Back to Journals » Clinical Epidemiology » Volume 15
Development and Validation of Coding Algorithms to Identify Patients with Incident Non-Small Cell Lung Cancer in United States Healthcare Claims Data
Authors Beyrer J ![]() , Nelson DR, Sheffield KM, Huang YJ, Lau YK, Hincapie AL
, Nelson DR, Sheffield KM, Huang YJ, Lau YK, Hincapie AL
Received 14 September 2022
Accepted for publication 23 December 2022
Published 12 January 2023 Volume 2023:15 Pages 73—89
DOI https://doi.org/10.2147/CLEP.S389824
Checked for plagiarism Yes
Review by Single anonymous peer review
Peer reviewer comments 3
Editor who approved publication: Professor Lars Pedersen
Julie Beyrer,1,* David R Nelson,1,* Kristin M Sheffield,1,* Yu-Jing Huang,1,* Yiu-Keung Lau,1,* Ana L Hincapie2,*
1Eli Lilly and Company, Indianapolis, IN, USA; 2University of Cincinnati James L. Winkle College of Pharmacy, Cincinnati, OH, USA
*These authors contributed equally to this work
Correspondence: Julie Beyrer, Eli Lilly and Company, Lilly Corporate Center, Indianapolis, IN, 46285, USA, Tel +1 317 651 8236, Email [email protected]
Purpose: We sought to develop and validate an incident non-small cell lung cancer (NSCLC) algorithm for United States (US) healthcare claims data. Diagnoses and procedures, but not medications, were incorporated to support longer-term relevance and reliability.
Methods: Patients with newly diagnosed NSCLC per Surveillance, Epidemiology, and End Results (SEER) served as cases. Controls included newly diagnosed small-cell lung cancer and other lung cancers, and two 5% random samples for other cancer and without cancer. Algorithms derived from logistic regression and machine learning methods used the entire sample (Approach A) or started with a previous algorithm for those with lung cancer (Approach B). Sensitivity, specificity, positive predictive values (PPV), negative predictive values, and F-scores (compared for 1000 bootstrap samples) were calculated. Misclassification was evaluated by calculating the odds of selection by the algorithm among true positives and true negatives.
Results: The best performing algorithm utilized neural networks (Approach B). A 10-variable point-score algorithm was derived from logistic regression (Approach B); sensitivity was 77.69% and PPV = 67.61% (F-score = 72.30%). This algorithm was less sensitive for patients ≥ 80 years old, with Medicare follow-up time < 3 months, or missing SEER data on stage, laterality, or site and less specific for patients with SEER primary site of main bronchus, SEER summary stage 2000 regional by direct extension only, or pre-index chronic pulmonary disease.
Conclusion: Our study developed and validated a practical, 10-variable, point-based algorithm for identifying incident NSCLC cases in a US claims database based on a previously validated incident lung cancer algorithm.
Keywords: algorithm, machine learning, medicare claims, non-small cell lung cancer, positive predictive value, sensitivity, validation
Introduction
Validated algorithms are essential research tools for identifying patient cohorts, exposures, key covariates, and outcomes in real-world data.1 The accurate identification of patient diagnoses in real-world data sources, such as administrative healthcare databases, is essential for learning about patient disease experiences. For example, validated disease cohort and outcome algorithms can support earlier diagnosis of disease or better screening efforts (eg, by enabling research on predictors of those diagnoses). This is an important consideration for diseases that are currently diagnosed after the disease has progressed to a more serious or advanced stage and the prognosis is poor. Lung cancers are often diagnosed at an advanced stage,2 despite recommendations by the United States (US) Preventive Services Task Force for low-dose computed tomography (LDCT) in at-risk adults.3 Lung cancer is a heterogenous disease. Most lung cancers in the US are non-small cell lung cancer (NSCLC; 80% to 85%), which originate in different types of cells and have a different prognosis and prescribed treatments than other types of lung cancer.4 NSCLC includes the main subtypes of adenocarcinoma, squamous cell carcinoma, and large cell carcinoma, which are classed together as NSCLC because of the similarity of their treatment and prognoses. In contrast, small cell lung cancer (SCLC) tends to grow and spread faster than NSCLC. Consequently, the ability to differentiate NSCLC from other types of lung cancers in real-world data sources is important to enable research on NSCLC diagnosis, comorbidities, treatment patterns, adverse effects, prognosis, healthcare costs and resource utilization.
However, directly identifying NSCLC in administrative healthcare databases in the US is not feasible. The diagnostic coding system used in these databases (the International Classification of Diseases [ICD], Clinical Modification) categorizes cancers according to site of origin rather than pathologic characteristics and it cannot be used to differentiate NSCLC from other types of lung cancer. Other healthcare practices contribute to disease misclassification in these administrative healthcare databases, such as differing interpretations of coding guidelines by medical coders,5,6 partial and misclassified clinical data, and incomplete claims that are not paid on a fee-for-service basis.7
A linked data source (eg, registry data source linked with claims, such as the Surveillance, Epidemiology, and End Results [SEER]-Medicare database) can supplement clinical details in medical claims. When linked data sources are not available, validated claims-based algorithms provide an alternative for identifying clinical conditions in claims. Various analytical methods for building algorithms, such as single classification trees and random forests, can be used to identify patients with cancer.8–10
An algorithm to identify patients with NSCLC in administrative claims databases in the US was developed and validated by Turner and colleagues.11 However, the algorithm criteria included medications for treating NSCLC, which may not be stable indicators over time as the NSCLC treatment landscape is quickly evolving. In some cases, algorithms that include medication(s) may not be generalizable and re-useable in other healthcare administrative data sources if data on the medication(s) are systemically missing. Medication data may be systemically missing if the medication(s) are not covered by the health plan’s formulary or if a medication-specific code does not exist during the study timeframe. For example, Healthcare Common Procedure Codes (HCPC) are submitted by healthcare providers on medical claims to obtain reimbursement for medications administered; data may be missing for HCPC-coded medications in some medical claims datasets if those data are pulled before the medical claim has been processed (HCPC-coded medications in medical claims take longer for health plans to process or adjudicate than medications submitted for reimbursement on pharmacy claims and thus may not appear in the data source). The delayed issuance and effective dates of HCPC codes in the US have also historically limited a researcher’s ability to identify medications in medical claims data sources during certain periods (approximately one to two years after a medication’s approval by the United States Food and Drug Administration), although recent improvements to the HCPCS coding application process may offer shorter timeframes between new medication approval and issuance of a HCPC.12 Algorithms that use medications to identify cases (patients with disease) are also not ideal because they may preclude the study of real-world treatment patterns (if the cohort has been defined by treatment) or may result in selection bias. For example, older patients with NSCLC or those with comorbidities may be less likely to receive treatment13,14 and therefore systematically being excluded from the study.
The objective of our study was to develop and validate an algorithm for identifying incident NSCLC cases in US healthcare claims data. The development process avoided the use of medications and incorporated diagnostic and procedural codes and other concepts that are less likely to change over time or be missing in administrative healthcare data. This supports the long-term relevance and reliability of the algorithm.
Materials and Methods
Data Sources
We used the SEER registry linked with Medicare claims data (2004 to 2012). Full details of the data source used in this study were published previously.15 The protocol was reviewed and considered exempt by the Quorum Review institutional review board prior to approval by the National Cancer Institute for SEER-Medicare data use.
Study Populations
Patients with newly diagnosed (incident) NSCLC per SEER served as cases. Controls included newly diagnosed (incident) small-cell lung cancer (SCLC) and other lung cancers, a 5% random sample of patients with other cancers (the majority were colorectal, female breast, and prostate cancers), and a 5% random sample of individuals without cancer. Patients in the incident NSCLC cohort were required to have a primary diagnosis of NSCLC (SEER histology codes are shown in Figure 1) and behavior code = 3 (malignant) during the index period (January 1, 2005 through December 31, 2011; the full study period was January 1, 2004 through December 31, 2012). Medicare coverage typically starts at age 65, so patients were required to be 66 years or older at SEER initial lung cancer diagnosis date to help ensure ≥1 year of pre-index diagnosis data would be available for constructing the algorithm.16
 |
Figure 1 Attrition of cohorts of lung cancer, other cancer, and non-cancer cohorts from SEER-Medicare. Abbreviations: HMO, health maintenance organization; NSCLC, non-small cell lung cancer; PEDSF, Patient Entitlement and Diagnosis Summary; SEER, Surveillance, Epidemiology, and End Results. Notes: A primary diagnosis of NSCLC included SEER histology codes in these ranges: 8003–8004, 8012–8015, 8021–8022, 8030–8035, 8046, 8050–8052, 8070–8076, 8078, 8082–8084, 8090, 8094, 8120, 8123, 8140–8141, 8143–8145, 8147, 8190, 8200–8201, 8211, 8240–8241, 8243–8246, 8249–8255, 8260, 8290, 8310, 8320, 8323, 8333, 8401, 8430, 8440, 8470–8471, 8480–8481, 8490, 8503, 8507, 8525, 8550, 8560, 8562, 8570–8572, 8574–8576. |
Patients who were diagnosed by autopsy or death certificate only or who were missing a SEER diagnosis date for lung cancer were excluded. Evidence of Medicare Parts A&B enrollment was also required from ≥1 year pre-index until death or one-year post index, whichever was first. The initial SEER documented date (month/year) of diagnosis was utilized for inclusion of patients in the incident NSCLC cohort. The same criteria that applied to the initial SEER lung cancer diagnosis date were used to identify incident SCLC and other lung cancer case controls. A randomly assigned date for each individual between January 1, 2005 and death or end of the index period (December 31, 2011) was utilized to select controls for the 5% other cancers and 5% non-cancer cohorts.
Model Building and Validation Subsets
The full dataset was randomly split into model building and validation subsets of 50% each (if total was an odd number, one more observation was included in the model building subset), with selection stratified by cohort (lung cancer, other cancer, non-cancer). The model building subset was used to extensively build models (eg, to identify significant interactions using multivariate adaptive regression splines methods) and construct models/algorithms. The model validation subset was reserved to obtain unbiased estimates of algorithm performance. Candidate variables were chosen based on clinical practice guidelines (eg, National Comprehensive Cancer Network)17 and observed frequencies of variables for cases and controls, as well as consultation with experts. The algorithms were constructed using the initial ICD, Ninth Revision, Clinical Modification (ICD-9-CM) diagnosis code for lung cancer (162.2–162.9) to create one-year pre-index and post-index periods for NSCLC and other lung cancer cohorts. The randomly assigned Medicare date was used for the other cancer and non-cancer individuals. We searched for candidate variables in the pre- and post-index periods in Medicare claims. Based on the algorithms that performed best in our previous study,15 the following models were explored in this study: a single logistic regression model, a single logistic regression model with interactions, gradient boosting, and neural networks. The multilayer perceptron neural network had two hidden layers in the network and two neurons in each hidden layer because five hidden nodes did not improve the F-score in the model building set. The maximum number of iterations (weight adjustments) for the optimizer to make before terminating was set at 1000, and every fourth observation was a model tuning observation.
Our reference standard was the type of lung cancer as identified by SEER. However, the National Cancer Institute estimates that approximately 4.5% of SEER data could not be linked to Medicare claims (personal communication); therefore, some patients with lung cancer could have inadvertently been delivered in the 5% random non-cancer sample. We observed that 688 (0.3%) of the reference standard “non-cancer” patients had 34+ days of ICD-9-CM codes for lung cancer in Medicare claims. We re-categorized some of these individuals as lung cancer cases, similar to that done by Nattinger and colleagues,16 which resulted in 193 patients being re-categorized from non-cancer to lung cancer in this study. Although these patients were included as lung cancer cases in the previous study,15 they were excluded from this study. This was necessary since they were not in the SEER registry and did not have information on lung cancer type. These patients could also not be included as controls since they were likely to be cases.
Algorithm Development
Two approaches were used to develop the NSCLC algorithms. The algorithm in Approach A was built based on the entire sample, designating patients with NSCLC as cases and patients with other types of lung cancer, other cancers, and no cancer as controls. Approach B was a two-step process that applied a previously validated lung cancer algorithm15 to identify patients with lung cancer in the sample and then designated patients as cases and controls as outlined in Approach A.
We also explored the impact of using or not using medication indicators (eg, exclusion of chemotherapies typically indicated for SCLC during this time period [cyclophosphamide, doxorubicin, irinotecan, vincristine, or topotecan]) for identifying NSCLC.
Statistical Analysis
Sensitivity, specificity, positive predictive values (PPV), negative predictive values (NPV), and F-scores (the product of sensitivity and PPV multiplied by two and divided by the sum of sensitivity and PPV) were calculated in the model building and validation subsets. Due to over-representation (enriched prevalence) of patients with lung cancer in the study sample, PPVs and NPVs were calculated using Bayes' theorem.15,16 Here, Bayes' theorem values were: for NSCLC (0.29%; or 73.7%, based on SEER, of the 0.40% lung cancer rate), other lung cancer (the remaining 0.11%), other cancer (7.3%), and non-cancer (92.2%) for Approach A and Approach B.
Four algorithm types were evaluated in the validation subset, and logistic regression models were repeated to explore models including and excluding medications/chemotherapy variables. A simplified point score was created by reducing the number of variables in the logistic model feature selection,18 then with forward selection to stop at 10 variables. The coefficients of the 10 variable model were converted to points by dividing each by the absolute value of the smallest coefficient and rounding to the nearest integer, as described in risk scores, such as Framingham19 and others.20 Bootstrap samples of the validation dataset were selected 1000 times for one-tailed p-values to test each algorithm vs the point score based on 10 variables.
Univariate and multivariable logistic regression analyses were performed separately within two groups (NSCLC and non-NSCLC patients) to determine the association of variables with sensitivity and specificity. For the univariate analyses, false discovery rate p-values were used to assess significance. A multivariable logistic model was generated by using feature selection of the variables in the univariate analysis, followed by forward model selection. For both the sensitivity and specificity models, forward selection was stopped when the model’s area under the receiver operating characteristic curve was within 1% of a larger stepwise model. A version of number needed to treat (NNT) was calculated to indicate how many patients within a subgroup that had reduced either sensitivity or specificity would result in one additional false negative or false positive, respectively. The purpose of the NNTs was to illustrate the impact of these significant variables.
Summary statistics are presented as mean (standard deviation) or percentage. All computations used SAS software version 9.4 (SAS Institute Inc., Cary, NC, USA).
Results
The cohort attrition in the SEER-Medicare dataset is displayed (Figure 1).
The non-NSCLC lung cancer cohort was comprised of individuals with SCLC (n = 16,871 [44.7%]) and other lung cancer (n = 20,888 [55.3%]). Characteristics of the SEER-Medicare cohorts, including a summary of demographics and components of the final point-based score algorithm, are shown in Table 1. Mean cohort ages ranged from 76 to 78 years, and the majority (>80%) of patients were White. Male sex was less frequent in the non-cancer cohort (38%), equally distributed among the other control groups, and slightly more frequent in the NSCLC cohort (53%). A descriptive summary of the cohorts based on all candidate variables used to build the algorithms in this study is presented in S1.
 |
Table 1 Characteristics of Demographics, Rates of Lung Cancer Codes, and Components of the Algorithm Developed to Identify Cases (Non-Small Cell Lung Cancer; NSCLC) from Controls (Three Other Surveillance, Epidemiology, and End Results-Medicare Cohorts) |
Model Building Subset
The performance results derived from the model building and validation subsets are summarized in Table 2. In the model building subset, using either Approach A or Approach B, the best performing algorithm based on F-scores was identified using neural networks. When using Approach B compared to Approach A, the neural networks model PPV increased from 54.37% to 72.36% and the F-score increased from 65.82% to 74.53%. For Approach B, the remaining models had F-scores ranging from 71.57% to 73.89%, indicating Approach B was superior to Approach A in this algorithm measure. The cut point of ≥67% probability of being NSCLC for the logistic regression model optimized the F-score (F = 81.37%) within the subset of lung cancer algorithm-positive patients utilized in Approach B; this model was used to derive the 10-variable point-based score algorithm, which had a maximum F-score with a cutoff of ≥5 points (the point-score algorithm can be found in Table 3; cut points are shown in S2 and the logistic regression model is detailed in S3).
 |
Table 2 Comparison of Methods to Discriminate NSCLC from Medicare Claims Built to Maximize Their F-Score on One-Half of the Data (Model Building), and Applied to the Other Half of the Data (Validation) |
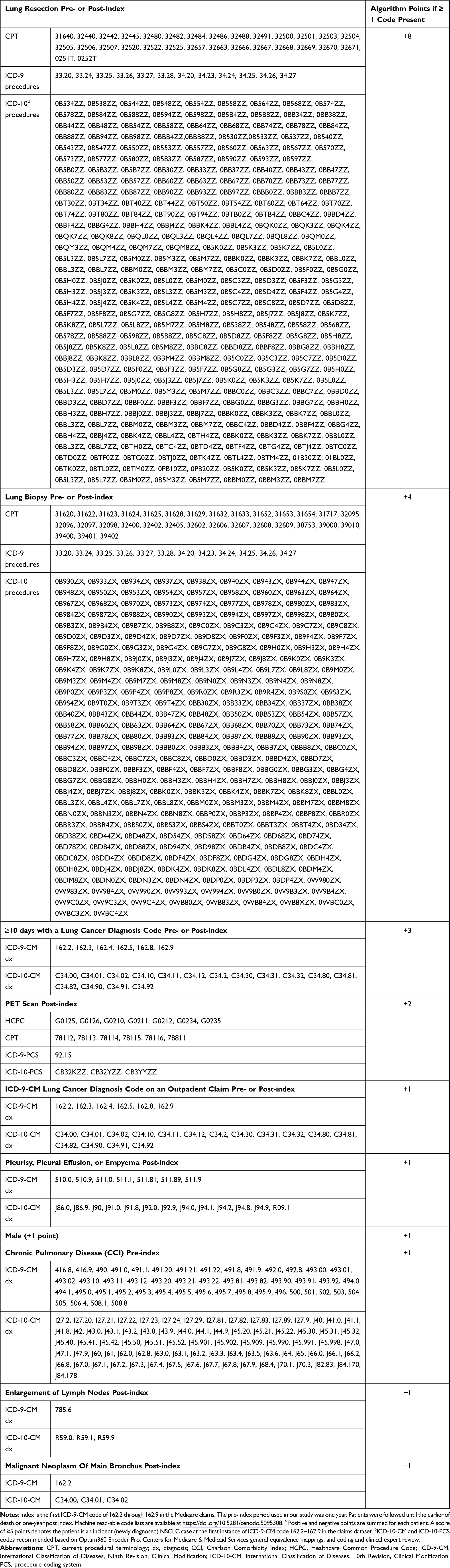 |
Table 3 Point-Based Algorithma (Based on Logistic Regression Equation) with a Recommended Code Set for International Classification of Diseases, 10th Revision, Clinical Modification |
Model Validation Subset
When these algorithms were applied to new patients in the model validation subset, a similar pattern was observed; the best performing algorithm was the neural network model (Table 2). The PPV in the neural networks model increased from 55.42% to 72.32% and the F-score increased from 66.60% to 74.57% when starting with Approach B compared to Approach A. For Approach B, the remaining models had F-scores ranging from 71.99% to 73.75%. In both the model building and validation subsets, the exploratory models based on medication indicators (eg, exclusion of SCLC medications to identify patients with NSCLC) had slightly increased sensitivity and slightly decreased PPV compared with models that did not include medications. The point-based score algorithm using Approach B performed better than all methods that used Approach A. Within Approach B, five algorithms (excluding those with evidence of cyclophosphamide, doxorubicin, irinotecan, vincristine, or topotecan; logistic regression; and machine learning models) performed significantly better than the point score (all p≤0.01; Table 2).
Algorithm Sensitivity and Specificity by Patient Characteristics
Sensitivity and specificity of the point-based algorithm by selected characteristics from the SEER registry are displayed in Tables 4 and 5. In the multivariable analysis, these characteristics were associated with significantly lower odds of cases being selected by the algorithms (ie, lower sensitivity): short follow-up time in Medicare (<3 months); derived American Joint Committee on Cancer (AJCC) stage not applicable; no information concerning laterality; derived AJCC stage IA; age at index ≥80; SEER primary site of lung not otherwise specified; and year of diagnosis (based on SEER) of 2011. The NNT to produce one additional false negative within these subgroups ranged from 3.2 (AJCC stage not applicable) to 11.7 (year 2011).
 |
Table 4 Sensitivity and Specificity of Point-Based Algorithm by Selected Characteristics from the Surveillance, Epidemiology, and End Results Registry: Univariate Logistic Regression Analysis |
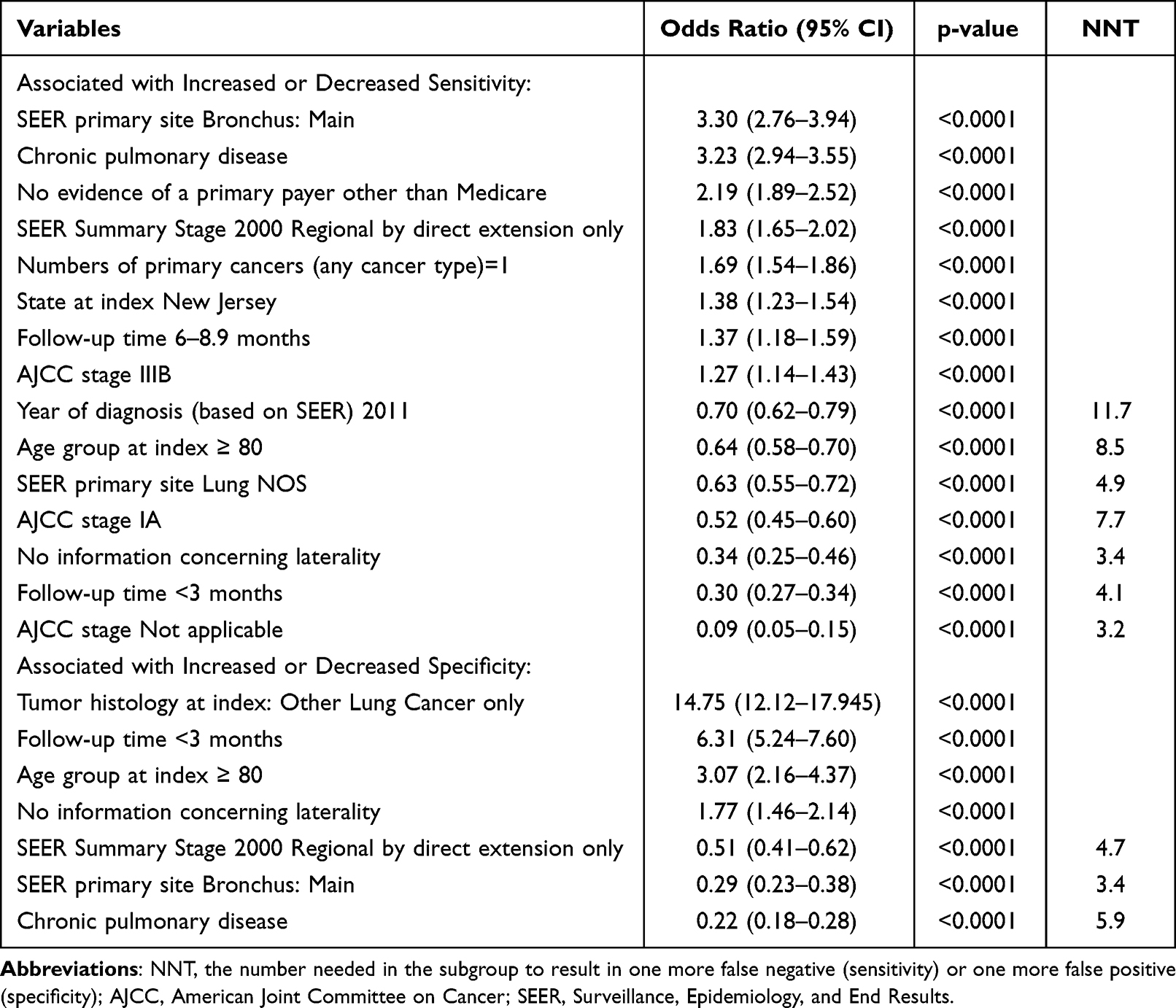 |
Table 5 Sensitivity and Specificity of Point-Based Algorithm by Selected Characteristics from the Surveillance, Epidemiology, and End Results Registry: Multivariable Logistic Regression Analysis |
These characteristics were associated with significantly lower algorithm specificity: chronic pulmonary disease (pre-index Charlson comorbidity), SEER primary site of main bronchus, and SEER summary stage 2000 regional by direct extension only (Table 5). For these subgroups, NNTs ranged from 3.4 (bronchus: main) to 5.9 (chronic pulmonary disease) to produce one additional false positive.
Discussion
The best performing algorithm for identifying incident NSCLC cases was a neural network machine learning model (Approach B). However, machine learning models could not easily be converted to a point-based system for re-use and may pose additional challenges for interpretability,21,22 so the logistic regression models remained the most practical application. Our logistic regression model was reduced from 77 variables to 10 for the point-score algorithm (Approach B) which was considered the most practical algorithm for general future use. Despite the statistically significant better performance of the neural network algorithm, the sensitivity, PPV, and F-score for the point-based algorithm were similar in magnitude (difference in sensitivity = +0.72%, PPV = −4.71%, F-score −2.27%).
Algorithm performance was assessed using the F-score, a composite measure of a model’s precision (PPV) and sensitivity, and we sought to optimize both. Sensitivity and PPV of our final algorithm approached or exceeded levels generally considered acceptable (≥70%),23,24 although this is not an immutable threshold. Depending on the context for the analysis, the thresholds could vary.
Better algorithm performance was observed for all methods when applied after the initial lung cancer algorithm15 (Approach B) vs to the entire sample (Approach A). NSCLC cases were easier to identify from among the patients with lung cancer as selected by the lung cancer algorithm, rather than searching for NSCLC cases without that prior information.
One advantage of the point-score algorithm is that only data from claims are needed to implement it. Some other algorithm validation studies use the reference standard data source (eg, registry or electronic medical record data) as a first algorithm step for identifying cases; this cannot be an algorithm step in real-world practice, however, since other researchers likely do not have access to the registry or electronic medical record reference standard (the reason they are using an algorithm). Our two-step algorithm (Approach B) utilizes only claims data for identifying the patient with NSCLC.
In this study, it was necessary to consider misclassification and bias in both the lung cancer and NSCLC point-score algorithms. The patient characteristics associated with statistically significant reduced sensitivity in the lung cancer algorithm15 (patients ≥80 years, follow-up time in Medicare <3 months, and missing SEER data on stage, laterality, or site) were also observed in the NSCLC algorithm. Some additional characteristics associated with misclassification in the NSCLC algorithm were related to reduced algorithm specificity for site (SEER primary site of bronchus: main), stage (SEER summary stage 2000 of regional by direct extension only), and pre-index chronic pulmonary disease.
We previously described the external generalizability of the lung cancer algorithm.15
A strength of the NSCLC point-score algorithm is face validity of components. The heavy weighted algorithm components (≥2 points) are lung resection, biopsy, unique lung cancer days, and positron emission tomography (PET) scan. These procedures are more likely to be associated with NSCLC than SCLC, based on treatment guidelines.17 For example, when SCLC is disseminated (in most patients at presentation), these patients are often not candidates for resection, may be more frequently biopsied at sites other than lung, and may not have a PET/computed tomography scan performed. These algorithm components and concepts remain relevant, although future work could include evaluating the concepts and/or weights in a more recent dataset (eg, if NSCLC or non-NSCLC cancer stage distribution or diagnostic procedures change).
This study was limited by generalizability to patients in health maintenance organization plans and commercial claims data sources with individuals older than 65 who were not included in this study, as described previously.15 The algorithms in this study relied on ICD-9 diagnoses and procedures. Although more recent US real-world data contain diagnoses coded in ICD-10, these were not yet effectively available in US real-world data at the time of our study. We provided proposed crosswalks to convert ICD-9 to ICD-10 codes for the single-score system (Table 3). The final point-based algorithm criteria did not include personal history of tobacco use (ICD-9-CM V15.82) which is not robustly coded in US administrative healthcare data (eg, if these diagnosis codes are not associated with a reimbursable health procedure to generate a medical claim). Additional information on smoking history (eg, smoking pack-years) may contribute meaningful information to differentiate NSCLC from other types of lung cancer but was not available in this data source. The algorithm may perform differently in administrative healthcare data sources outside the US, as different coding adaptations of ICD and different real-world reimbursement requirements/environment in other countries influence the performance of real-world data algorithms.25
Conclusion
Our study developed and validated a practical, 10-variable, point-based algorithm for identifying incident NSCLC cases in a US claims database based on a previously validated incident lung cancer algorithm. We developed the algorithm using diagnostic and procedural codes instead of medications to support the algorithm’s longer-term relevance and reliability and validated the algorithm using a criterion validity approach. The fit for purpose of any RWE algorithm is dependent on its context of use1 and both internal validity (eg, algorithm performance within this study) and external validity (eg, generalizability of the algorithm to the real-world data source where it will be applied for conducting future research) should be assessed by researchers considering whether to use the algorithm.26 In our view, based on the performance of the final point-score in terms of its sensitivity and PPV, the final point-score NSCLC algorithm is likely fit for purpose for general disease state studies including burden of illness and treatment patterns. Researchers should consider the algorithm’s performance in the context of their study question and data source, as described in the Certainty Framework for real-world data variables.27 The implementation of a previously validated, broader lung cancer algorithm increased the performance of the point-based algorithm, which may be an important consideration for researchers building algorithms that comprise a subtype of the disease.
Data Sharing Statement
The dataset used for the current study is not publicly available due to SEER-Medicare Data Use Agreement restrictions. However, researchers may obtain access to SEER-Medicare data by submitting a proposal (details for submitting proposals are available at https://healthcaredelivery.cancer.gov/seermedicare/obtain/).
Ethics Statement
The protocol was reviewed and considered exempt by Quorum Review IRB prior to National Cancer Institute approval of the SEER‐Medicare data for this study.
Acknowledgments
The authors thank Elaine Yanisko of IMS, Inc. for support in triaging data-related questions with staff at the National Cancer Institute, Shannon Gardell and Colleen Dumont of Evidera for their expert writing and editorial reviews of the manuscript, and Yushi Liu of Eli Lilly and Company for statistical peer review. For feasibility analysis and creating the analytic dataset, the authors thank Tim Ellington of Delisle Associates LTD. For validation of analytic programs, the authors thank Jessica Mitroi of Eli Lilly and Company. For quality review of the final manuscript, the authors thank Nancy Hedlund of MedNavigate LLC. .JB and DRN are joint senior authors for this study.
Author Contributions
All authors made a significant contribution to the work reported, whether that is in the conception, study design, execution, acquisition of data, analysis and interpretation, or in all these areas; took part in drafting, revising or critically reviewing the article; gave final approval of the version to be published; have agreed on the journal to which the article has been submitted; and agree to be accountable for all aspects of the work.
Funding
This study was funded by Eli Lilly and Company. Medical writing assistance was provided by Shannon Gardell of Evidera and was funded by Eli Lilly and Company. Evidera complied with international guidelines for Good Publication Practice (GPP3).
Disclosure
JB, DRN, KMS, and YJH are employees and shareholders of Eli Lilly and Company. YKL was an employee of Eli Lilly and Company during the conduct of the study. ALH is an employee of the University of Cincinnati and reports grants from Eli Lilly during the conduct of the study. The authors report no other conflicts of interest in this work.
References
1. Beyrer J, Abedtash H, Hornbuckle K, Murray JF. A review of stakeholder recommendations for defining fit-for-purpose real-world evidence algorithms. J Comp Eff Res. 2022;11(7):499–511. doi:10.2217/cer-2022-0006
2. National Cancer Institute [Internet]. Cancer Stat Facts: lung and Bronchus Cancer. Available from: https://seer.cancer.gov/statfacts/html/lungb.html.
3. United States Preventive Services Task Force [Internet]. Final recommendation statement: lung cancer: screening; 2021. Available from https://www.uspreventiveservicestaskforce.org/uspstf/recommendation/lung-cancer-screening.
4. American Cancer Society [Internet]. What is lung cancer? Available from: https://www.cancer.org/cancer/lung-cancer/about/what-is.html.
5. Uno H, Ritzwoller DP, Cronin AM, Carroll NM, Hornbrook MC, Hassett MJ. Determining the time of cancer recurrence using claims or electronic medical record data. JCO Clin Cancer Inform. 2018;2:1–10. doi:10.1200/CCI.17.00163
6. Abraha I, Montedori A, Serraino D, et al. Accuracy of administrative databases in detecting primary breast cancer diagnoses: a systematic review. BMJ Open. 2018;8(7):e019264. doi:10.1136/bmjopen-2017-019264
7. van Walraven C, Austin P. Administrative database research has unique characteristics that can risk biased results. J Clin Epidemiol. 2012;65(2):126–131. doi:10.1016/j.jclinepi.2011.08.002
8. Chan AW, Fung K, Tran JM, et al. Application of recursive partitioning to derive and validate a claims-based algorithm for identifying keratinocyte carcinoma (nonmelanoma skin cancer). JAMA Dermatol. 2016;152(10):1122–1127. doi:10.1001/jamadermatol.2016.2609
9. Nordstrom BL, Simeone JC, Malley KG, et al. Validation of claims algorithms for progression to metastatic cancer in patients with breast, non-small cell lung, and colorectal cancer. Front Oncol. 2016;1(6):18.
10. Bergquist SL, Brooks GA, Keating NL, Landrum MB, Rose S. Classifying lung cancer severity with ensemble machine learning in health care claims data. Proc Mach Learn Res. 2017;68:25–38. doi:10.1016/j.csbj.2014.11.005
11. Turner RM, Chen YW, Fernandes AW. Validation of a case-finding algorithm for identifying patients with non-small cell lung cancer (NSCLC) in administrative claims databases. Front Pharmacol. 2017;30(8):883. doi:10.3389/fphar.2017.00883
12. Centers for Medicare and Medicaid Services [Internet]. Centers for Medicare and Medicaid Services. HCPCS - General Information. Baltimore (MD). Available from: https://www.cms.gov/Medicare/Coding/MedHCPCSGenInfo.
13. Nadpara P, Madhavan SS, Tworek C. Guideline-concordant timely lung cancer care and prognosis among elderly patients in the United States: a population-based study. Cancer Epidemiol. 2015;39(6):1136–1144. doi:10.1016/j.canep.2015.06.005
14. Wong ML, McMurry TL, Stukenborg GJ, et al. Impact of age and comorbidity on treatment of non-small cell lung cancer recurrence following complete resection: a nationally representative cohort study. Lung Cancer. 2016;102:108–117. doi:10.1016/j.lungcan.2016.11.002
15. Beyrer J, Nelson DR, Sheffield KM, Huang YJ, Ellington T, Hincapie AL. Development and validation of coding algorithms to identify patients with incident lung cancer in United States healthcare claims data. Pharmacoepidemiol Drug Saf. 2020;29(11):1465–1479. doi:10.1002/pds.5137
16. Nattinger AB, Laud PW, Bajorunaite R, Sparapani RA, Freeman JL. An algorithm for the use of Medicare claims data to identify women with incident breast cancer. Health Serv Res. 2004;39(6 Pt 1):1733–1749. doi:10.1111/j.1475-6773.2004.00315.x
17. National Comprehensive Cancer Network [Internet]. Plymouth Meeting (PA): national Comprehensive Cancer Network. National Comprehensive Cancer Network Guidelines. Available from: https://www.nccn.org/professionals/physician_gls/default.aspx.
18. Zhao Z, Zhang R, Cox J, Duling D, Sarle W. Massively parallel feature selection: an approach based on variance preservation. Mach Learn. 2013;92(1):195–220. doi:10.1007/s10994-013-5373-4
19. Sullivan LM, Massaro JM, D’Agostino RB. D’Agostino RB Sr. Presentation of multivariate data for clinical use: the Framingham Study risk score functions. Stat Med. 2004;23(10):1631–1660. doi:10.1002/sim.1742
20. Zhang Z, Zhang H, Khanal MK. Development of scoring system for risk stratification in clinical medicine: a step-by-step tutorial. Ann Transl Med. 2017;5(21):436. doi:10.21037/atm.2017.08.22
21. Gilpin LH, Bau D, Yuan BZ, Bajwa A, Specter M, Kagal L, Explaining explanations: an overview of interpretability of machine learning. In
22. Lipton ZC. The Mythos of Model Interpretability: in machine learning, the concept of interpretability is both important and slippery. Queue. 2018;16(3):31–57. doi:10.1145/3236386.3241340
23. Hosmer DW, Lemeshow S. Applied Logistic Regression.
24. Schumock GT, Lee TA, Pickard AS, et al. Mini-Sentinel methods — alternative methods for health outcomes of interest validation. FDA White Paper; 2013. Available from: https://www.sentinelinitiative.org/sites/default/files/surveillance-tools/validations-literature/Mini-Sentinel-Alternative-Methods-for-Health-Outcomes-of-Interest-Validation_0.pdf.
25. Schulman KL, Berenson K, Tina Shih YC, et al. A checklist for ascertaining study cohorts in oncology health services research using secondary data: report of the ISPOR oncology good outcomes research practices working group. Value Health. 2013;16(4):655–669. doi:10.1016/j.jval.2013.02.006
26. Singh S, Beyrer J, Zhou X, et al. Development and Evaluation of the Algorithm CErtaInty Tool (ACE‑IT) to Assess Electronic Medical Record and Claims‑based Algorithms’ Fit for Purpose for Safety Outcomes. Drug Saf. 2022. doi:10.1007/s40264-022-01254-4
27. Cocoros NM, Arlett P, Dreyer NA, et al. The Certainty Framework for assessing real-world data in studies of medical product safety and effectiveness. Clin Pharmacol Ther. 2021;109(5):1189–1196. doi:10.1002/cpt.2045
 © 2023 The Author(s). This work is published and licensed by Dove Medical Press Limited. The
full terms of this license are available at https://www.dovepress.com/terms
and incorporate the Creative Commons Attribution
- Non Commercial (unported, 3.0) License.
By accessing the work you hereby accept the Terms. Non-commercial uses of the work are permitted
without any further permission from Dove Medical Press Limited, provided the work is properly
attributed. For permission for commercial use of this work, please see paragraphs 4.2 and 5 of our Terms.
© 2023 The Author(s). This work is published and licensed by Dove Medical Press Limited. The
full terms of this license are available at https://www.dovepress.com/terms
and incorporate the Creative Commons Attribution
- Non Commercial (unported, 3.0) License.
By accessing the work you hereby accept the Terms. Non-commercial uses of the work are permitted
without any further permission from Dove Medical Press Limited, provided the work is properly
attributed. For permission for commercial use of this work, please see paragraphs 4.2 and 5 of our Terms.
Recommended articles
Validity of Inflammatory Bowel Disease Diagnoses in the Danish National Patient Registry: A Population-Based Study from the North Denmark Region
Albaek Jacobsen H, Jess T, Larsen L
Clinical Epidemiology 2022, 14:1099-1109
Published Date: 6 October 2022
A Validated Algorithm for Register-Based Identification of Patients with Relapse of Clinical Stage I Testicular Cancer
Wagner T, Lauritsen J, Bandak M, Rasmussen LA, Bakker J, Hovaldt HB, Larsson H, Christensen IJ, Toft BG, Agerbæk M, Dysager L, Kreiberg M, Rosenvilde JJ, Engvad B, Berney DM, Daugaard G
Clinical Epidemiology 2023, 15:447-457
Published Date: 5 April 2023
Machine Learning Algorithm to Estimate Distant Breast Cancer Recurrence at the Population Level with Administrative Data
Izci H, Macq G, Tambuyzer T, De Schutter H, Wildiers H, Duhoux FP, de Azambuja E, Taylor D, Staelens G, Orye G, Hlavata Z, Hellemans H, De Rop C, Neven P, Verdoodt F
Clinical Epidemiology 2023, 15:559-568
Published Date: 5 May 2023
Machine Learning for Prediction of Non-Small Cell Lung Cancer Based on Inflammatory and Nutritional Indicators in Adults: A Cross-Sectional Study
Wang Q, Liang T, Li Y, Liu X
Cancer Management and Research 2024, 16:527-535
Published Date: 30 May 2024
A Validation Study of the Danish ICD-10 Diagnosis Code K75.0 for Pyogenic Liver Abscess
Dudina M, Søgaard KK, Olesen SS, Nielsen HL
Clinical Epidemiology 2024, 16:803-810
Published Date: 21 November 2024