in engaging more critically with AI-generated content. Importantly, the mediating role of cognitive load suggests that even individuals with high eHealth literacy may struggle to maintain analytical engagement under cognitively demanding conditions. This indicates that improving user literacy alone is insufficient; system-level design considerations must also play a central role in promoting safe and effective AI use.
Technology self-efficacy also played a significant role in shaping user behavior. Individuals with higher confidence in their ability to use and evaluate digital technologies were more likely to verify AI-generated advice and less likely to follow it uncritically. This finding is consistent with prior research linking self-efficacy to greater persistence, engagement, and reflective decision-making in digital environments.22–24 Moreover, the moderating effect observed in this study suggests that self-efficacy can buffer the negative impact of cognitive load. Even when information is complex, users with higher confidence are better able to sustain critical evaluation.29–32 In the Saudi context, where digital transformation initiatives aim to expand access to AI technologies across diverse population groups, fostering technological confidence is essential for ensuring equitable and safe use.
These findings altogether support the proposed conceptual model and contribute to a more nuanced understanding of trust calibration in AI-mediated health contexts. The results suggest that user behavior is a trade-off between acceptance and verification, rather than a binary view of trust. The distinction between following and verifying AI-generated advice is a meaningful step forward in the study of human-AI interaction, suggesting that suitably interacting with AI requires both cognitive capacity and psychological readiness.32–35 This balance is especially important in fast digitalizing healthcare settings like Saudi Arabia to ensure that users gain from the benefits of AI technologies without being overly reliant on them.
From a theoretical perspective, this study extends existing research by integrating cognitive, literacy, and psychological constructs into a unified framework that explains behavioral responses to AI-generated health information.36–40 It moves beyond traditional technology acceptance models by focusing on evaluative behaviors rather than general attitudes, thereby offering a more behaviorally grounded understanding of user–AI interaction.41–43 From a practical perspective, the findings provide actionable insights for developers, educators, and policymakers seeking to promote responsible AI use in healthcare settings.
Practical and Policy Implications
The findings have several important implications for AI developers, healthcare organizations, and policymakers, particularly within the Saudi healthcare system. For developers, incorporating user-centered design principles is essential to reduce cognitive load and support informed decision-making. This includes features such as simplified language, bullet-point summaries, visual structuring of information, and built-in prompts encouraging users to verify health advice through credible sources. Embedding transparency mechanisms—such as source attribution and confidence indicators—may further enhance users’ ability to critically evaluate AI outputs.
Healthcare organizations can play a key role by integrating AI literacy into patient education and clinical communication strategies. Educating users about both the capabilities and limitations of AI systems can help foster more balanced and informed engagement. Training initiatives targeting different population groups—particularly those with lower digital literacy—may be especially valuable in reducing disparities in AI use.
At the policy level, the findings reinforce the importance of aligning technological advancement with behavioral readiness. Saudi Arabia’s Vision 2030 strategy emphasizes digital transformation and AI integration; however, the present results suggest that successful implementation also depends on strengthening eHealth literacy and technology self-efficacy among users. Policymakers may consider incorporating these constructs into national digital health strategies as measurable indicators of readiness, ensuring that technological adoption is accompanied by adequate user competence and awareness.
Limitations and Future Research
While this study provides important insights, several limitations should be acknowledged. First, the cross-sectional design limits the ability to infer causal relationships among variables. Future research employing longitudinal or experimental designs would provide stronger evidence of causal pathways. Second, the use of convenience sampling may limit the generalizability of findings. The sample was relatively skewed toward male participants and individuals with higher education levels, which may not fully reflect the broader population in Saudi Arabia. Third, reliance on self-reported measures introduces the potential for social desirability and recall biases.
Future research should explore these relationships across more diverse and representative populations, as well as examine behavioral outcomes in real-world settings. Experimental studies could test the effectiveness of interface design interventions aimed at reducing cognitive load and promoting verification behavior. Additionally, further investigation into cultural factors—such as trust in authority, collectivism, and technology acceptance norms in Arab contexts—may provide deeper insight into how user behavior varies across different sociocultural environments.
Conclusion
This study contributes to the growing body of knowledge on human–AI interaction by demonstrating how behavioral and cognitive factors shape individuals’ intentions to follow or verify AI-generated health information. The findings show that eHealth literacy and technology self-efficacy function as key enablers of critical evaluation and responsible engagement, whereas cognitive load acts as a significant barrier that can promote uncritical reliance on AI-generated advice. These results highlight that effective use of AI in healthcare depends not only on technological capabilities but also on users’ cognitive capacity and confidence in interacting with digital systems.
Within the context of Saudi Arabia’s ongoing digital transformation under Vision 2030, these findings carry important implications for the safe and effective integration of AI into healthcare. Promoting balanced and informed engagement with AI-generated health information requires a dual focus on both user capability and system design. AI systems should be developed with an emphasis on simplicity, transparency, and cognitively efficient presentation of information to reduce user burden and support verification behaviors. At the same time, policymakers and healthcare institutions should prioritize initiatives that strengthen eHealth literacy and technology self-efficacy across the population, ensuring that individuals are equipped to critically assess AI-generated outputs.
Future research should build on these findings by employing longitudinal and experimental designs to better establish causal relationships and evaluate intervention strategies. In addition, further investigation into contextual and cultural factors—particularly within rapidly digitalizing societies—will be essential for understanding how users interact with AI-generated health information in diverse environments. Advancing this line of research will support the development of more accountable, user-centered, and ethically grounded AI systems in healthcare.
Disclosure
The authors report no conflicts of interest in this work.
References
1. Norman CD, Skinner HA. eHealth literacy: essential skills for consumer health in a networked world. J Med Internet Res. 2006;8(2):e9. doi:10.2196/jmir.8.2.e9
2. Paige SR, Krieger JL, Stellefson M. The influence of eHealth literacy on perceived trust in online health communication channels and sources. J Health Commun. 2017;22(1):53–14. doi:10.1080/10810730.2016.1250846
3. Neter E, Brainin E. eHealth literacy: extending the digital divide to the realm of health information. J Med Internet Res. 2012;14(1):e19. doi:10.2196/jmir.1619
4. Van der Vaart R, Drossaert C. Development of the digital health literacy instrument (DHLI): measuring a broad spectrum of health 1.0 and health 2.0 skills. J Med Internet Res. 2017;19(1):e27. doi:10.2196/jmir.6709
5. Leppink J, Paas F, Van Gog T, Van der Vleuten CPM, Van Merriënboer JJG. Effects of pairs of problems and examples on task performance and different types of cognitive load. Learn Instr. 2014;30:32–42. doi:10.1016/j.learninstruc.2013.12.001
6. Sweller J. Cognitive load theory. Psychol Learn Motiv. 2011;55:37–76. doi:10.1016/B978-0-12-387691-1.00002-8
7. Bandura A. Self-Efficacy: The Exercise of Control. New York, NY: W. H. Freeman; 1997.
8. Compeau DR, Higgins CA. Computer self-efficacy: development of a measure and initial test. MIS Q. 1995;19(2):189–211. doi:10.2307/249688
9. Tams S, Thatcher JB, Grover V. Power, politics, and information systems: a meta-analysis of trust, risk, and technology acceptance. Eur J Inf Syst. 2018;27(1):26–44. doi:10.1057/s41303-017-0052-0
10. Hoff KA, Bashir M. Trust in automation: integrating empirical evidence on factors that influence trust. Hum Fact. 2015;57(3):407–434. doi:10.1177/0018720814547570
11. Lee JD, See KA. Trust in automation: designing for appropriate reliance. Hum Fact. 2004;46(1):50–80. doi:10.1518/hfes.46.1.50.30392
12. Venkatesh V, Davis FD. A theoretical extension of the technology acceptance model: four longitudinal field studies. Manage Sci. 2000;46(2):186–204. doi:10.1287/mnsc.46.2.186.11926
13. Sillence E, Briggs P, Harris PR, Fishwick L. Health websites that people can trust—The case of online health advice. Interact Comput. 2007;19(1):32–42. doi:10.1016/j.intcom.2006.07.009
14. Shariff SZ, Fang J. Trust, transparency, and responsibility in AI-assisted healthcare: a review of ethical frameworks. Front Artif Intell. 2022;5:887654. doi:10.3389/frai.2022.887654
15. Chen T, Wang Y. Exploring cognitive load and decision confidence in AI-assisted diagnosis systems. Comput Human Behav. 2024;155:108032. doi:10.1016/j.chb.2024.108032
16. Kim S, Park E, Oh J. Determinants of user engagement and trust in AI-based health chatbots. Front Digit Health. 2023;5:117654. doi:10.3389/fdgth.2023.117654
17. Abdullah SM, Alalwan AA, Dwivedi YK. Examining AI-based chatbot adoption in healthcare: the moderating role of health anxiety. Inf Technol People. 2022;35(8):135–155. doi:10.1108/ITP-08-2021-0629
18. Alharbi AF, Alshammari MM. eHealth literacy, trust, and adoption of AI-based digital health tools among older adults in Saudi Arabia. BMC Med Inform Decis Mak. 2024;24(1):151. doi:10.1186/s12911-024-00951-3
19. Alhur AA, Alotaibi S, Alhalwani D, Eisa R, Alshahrani S, Alqurashi M. Public perspectives on digital innovations in pharmacy: a survey on health informatics and medication management. J Infrastruct Policy Dev. 2024;8(8):5450. doi:10.24294/jipd.v8i8.5450
20. Biswas M, Murray J. The impact of education level on AI reliance, habit formation, and usage. In:
21. World Health Organization. Ethics and Governance of Artificial Intelligence for Health: WHO Guidance. Geneva: World Health Organization; 2023.
22. Prakash AV, Das S. (Why) do we trust AI?: a case of AI-based health chatbots. Australas J Inf Syst. 2024;28. doi:10.3127/ajis.v28.4235
23. Ramrath M, Scharmann A, Ridder A, Kuhn TZ, Weller S, Krämer NC. Trust in AI chatbots: the perceived expertise of ChatGPT in subjective and objective tasks. Front Artif Intell Appl. 2024. doi:10.3233/faia240200
24. Zhu Y, Zhang J, Wu J, Liu Y. AI is better when I’m sure: the influence of certainty of needs on consumers’ acceptance of AI chatbots. J Bus Res. 2022;150:642–652. doi:10.1016/j.jbusres.2022.06.044
25. Wångdahl J, Dahlberg K, Jaensson M, Nilsson U. Arabic version of the electronic health literacy scale in Arabic-speaking individuals in Sweden: prospective psychometric evaluation study. J Med Internet Res. 2021;23(3):e24466. doi:10.2196/24466
26. Savitz DA, Wellenius GA. Can cross-sectional studies contribute to causal inference? It depends. Am J Epidemiol. 2023;192(4):514–516. doi:10.1093/aje/kwac037
27. Alhur A. Redefining healthcare with artificial intelligence (AI): the contributions of ChatGPT, Gemini, and Co-pilot. Cureus. 2024;16(4).
28. Van der Ham IJ, Van der Kuil MN, Claessen MH. Quality of self-reported cognition: effects of age and gender on spatial navigation self-reports. Aging Mental Health. 2021;25(5):873–878. doi:10.1080/13607863.2019.1697200
29. Alhur AA, Alqathanin W, Aljafel R, et al. Evaluating the public’s awareness and acceptance of AI technologies in personalized pharmacotherapy. Teikyo Med J. 2024;47:8413–8426.
30. Redifer JL, Bae CL, Zhao Q. Self-efficacy and performance feedback: impacts on cognitive load during creative thinking. Learn Instr. 2021;71:101395. doi:10.1016/j.learninstruc.2020.101395
31. Feldon DF, Brockbank R, Litson K. Direct effects of cognitive load on self-efficacy during instruction. J Educ Psychol. 2024;116(7):1153. doi:10.1037/edu0000810
32. Hartelt T, Martens H. Self-regulatory and metacognitive instruction regarding student conceptions: influence on students’ self-efficacy and cognitive load. Front Psychol. 2024;15:1450947. doi:10.3389/fpsyg.2024.1450947
33. Alhur AA, Fregni F, Alsahmmari MM, Naqui C, Sims DA. “I believe in you”: student experiences of faculty empathy in health sciences education. Adv Med Educ Pract. 2026;17:1–6. doi:10.2147/AMEP.S567525
34. Fida R, Paciello M, Tramontano C, Barbaranelli C, Farnese ML. “Yes, I can”: the protective role of personal self-efficacy in hindering counterproductive work behavior under stressful conditions. Anxiety Stress Coping. 2015;28(5):479–499. doi:10.1080/10615806.2014.969718
35. Alhur AA, Al Yousef N, Alkhami Y, et al. Depression, anxiety, stress, and associated factors among health sciences students: a cross-sectional study. Health Psychol Res. 2025;13(4):e81240044. doi:10.14440/hpr.0204
36. Bogale BM, Alhur AA. Integrating indigenous knowledge into inclusive education: a quest for culturally responsive practices and epistemic justice for students with disabilities in North Wollo, Ethiopia. Oxf Dev Stud. 2026;1–8. doi:10.1080/13600818.2026.2659679
37. Alhur AA, Al-Kahtani NK. Generative artificial intelligence in health informatics education: a comprehensive bibliometric assessment of cognitive outcome research (2019–2025). Int J Adv Signal Image Sci. 2026;895–915. doi:10.29284/r2man269
38. Alhur AA, Khlaif ZN, Hamamra B, Hussein E. Paradox of AI in higher education: qualitative inquiry into AI dependency among educators in Palestine. JMIR Med Educ. 2025;11:e74947. doi:10.2196/74947
39. Wu Q, Liu X, Zhong R. Study of adoption of AI-generated health information in video platforms using SEM and fsQCA. Aslib J Inf Manag. 2025. doi:10.1108/AJIM-01-2025-0037
40. Diwanji VS, Geana M, Pei J, Nguyen N, Izhar N, Chaif RH. Consumers’ emotional responses to AI-generated versus human-generated content: the role of perceived agency, affect and gaze in health marketing. Int J Hum Comput Interact. 2025;41(19):12270–12290.
41. Guo S, Song Y, Chen G, Han H, Wu H, Ma J. Promoting trust and intention to adopt health information generated by ChatGPT among healthcare customers: an empirical study. Digit Health. 2025;11:20552076251374121. doi:10.1177/20552076251374121
42. Alhur AA, Alsaeed W, Albalawi B, et al. Pharmacy students’ attitudes towards AI in pharmaceutical practices. J Pioneering Med Sci. 2025;14:132–137. doi:10.47310/jpms2025140721
43. Zhou T, Lu H. The effect of trust on user adoption of AI-generated content. Electron Libr. 2025;43(1):61–76. doi:10.1108/EL-07-2024-0213
 © 2026 The Author(s). This work is published and licensed by Dove Medical Press Limited. The
full terms of this license are available at https://www.dovepress.com/terms
and incorporate the Creative Commons Attribution
- Non Commercial (unported, 4.0) License.
By accessing the work you hereby accept the Terms. Non-commercial uses of the work are permitted
without any further permission from Dove Medical Press Limited, provided the work is properly
attributed. For permission for commercial use of this work, please see paragraphs 4.2 and 5 of our Terms.
© 2026 The Author(s). This work is published and licensed by Dove Medical Press Limited. The
full terms of this license are available at https://www.dovepress.com/terms
and incorporate the Creative Commons Attribution
- Non Commercial (unported, 4.0) License.
By accessing the work you hereby accept the Terms. Non-commercial uses of the work are permitted
without any further permission from Dove Medical Press Limited, provided the work is properly
attributed. For permission for commercial use of this work, please see paragraphs 4.2 and 5 of our Terms.