Back to Journals » International Journal of General Medicine » Volume 14
Prediction of Disease Progression of COVID-19 Based upon Machine Learning
Authors Xu F, Chen X, Yin X, Qiu Q, Xiao J, Qiao L, He M, Tang L, Li X, Zhang Q, Lv Y, Xiao S, Zhao R, Guo Y, Chen M ![]() , Chen D, Wen L, Wang B, Nian Y, Liu K
, Chen D, Wen L, Wang B, Nian Y, Liu K ![]()
Received 30 November 2020
Accepted for publication 26 March 2021
Published 29 April 2021 Volume 2021:14 Pages 1589—1598
DOI https://doi.org/10.2147/IJGM.S294872
Checked for plagiarism Yes
Review by Single anonymous peer review
Peer reviewer comments 2
Editor who approved publication: Dr Scott Fraser
Fumin Xu,1,* Xiao Chen,2,* Xinru Yin,1 Qiu Qiu,3 Jingjing Xiao,4 Liang Qiao,5 Mi He,5 Liang Tang,6 Xiawei Li,1 Qiao Zhang,1 Yanling Lv,1 Shili Xiao,1 Rong Zhao,1 Yan Guo,1 Mingsheng Chen,5 Dongfeng Chen,1 Liangzhi Wen,1,7 Bin Wang,1,8 Yongjian Nian,5 Kaijun Liu1,8
1Department of Gastroenterology, Daping Hospital, Army Medical University, Chongqing, People’s Republic of China; 2Department of Nuclear Medicine, Daping Hospital, Army Medical University, Chongqing, People’s Republic of China; 3Department of Gastroenterology, People’s Hospital of Chongqing Hechuan, Chongqing, People’s Republic of China; 4Department of Medical Engineering, Xinqiao Hospital, Army Medical University, Chongqing, People’s Republic of China; 5College of Biomedical Engineering and Imaging Medicine, Army Medical University, Chongqing, People’s Republic of China; 6Department of Internal Medicine, 63790 Military Hospital of the Chinese People’s Liberation Army, Xichang, People’s Republic of China; 7Department of Infectious Disease, Taikang Tongji Hospital, Wuhan, People’s Republic of China; 8Department of Infectious Disease, Wuhan Huoshenshan Hospital, Wuhan, People’s Republic of China
*These authors contributed equally to this work
Correspondence: Kaijun Liu
Department of Gastroenterology, Daping Hospital, Army Medical University, 10 Changjiang Branch Road, Yuzhong District, Chongqing, 400038, People’s Republic of China
Tel +86 135-9406-7813
Email [email protected]
Background: Since December 2019, COVID-19 has spread throughout the world. Clinical outcomes of COVID-19 patients vary among infected individuals. Therefore, it is vital to identify patients at high risk of disease progression.
Methods: In this retrospective, multicenter cohort study, COVID-19 patients from Huoshenshan Hospital and Taikang Tongji Hospital (Wuhan, China) were included. Clinical features showing significant differences between the severe and nonsevere groups were screened out by univariate analysis. Then, these features were used to generate classifier models to predict whether a COVID-19 case would be severe or nonsevere based on machine learning. Two test sets of data from the two hospitals were gathered to evaluate the predictive performance of the models.
Results: A total of 455 patients were included, and 21 features showing significant differences between the severe and nonsevere groups were selected for the training and validation set. The optimal subset, with eleven features in the k–nearest neighbor model, obtained the highest area under the curve (AUC) value among the four models in the validation set. D-dimer, CRP, and age were the three most important features in the optimal-feature subsets. The highest AUC value was obtained using a support vector–machine model for a test set from Huoshenshan Hospital. Software for predicting disease progression based on machine learning was developed.
Conclusion: The predictive models were successfully established based on machine learning, and achieved satisfactory predictive performance of disease progression with optimal-feature subsets.
Keywords: COVID-19, disease progression, machine-learning models
Introduction
By November 22, 2020, more than 180 countries had reported a total of 57.8 million confirmed COVID-19 cases, a condition caused by SARS-CoV2.1 SARS-CoV-2 is a novel enveloped RNA β-coronavirus, which has phylogenetic similarity to SARS-CoV, the pathogen causing SARS.2 The clinical symptoms of COVID-19 have a broad spectrum, and vary among individuals.3 Most infected individuals have mild or subclinical illness, while approximately 15.7%–32% of hospitalized COVID-19 patients develop severe acute respiratory distress or are admitted to an intensive care unit.3,4 Potential risk factors to identify patients who will develop into severe or critical severe cases at an early stage include older age, underlying comorbidities, and elevated D-dimer.5,6 As the COVID-19 outbreak continues to evolve, it is critical to find patients at high risk of disease progression. Several investigations have analyzed risk factors associated with disease progression and clinical outcomes, and suggested that older age, comorbidities, immunoresponse were potential risk factors.6–10 However, the clinical details were not well described, and many important laboratory results were not included in the analyses. Therefore, it is necessary to develop an effective classifier model for predicting disease progression at an early stage. Machine-learning techniques provide new methods for predicting clinical outcomes and assessing risk factors. Here, we aimed to predict the disease’s progression with machine learning, based on a large set of clinical and laboratory features. Performance of the models was evaluated using clinical data of multicenter-confirmed COVID-19 patients. Software was developed for clinical practice. These predictive models can identify patients at high risk of disease progression and predict the prognosis of COVID-19 patients accurately.
Methods
Patients and Data Collection
This retrospective multicenter cohort study was performed at Huoshenshan Hospital and Taikang Tongji Hospital (Wuhan, China). Diagnostic criteria for COVID-19 followed the 2020 WHO interim guidance.11 Severe COVID-19 cases were defined as patients with fever plus one of respiratory rate >30 breaths/minute, severe respiratory distress, or SpO2 ≤93% in room air. All severe cases included had progressed from nonsevere cases. Adults with pneumonia but no signs of severe pneumonia and no need for supplemental oxygen were defined as nonsevere. All nonsevere cases study were stable and had been discharged. RT-PCR assays of nasal and pharyngeal swab specimens were performed for laboratory confirmation of SARS-CoV2 virus.
Data of COVID-19 patients were collected from February 10, 2020 to April 5, 2020. A total of 29 features of laboratory data obtained on admission to hospital (within 6 hours) are shown in Supplementary Table 1. This study was approved by the ethics committee of Huoshenshan Hospital (HSSLL024). As all subjects were anonymized in this retrospective study, written informed consent was waived due to urgent need. This study was conducted in accordance with the Declaration of Helsinki.
Study Design
A feature selection process was employed to incrementally choose the most representative features. The features with significant difference between two groups were selected for the following machine learning process. The combination training–validation set was collected from Huoshenshan Hospital, and two test sets were collected from Huoshenshan Hospital and TaikangTongji Hospital, respectively.
To prevent overfitting and improve generalizability, k-fold cross-validation was used. Since training and validation data were randomly generated, we took the average score of five rounds of k-fold cross-validation as the final validation results. The optimal-feature subsets in each model were defined as those with the highest AUC values. The flow diagram of training, validation, and test of the prediction models is shown in Figure 1.
 |
Figure 1 Flow diagram of training, validation, and testing of the prediction models. |
Machine-Learning Models
Four prediction models were trained with logical regression (LR), support vector-machine(SVM), k–nearest neighbor (KNN), and naïve Bayes (NB), respectively. Experiments were implemented using MatLab 2018. ROC curve, AUC value, sensitivity, and specificity were used to evaluate predictive performance. The prediction tasks in this work mean classification.
Software for predicting disease progression of COVID-19 was developed based on machine learning, which is convenient for clinicians to use. The interface of the software is written in Visual Studio 2013 and the internal function in MatLab 2018.
Statistical Analysis
Statistical analyses were performed using SPSS 23.0. Categorical data are expressed as proportions. Descriptive data are expressed as medians and interquartile ranges for skewed-distribution variables and means ± SD for variables with normal distribution. Student’s t-tests and nonparametric Mann–Whitney tests were used to compare normal- and skewed-distribution variables, respectively. Pearson’s χ2 was used to compare categorical variables and multiple rates. Two-sided α<0.05 was considered statistically significant.
Results
Demographic and Clinical Characteristics
By April 5, 2020, 1,567 COVID-19 patients in the medical record systems of Huoshenshan Hospital and Taikang Tongji Hospital had been screened for data collection. Data from 455 patients (347 from Huoshenshan, 108 from Taikang Tongji) with complete medical information and laboratory-examination results were collected. In sum, 78 patients from Huoshenshan were randomly selected as test set 1 (30 severe cases and 48 nonsevere cases) and 108 patients from Taikang Tongji as test set 2 (40 severe cases and 68 nonsevere cases). Data of the remaining 269 patients from Huoshenshan were used for the training and validation set (101 severe cases and 168 nonsevere cases). Demographic and clinical characteristics of the 269 patients in the training–validation set are summarized in Table 1, and clinical characteristics of patients in test sets 1 and 2 are summarized in Supplementary Table 2 and 3, respectively.
 |
Table 1 Demographic and clinical characteristics of COVID–19 patients in training and validation sets |
The median age of the patients in training and validation set was 62.75 years, and 51% of the patients were men. Severe patients were much older than nonsevere patients (71.31 vs 57.61, P<0.05). Comorbidities were present in 55% of patients (147–270), and the prevalence of comorbidities in severe patients was higher than that in nonsevere patients (73% vs 45%, P<0.05). Hypertension (32%), diabetes (13%), and coronary heart disease (9%) were the most common comorbidities, and presented more frequently in severe patients: 26% of patients overall had two or more comorbidities, while severe patients had higher prevalence of two or more comorbidities (52% vs 15%, P<0.05). Fever (68%), cough (49.4%), and fatigue (45%) were the most common symptoms at onset of illness, and fever and fatigue were present more frequently in severe patients (Table 1).
Severe patients had elevated levels of CRP, lactate dehydrogenase (LDH), D-dimer, and α-hydroxybutyrate dehydrogenase, and had reduced levels of hemoglobin, hematocrit, and albumin (Table 1). Features with significant differences between the groups were introduced for selection using machine learning.
Predictive Performance of Machine-Learning Models in Validation Set
A total of 21 features with significant difference between the training and validation sets were used for the following modeling (Supplementary Table 4). The subset with the highest AUC was selected to be the optimal subset of the corresponding machine-learning method (Table 2). Briefly, KNN achieved the highest AUC (0.9484, 95% CI 0.924–0.973) among the eleven features of the four methods in training and validation sets (Table 2). D-dimer was the single optimal feature with the highest AUC in the optimal-feature subset of each machine-learning method (0.8368 in LR model, 0.8169 in NB model, 0.8343 in KNN model, and 0.8322 in SVM model, respectively; Supplementary Table 5). ROC curves obtained by the optimal-feature subsets, single features, and all features using k-fold cross-validation are shown in Figure 2. Highest AUC values in optimal-feature subsets were 0.937, 95% CI 0.902–0.972) for LR, 0.949 (95% CI 0.924–0.973) for KNN, 0.935 (95% CI 0.906–0.964) for NB, and 0.931 (95% CI 0.895–0.967) for SVM (Table 3).
 |
Table 2 Optimal-feature subset of each machine learning method |
 |
Table 3 Comparison of the average predictive performance by k-fold cross-validation with optimal-feature subset |
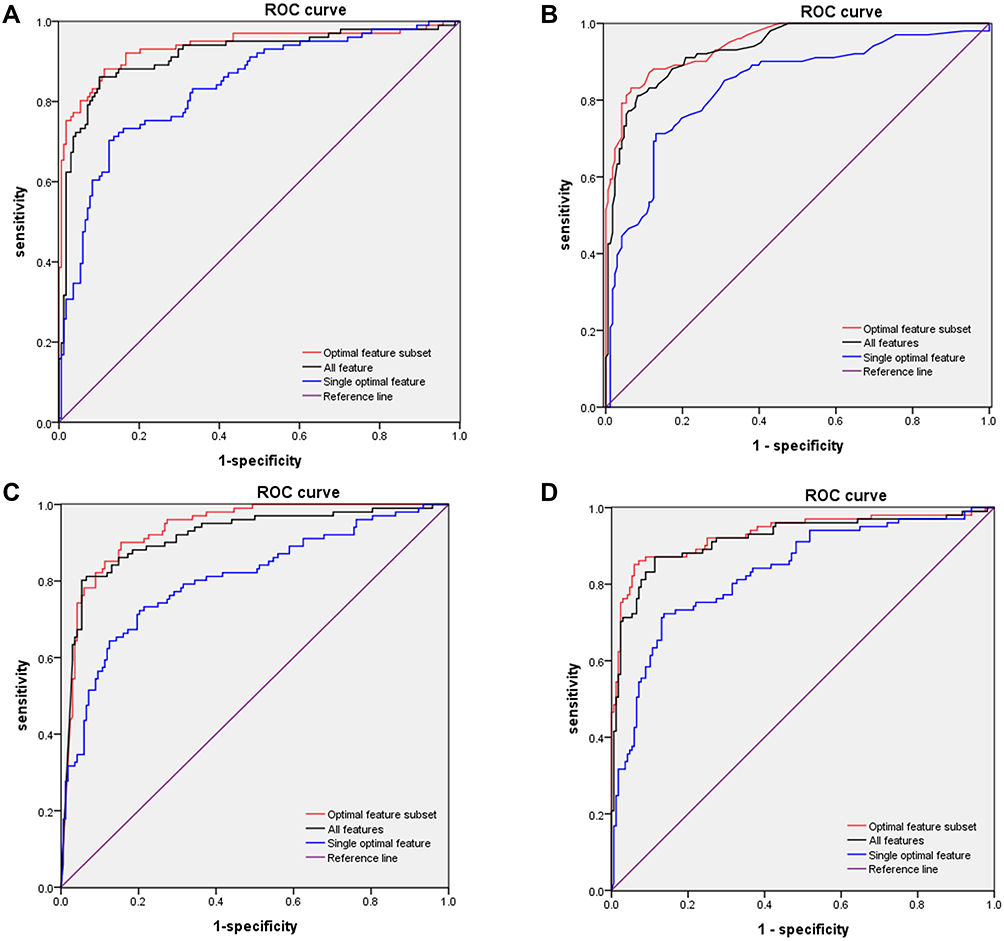 |
Figure 2 ROC curves for models in training and validation sets. (A) ROC curves of LR subsets for distinguishing between severe and nonsevere patients. AUC of optimal-feature subset 0.937 (95% CI 0.902–0.927), all features 0.916 (95% CI 0.876–0.955), and single optimal feature (D-dimer) 0.837 (95% CI 0.786–0.887). (B) ROC curves for subsets of features from KNN for distinguishing between severe and nonsevere patients. AUC of the optimal feature subset 0.948 (95% CI 0.924–0.937), all features 0.935 (95% CI 0.907–0.963), and single optimal feature (D-dimer) 0.835 (95% CI 0.782–0.887). (C) ROC curves of subsets of features from NB for distinguishing between severe and nonsevere patients. AUC of optimal feature set 0.935 (95% CI 0.906–0.964), all features 0.916 (95% CI 0.879–0.954), and single optimal feature (D-dimer) 0.805 (95% CI 0.748–0.861). (D) ROC curves of subsets of features from SVM for distinguishing between severe and nonsevere patients. AUC of optimal feature subset 0.931 (95% CI 0.895–0.967), features 0.918 (95% CI 0.879–0.957), and single optimal feature (D-dimer) 0.832 (95% CI 0.781–0.884). |
We compared predictive performance obtained by the models based on the optimal-feature subsets. Sensitivity (Sen), specificity (Spe), false-positive rate (FPR), false-negative rate (FNR), positive predictive value (PPV), negative predictive value (NPV), accuracy, and F1 scores of the above four models are shown in Table 3. No significant differences were observed among these four models for Sen, FNR, PPV, NPV, or accuracy. Spe, FPR, and F1 scores for SVM were superior (Table 3).
Predictive Performance of Each Feature of Optimal Subsets in Validation Set
To evaluate the importance of each feature in the corresponding optimal subsets, we evaluated predictive performance based on AUC obtained by each feature in the subsets. D-dimer, CRP, age, white blood cell (WBC) count, LDH, and albumin showed the highest predictive performance in the optimal subsets, with D-dimer, CRP, and age the top three (Supplementary Table 5).
Predictive Performance of Machine-Learning Models in Test Sets
Test set 1 comprised 78 patients from Huoshenshan, and test set 2 108 patients from Taikang Tongji. AUC values obtained by the four models in test set 1 were 0.9059 (95% CI 0.832–0.980) for LR, 0.9139 (95% CI 0.841–0.987) for KNN, 0.9177 (95% CI 0.848–0.988) for NB, and 0.9594 (95% CI 0.920–0.999) for SVM. F1 scores of the four models in test set 1 were 0.818 for LR, 0.828 for KNN, 0.867 for NB, and 0.885 for SVM (Supplementary Table 6). ROC curve obtained for the models in test set 1 are shown in Figure 3A. No significant differences were observed among these models for Sen, Spe, FPR, FNR, PPV, NPV, or accuracy (Supplementary Table 6). The predictive performance of all models was satisfied in test set 1. Then, to test whether these models would still work at another hospital, we evaluated predictive performance in test set 2. AUC values of the four models in test set 2 were 0.8143 (95% CI 0.728–0.901) for LR, 0.8057 (95% CI 0.717–0.894) for KNN, 0.8265 (95% CI 0.741–0.912) for NB, and 0.8140 (95% CI 0.728–0.900) for SVM. F1 scores of the four models in test set 2 were 0.676 for LR, 0.698 for KNN, 0.716 for NB, and 0.691 for SVM (Supplementary Table 7). ROC curves obtained by the four models in test set 2 are shown in Figure 3 (Figure 3B). No significant differences were observed among these four models for Sen, Spe, FPR, FNR, PPV, NPV, or accuracy P>0.05, Supplementary Table 7).
 |
Figure 3 ROC curves of models in testing sets. (A) Optimal-feature set of LR, KNN, NB, and SVM in test set 1. (B) Optimal feature set of LR, KNN, NB, and SVM in test 2. (C) Optimal-feature set of LR, KNN, NB, and SVM in the mixed test sets. (D) AUC values of optimal-feature subsets for different models in test set 1, test set 2, and mixed test set. |
To explore potential reasons for differences between the two test sets, we randomly selected 54 patients from test set 2 (Taikang Tongji), and added their data to the training–validation set. The remaining data from test sets 2 and 1 were combined (from Huoshenshan). As such, data from 323 patients were used as the training–validation set, and data from 132 patients were used as mixed test set. AUC values obtained by the four models were 0.8843 (95% CI 0.823–0.946) for LR, 0.8561 (95% CI 0.786–0.926) for KNN, 0.9096 (95% CI 0.853–967) for NB, and 0.9255 (95% CI 0.882–0.969) for SVM in the mixed test set. F1 score of the four models in the mixed test set were 0.777 for LR, 0.750 for KNN, 0.840 for NB, 0.832 for SVM, respectively (Supplementary Table 8). ROC curves obtained by the four models in test set 2 are shown in Figure 3C. The predictive performance of the models in the mixed test set was much better than that in test set 2 (Figure 3D).
Development of Software for Predictive Models
Software was developed for predicting disease progression based on machine learning for clinical practice (Supplementary Figure 1, 2, and 3). The first page provided the function of training and validation using k-fold cross-validation to select the optimal-feature subset and parameters (Supplementary Figure 1). In second page, one model that has been trained can be easily selected, and predictive performance can be evaluated in test sets (Supplementary Figure 2). Once the validity of the trained model has been confirmed by the second page, a prediction probability wil emerge for an upcoming patient on the third page (Supplementary Figure 3).
Discussion
We developed a prediction model of disease progression based on machine learning. Clinical characteristics, WBC count, inflammatory markers, liver function, renal function, and coagulation functions were collected and utilized to establish the predictive model based on machine learning. In sum, 21 features with significant differences between the severe and nonsevere groups were selected from a total of 48 features. In this feature-selection process, relatively useless features were eliminated to make the calculation more effective. Finally, the optimal-feature subset was determined using k-fold cross validation for each method. Moreover, the predictive performance of the models was evaluated by two test sets from two hospitals, and AUC values in these test sets were satisfactory. We also developed software to predict disease progression of COVID-19 based on machine learning that can be used conveniently in clinical practice.
Clinical features of the patients in this study were consistent with previous large-sample studies.3,12 Comorbidity, older age, lower lymphocyte count, and higher LDH were identified as independent high-risk factors for COVID-19 disease progression.13 Ji et al developed a risk factor–scoring system (CALL) based on these features to predict disease progression.13 However, there were few cases included, and the reliability of the model needs to be confirmed. In our study, these models were trained by optimal-feature subsets to attain optimal predictive performance. We evaluated predictive performance with two test sets from two hospitals to ensure the reliability of the models.
D-dimer, CRP, age, WBC count, LDH, and albumin had better predictive performance in the optimal-feature subset, with D-dimer, CRP, and age the top three. Zhou et al found no significant differences between a nonaggravation group and aggravation group for WBC count, CRP, albumin, LDH, or D-dimer level.10 They found that total lymphocyte count was a risk factor associated with disease progression in COVID-19 patients using a binary logistic regression model.10 However, only 17 patients were included in this study, and total lymphocyte count did not reflect disease progression. Zhou et al showed that older age and elevated D-dimer could help clinicians to identify patients with poor prognosis at an early stage.6 Consistently with this study, age and D-dimer level were important features in the optimal-feature subset. Elevated levels of D-dimer are associated with disease activity and inflammation, mainly including venous thromboembolism, sepsis, or cancer.14,15 A retrospective study on deceased patients also showed that D-dimer was markedly higher in deceased patients than recovered patients.16 Therefore, monitoring the D-dimer levels can help clinicians identify patients at high risk of disease progression. Anticoagulation treatment can be given patients with high D-dimer levels to prevent disease progression. Albumin levels decrease significantly in most severe COVID-19 patients and decrease continuously during the disease’s progress.17 Hypoalbuminemia is associated with poor clinical outcomes for hospitalized patients.18,19 Hypoalbuminemia in severe patients is mainly due to inadequate nutrition intake and overconsumption.
The predictive performance of the models in test set 1 was much better than that in test set 2. and patients enrolled in test set 2 were from another hospital. Differences in laboratory findings and medical services may be potential reasons for the lower predictive performance in test set 2. After data from Taikang Tongji had been added to this training set, predictive performance improved significantly, indicating that predictive performance in another hospital could be improved if part of the data collected from another hospital participated in the training stage.
Code Availability
The code of the software used in this study is available from the corresponding author on reasonable request.
Data Sharing Statement
The data sets used in this study are available from the corresponding author — Kaijun Liu (email [email protected]) on reasonable request.
Ethics Approval
This study was approved by the ethics committee of Huoshenshan Hospital (Wuhan, China) (HSSLL024).
Informed Consent
As all subjects were anonymized in this retrospective study, written informed consent was waived due to urgent need.
Author Contributions
All authors made substantial contributions to conception and design, acquisition of data, or analysis and interpretation of data, took part in drafting the article or revising it critically for important intellectual content, agreed to submit to the current journal, gave final approval to the version to be published, and agree to be accountable for all aspects of the work.
Funding
This work was supported by the National Natural Science Foundation of China (81700483), Chongqing Research Program of Basic Research and Frontier Technology (cstc2017jcyjAX0302, cstc2020jcyj-msxmX1100), and Army Medical University Frontier Technology Research Program (2019XLC3051). The funders of the study had no role in study design, data collection, data analysis, data interpretation, or writing of the report. The corresponding authors had full access to all the data in the study, and had final responsibility for the decision to submit for publication.
Disclosure
The authors declare that there are no conflicts of interest.
References
1. World Health Organization. Weekly epidemiological update - 24 November 2020. Available from: https://www.who.int/publications/m/item/weekly-epidemiological-update---24-november-2020.
2. Lu R, Zhao X, Li J, et al. Genomic characterisation and epidemiology of 2019 novel coronavirus: implications for virus origins and receptor binding. Lancet. 2020;395(10224):565–574. doi:10.1016/S0140-6736(20)30251-8
3. Huang C, Wang Y, Li X, et al. Clinical features of patients infected with 2019 novel coronavirus in Wuhan, China. Lancet. 2020;395(10223):497–506. doi:10.1016/S0140-6736(20)30183-5
4. Chen N, Zhou M, Dong X, et al. Epidemiological and clinical characteristics of 99 cases of 2019 novel coronavirus pneumonia in Wuhan, China: a descriptive study. Lancet. 2020;395(10223):507–513. doi:10.1016/S0140-6736(20)30211-7
5. Sun Y, Koh V, Marimuthu K, et al. Epidemiological and clinical predictors of COVID-19. Clin Infect Dis. 2020;71(15):786–792. doi:10.1093/cid/ciaa322
6. Zhou F, Yu T, Du R, et al. Clinical course and risk factors for mortality of adult inpatients with COVID-19 in Wuhan, China: a retrospective cohort study. Lancet. 2020;395(10229):1054–1062. doi:10.1016/S0140-6736(20)30566-3
7. Guan WJ, Liang WH, Zhao Y, et al. Comorbidity and its impact on 1590 patients with Covid-19 in China: a nationwide analysis. Eur Respir J. 2020;55(5):2000547. doi:10.1183/13993003.00547-2020
8. Wang L, He W, Yu X, et al. Coronavirus Disease 2019 in elderly patients: characteristics and prognostic factors based on 4-week follow-up. J Infect. 2020;80(6):639–645. doi:10.1016/j.jinf.2020.03.019
9. Wu C, Chen X, Cai Y, et al. Risk factors associated with acute respiratory distress syndrome and death in patients with coronavirus disease 2019 pneumonia in Wuhan, China. JAMA Intern Med. 2020;180(7):934. doi:10.1001/jamainternmed.2020.0994
10. Zhou Y, Zhang Z, Tian J, Xiong S. Risk factors associated with disease progression in a cohort of patients infected with the 2019 novel coronavirus. Ann Palliat Med. 2020. doi:10.21037/apm.2020.03.26
11. World Health Organziation. Clinical management of severe acute respiratory infection when Novel coronavirus (nCoV) infection is suspected: interim guidance. 2020. Available from: https://www.who.int/docs/default-source/coronaviruse/clinical-management-of-novel-cov.pdf.
12. Guan WJ, Ni ZY, Hu Y, et al. Clinical characteristics of coronavirus disease 2019 in China. N Engl J Med. 2020;382(18):1708–1720. doi:10.1056/NEJMoa2002032
13. Ji D, Zhang D, Xu J, et al. Prediction for progression risk in patients with COVID-19 pneumonia: the CALL score. Clin Infect Dis. 2020;71(6):1393–1399. doi:10.1093/cid/ciaa414
14. Borowiec A, Dabrowski R, Kowalik I, et al. Elevated levels of d-dimer are associated with inflammation and disease activity rather than risk of venous thromboembolism in patients with granulomatosis with polyangiitis in long term observation. Adv Med Sci. 2020;65(1):97–101. doi:10.1016/j.advms.2019.12.007
15. Schutte T, Thijs A, Smulders YM. Never ignore extremely elevated D-dimer levels: they are specific for serious illness. Neth J Med. 2016;74(10):443–448.
16. Chen T, Wu D, Chen H, et al. Clinical characteristics of 113 deceased patients with coronavirus disease 2019: retrospective study. BMJ. 2020;368:m1091. doi:10.1136/bmj.m1091
17. Zhang Y, Zheng L, Liu L, Zhao M, Xiao J, Zhao Q. Liver impairment in COVID-19 patients: a retrospective analysis of 115 cases from a single center in Wuhan city, China. Liver Int. 2020;40(9):2095–2103. doi:10.1111/liv.14455
18. Kim S, McClave SA, Martindale RG, Miller KR, Hurt RT. Hypoalbuminemia and clinical outcomes: What is the mechanism behind the relationship? Am Surg. 2017;83(11):1220–1227. doi:10.1177/000313481708301123
19. Yanagisawa S, Miki K, Yasuda N, Hirai T, Suzuki N, Tanaka T. Clinical outcomes and prognostic factor for acute heart failure in nonagenarians: impact of hypoalbuminemia on mortality. Int J Cardiol. 2010;145(3):574–576. doi:10.1016/j.ijcard.2010.05.061
 © 2021 The Author(s). This work is published and licensed by Dove Medical Press Limited. The
full terms of this license are available at https://www.dovepress.com/terms
and incorporate the Creative Commons Attribution
- Non Commercial (unported, 3.0) License.
By accessing the work you hereby accept the Terms. Non-commercial uses of the work are permitted
without any further permission from Dove Medical Press Limited, provided the work is properly
attributed. For permission for commercial use of this work, please see paragraphs 4.2 and 5 of our Terms.
© 2021 The Author(s). This work is published and licensed by Dove Medical Press Limited. The
full terms of this license are available at https://www.dovepress.com/terms
and incorporate the Creative Commons Attribution
- Non Commercial (unported, 3.0) License.
By accessing the work you hereby accept the Terms. Non-commercial uses of the work are permitted
without any further permission from Dove Medical Press Limited, provided the work is properly
attributed. For permission for commercial use of this work, please see paragraphs 4.2 and 5 of our Terms.