Back to Journals » Diabetes, Metabolic Syndrome and Obesity » Volume 12
An automatic diagnostic system based on deep learning, to diagnose hyperlipidemia
Authors Zhang Q, Liu Y ![]() , Liu G, Zhao G, Qu Z, Yang W
, Liu G, Zhao G, Qu Z, Yang W
Received 17 December 2018
Accepted for publication 8 March 2019
Published 3 May 2019 Volume 2019:12 Pages 637—645
DOI https://doi.org/10.2147/DMSO.S198547
Checked for plagiarism Yes
Review by Single anonymous peer review
Peer reviewer comments 3
Editor who approved publication: Dr Konstantinos Tziomalos
Quan Zhang,1,2 Yuliang Liu,1,2 Guohua Liu,3,4 Geng Zhao,5 Zhigang Qu,1,2 Weiming Yang1,2
1College of Electronic Information and Automation; 2Binhai International Advanced Structural Integrity Research Centre, Tianjin University of Science and Technology, Tianjin 300222, People’s Republic of China; 3College of Electronic Information and Optical Engineering; 4Tianjin Key Laboratory of Optoelectronic Sensor and Sensing Network Technology, NanKai University, Tianjin, People’s Republic of China; 5Tianjin Medical University Hospital for Metabolic Disease, Tianjin 300070, People’s Republic of China
Background: Using artificial intelligence to assist in diagnosing diseases has become a contemporary research hotspot. Conventional automatic diagnostic method uses a conventional machine learning algorithm to distinguish features from which a professional doctor manually extracts features in diagnostic reports. But it can be difficult to collect large amounts of necessary medical data. Therefore, these methods face challenges with efficiency and accuracy.
Method: Here, we proposed an automatic diagnostic system based on a deep learning algorithm to diagnose hyperlipidemia by using human physiological parameters. This model is a neural network which uses technologies of data extension and data correction. Firstly, we corrected and supplemented the original data by the method mentioned previously to solve the problem of lacking data. Secondly, the processed data were used to train a deep learning model. Deep learning model can automatically extract all the available information instead of artificially reducing the raw data. Therefore, it can reduce labor costs. The classifiers classify the data by using features previously mentioned. Finally, the system was evaluated with data from a test dataset.
Result: It achieved 91.49% accuracy, 87.50% sensitivity, 93.33% specificity, and 87.50% precision with data from the test dataset.
Conclusion: The proposed diagnostic method has a highly robust and accurate performance, and can be used for tentative diagnosis. It can automatically diagnose diseases by using human physiological parameters, thereby reducing labor cost, which results in effective improvement of clinical diagnostic efficiency.
Keywords: Auxiliary Diagnosis, Physiological Parameters, Expending Learning Algorithm
Introduction
With the continuous improvement in living standards and the growing problem of an aging population, there is an urgent need for technologies which can improve medical technology, prolong human life, and improve health. In order to meet these demands, many countries have formulated many policies to combine medical technology with the technology of artificial intelligence (AI) and hope that AI technology can further improve medical care1–11 on an international level.
In recent years, many research about automatic diagnosis of diseases using medical imaging has been reported, such as Kermany et al, who used Inception V3 model trained by Google and transfer learning algorithm to automatically diagnose retinopathy and infantile pneumonia by OCT images of retina and X-ray images respectively.12 Coudray et al predicted and classified mutation of non-small-cell lung cancer histopathology by deep learning algorithm.13
Schwemmer et al improved brain-computer interface by deep neural network decoding framework in order to automatically distinguish electroencephalogram first and then control electrical machinery to assist the body to accomplish the desired action.14 Because the AI system has shown outstanding performance beyond human expertise in the field of image recognition, it has the potential to revolutionize disease diagnosis by using medical images.15–18 Despite its potential, detecting disease through medical text data of AI remains challenging. Besides the diseases that can be diagnosed using medical images, there are some diseases that can be diagnosed by text-based medical data, such as diabetes, hyperlipidemia, and other diseases which need medical examination.
To solve these problems, researchers have proposed a long-short-term memory (LSTM) network and a one-dimensional convolutional neural network and.19,20 1D-convolution neural network (1D-CNN) processes encoded data with different filters to find features which are hidden in the raw data. LSTM implements an attention mechanism by neuron which has a memory function to learn the joint features of data far apart. In short, both models take the original text as input, automatically extract features, and then use the classification function to automatically classify samples. The proposed two structures make it possible to classify text data.21–24 The text data classification method based on deep learning technology replaces the spatial distance based traditional clustering algorithm, which improves classification accuracy.
The traditional automatic diagnosis methods relied on: 1) patients described their clinical manifestation; 2) researchers extracted features by experience and coded these features to form eigenvector; 3) classification algorithm classified the eigenvector. Because traditional methods extract features manually, they are subjective and one-sided. Lack of relevant data is another challenge for deep learning models, medical data are invaluable. At present, electronic health records (EHRs) are widely used in medical research, but there is no standardized method to evaluate the EHRs’ quality, which means the accuracy of disease diagnosis using electronic health cases has been limited.25–28 If we do not have the necessary data, the model either cannot extract necessary information in order to diagnose a disease precisely, or over-learns the features which makes it difficult to show good robustness on a test dataset. One solution for the lack of necessary data is to supplement the original data with the extended data, this method is known as expanding learning algorithm. In some papers, expanding learning has been proven to be an effective algorithm, especially when faced with the lack of raw data.29 The expanding learning algorithm proposed by us does not simply find the relationship between input and output through complex coding to achieve the purpose of classification, this model can distinguish the implicit knowledge of each disease, such as diabetic patients with high blood sugar and glycosylated hemoglobin values. Therefore, it can achieve higher performance without a large amount of raw data and human resources. Hyperlipidemia refers to the abnormal metabolism or operation of fat, so that one or more lipids in plasma are higher than normal. It can directly cause some diseases that seriously endanger human health, such as atherosclerosis, coronary heart disease, pancreatitis, and so on. At the same time, with the development of technology and science, researchers have found that hyperlipidemia is highly correlated with more and more diseases, such as cancer.23 Therefore, worldwide, hyperlipidemia has become one of the important factors threatening human health.30 Researchers have done many studies on the diagnosis and treatment of hyperlipidemia24,31,32 using hematological and urine parameters to diagnose the disease and evaluate the effectiveness of the treatment. There are different methods of obtaining physiological parameterswhich describe the different health conditions of the human body.33,34 This makes it possible to make a clinical diagnosis based on these parameters.
In this paper, we hope to propose an effective deep learning model for timely and accurate diagnosis of each human physiological parameter’s data. The parameters of human hematology and human urine were used to explain the algorithm, and we also compared the expanding algorithm’s capability with other different algorithms. Compared with the EHR, medical test information with unified standards has higher reliability. The primary application of the expanding learning algorithm is to diagnose hyperlipidemia by using human hematology parameters and human urine parameters.32,35,36 The human physiological parameters cover the results of blood glucose detection, glycosylated hemoglobin test, routine blood examination, routine urine test, and biochemical detection. In this paper, we used human parameters of hematology and urinology to diagnose hyperlipidemia rather than only using blood parameter. Therefore, compared with other traditional methods, this method is all-sided. The method presented in this paper processed all information of selected data, instead of manual pre-extraction of features, therefore, it not only has higher objectivity and comprehensiveness but also reduces labor costs. In order to resolve the problem of lack of relevant data, a method for expanding raw data is proposed. When facing lack of data, this data expanding method can also make auxiliary diagnostic system achieve a better performance. The auxiliary diagnostic system score achieved 91.49% accuracy, 87.50% sensitivity, 93.33% specificity, and 87.50% precision with a test dataset. This performance of the expanding algorithm gives us confidence that the system has real potential for precise diagnosis with less raw data for auxiliary diagnosis of hyperlipidemia in a practical environment. Furthermore, the experiment results confirmed that using an expanding learning model to diagnose hyperlipidemia is feasible.
Subjects and methods
Study subjects
The dataset initially contained 446 different patients’ physiological data. Each dataset is composed of 49 patients’ physiological information and doctors’ diagnosis results. The physiological data include routine blood parameters (A), routine urine parameters (B), biochemical test parameters (C), blood sugar parameters (D), and glycosylated hemoglobin parameters (E). The types of parameters contained in each inspection item are shown in Table 1.
 | Table 1 Types of parameters contained in each inspection item |
The health status of each dataset is determined by a professional doctor’s test report. Among them, a total of 400 subjects were used to train the expanding deep learning model and optimize the model’s hyperparameters. The remaining 46 subjects' completely independent data were used to evaluate the performance of the model. The previously mentioned steps are to ensure the proposed method is not only applicable to data not in the training set, but also applicable to patients not in the training set as well.
The raw data was obtained from Tianjin Medical University Hospital for Metabolic Disease between December 15, 2017, and January 20, 2018. All subjects in this study were undergoing hospital health examinations. Before the experiment, we had obtained permission from the Ethics Committee of Tianjin Medical University and patients’ written consent was obtained. All patient information was anonymously processed before being analyzed.
There were 251 male patients (56.28%) and 196 female patients (43.72%) in our study (26 male patients and 20 female patients in test dataset), aged 26–82 years (median age of 56). The exclusion criteria were pregnancy, lactation, the use of drugs that inhibit hyperlipidemia. All patients were tested on an empty stomach and all the test conditions met the gold criteria for the diagnosis of hyperlipidemia. There were 86 cases of hyperlipidemia in all samples (16 in test dataset).
The information of each patient was measured by a fellowship-trained laboratory physician and the information was reviewed by a fellowship-trained endocrinologist with 10 and 8 years experience in diagnostic reports.39
Method
The deep learning model is a 1D-CNN, and the technology of dropout and pooling was used in this model. The eigenvector composed of human physiological parameters, which were processed by convolution layer and pooling layer, and the hidden features in the data could be extracted. Finally, the extracted features were classified by classification function. Global parameters were updated using stochastic gradient descent, the classification was sigmoid function. At the same time, the performance of traditional neural network algorithm, LSTM and Support Vector Machine (SVM) algorithm was also compared with the expanding learning algorithm.
1D-CNN
The core of the expanding learning algorithm is 1D-CNN. It can effectively process some text data which have fixed rule. The diagram of 1D-convolution principle was shown in Figure 1.
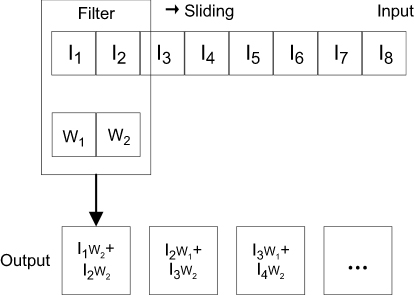 | Figure 1 The diagram of 1D-convolution principle. |
Filters extract features of input by sharing weights method and one filter matches a kind of feature. When a trained filter detects that a particular feature exists in the data, the corresponding filter is activated. Its principle is shown in Equation 1.
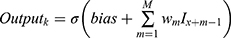
Where,  is the real output value of the K-th neuron of the feature map,
is the real output value of the K-th neuron of the feature map,  is ReLu,
is ReLu,  is the value of bias parameters,
is the value of bias parameters, 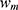 is the m-th value of weight matrix,
is the m-th value of weight matrix, 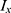 is input value of the x-th neuron,
is input value of the x-th neuron, 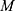 is filter length.
is filter length.
Parameter updating
We used stochastic gradient descent method to update global parameters in this paper. By the method of extracting mini-batch samples from the raw data and calculating their average gradient, the unbiased estimation gradient of whole data could be obtained. This method can improve the speed of training effectively. These principle are shown in Equations 2 and 3.
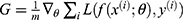
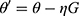
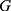 is loss-function’s gradient,
is loss-function’s gradient,  is the quantity of mini-batch,
is the quantity of mini-batch, 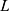 is cross-entropy loss function,
is cross-entropy loss function, 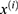 is the i-th subject’s input,
is the i-th subject’s input,  is expected output corresponding to the
is expected output corresponding to the 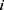 -th sample,
-th sample, 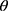 is the model’s global parameters,
is the model’s global parameters, 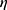 is the learning rate,
is the learning rate, 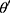 is updated parameters. The cross-entropy loss function was shown in Equation 4.
is updated parameters. The cross-entropy loss function was shown in Equation 4.
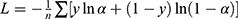
In Equation 4,  is the number of sample,
is the number of sample,  is the model output, and
is the model output, and 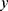 is desired output.
is desired output.
LSTM
The LSTM learns the alliance characteristics of data by neurons with memory function. The schematic diagram of LSTM was shown in Figure 2. The structure of LSTM cell was shown in Figure 3.
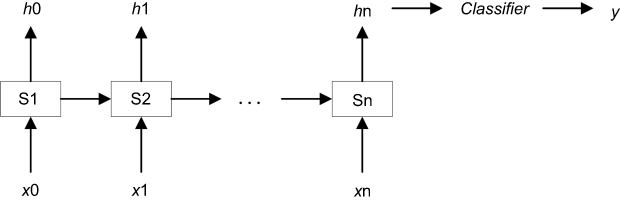 | Figure 2 The schematic diagram of long-short-term memory which can provide auxiliary diagnosis. |
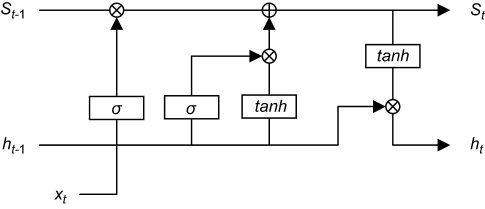 | Figure 3 The structure of long-short-term memory cell. |
The method of updating the status (S) of LSTM cells is shown in 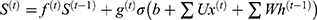
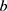 ,
, 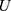 ,
, 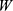 are bias, input weight, and cycle weight of forgetting gate, respectively.
are bias, input weight, and cycle weight of forgetting gate, respectively. 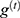 is the external input gate,
is the external input gate, 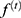 is the control function of forgetting.
is the control function of forgetting.
SVM
SVM algorithm is a clustering method based on kernel function. We can use the value of the decision function to determine the health of the sample. SVM only outputs the type of sample instead of probability. The principle of SVM is shown in Equation 6.
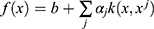
In this equation, 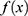 is decision function,
is decision function,  is the vector of parameters,
is the vector of parameters, 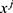 is the data which were used to train the model,
is the data which were used to train the model, 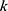 is the kernel function.
is the kernel function.
Experiment and result
Data extensions and correction
In this experiment, we used extended data to supplement original data to solve the problem of lack of raw data. Therefore, we added the original data to the stochastic perturbation matrix to form the augmentation matrix. The principle of expanding data is shown in Equation 7.
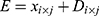
Where 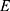 is extended matrix,
is extended matrix,  is undisturbed raw data,
is undisturbed raw data, 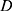 is stochastic disturbance matrix. Here, the value of the stochastic perturbation matrix mentioned previously must be sufficiently less than the original data to avoid changing the features of raw data. At the same time, the size of the stochastic matrix must also be consistent with the original data.
is stochastic disturbance matrix. Here, the value of the stochastic perturbation matrix mentioned previously must be sufficiently less than the original data to avoid changing the features of raw data. At the same time, the size of the stochastic matrix must also be consistent with the original data.
The effect of data quantization on model performance in experiments has also been studied. Physiological parameters with negative results were expressed by values which were close to zero instead of zero. The method mentioned previously is data correction.
Training model
We used raw data and extended data to train deep learning models at the same time. Figure 4 shows the basic principle of expanding learning algorithm. The experiment environment was Ubuntu 16.04. Experimental software was Keras which is based on Tensorflow.
 | Figure 4 Expanding learning algorithm. |
The original data consisted of two parts: 1) training-part: we used 400 participants’ raw data and their extended data to train the expanding learning model and 2) evaluation-part: the performance of the model was evaluated by the remaining 46 independent samples. The training part also had two parts: 1) weight-part: 90% of the training-part was used to update the global parameters of network and 2) hyperparameter-part: the remaining 10% data of the training-part were used to fine-tune the hyperparameters of the model (such as the number of layers). In this paper, 10-fold cross-validation algorithm was a good choice for optimizing hyperparameters. During the training processing the data of weight-part were expanded but the hyperparameter-part had not been expanded. The AI system mentioned previously was evaluated by the accuracy of diagnosis in the evaluation-part previously mentioned. In order to prevent the phenomenon of over-fitting, the early stopping algorithm was used in this paper (Patience =5). Besides, the gradient of cost function was used to optimize global parameters.
One-hot coding technique was used in training processing. N kinds of health conditions were represented by N-dimensional vectors. Different elements in the vectors represented different health conditions, only the corresponding elements in the vectors were 1 and the rest were 0. This method could improve the model’s diagnosis accuracy and generalization ability. The health diagnosis result was coded as 10, and the diagnosis result of hyperlipidemia was coded as 01 by the previously mentioned method.
Because the task of classification layer is binary classification task, sigmoid classification function was used to classify the samples. Each health condition corresponds to a neuron in the output layer and corresponds to one-hot vector. The sigmoid function is shown in Equation 8.
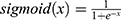
The accuracy of different algorithms on the same test dataset was used to evaluate the model’s performance. In the experimental process, we also compared the performance of expanding learning algorithm, SVM, LSTM, and traditional neural network algorithm. The SVM of this study was C-SVC SVM using RBF kernel. The stochastic gradient descent algorithm, sigmoid function, and one-hot coding technique were also used in LSTM and traditional neural network to update parameters, classify the samples, and encode disease types, respectively.
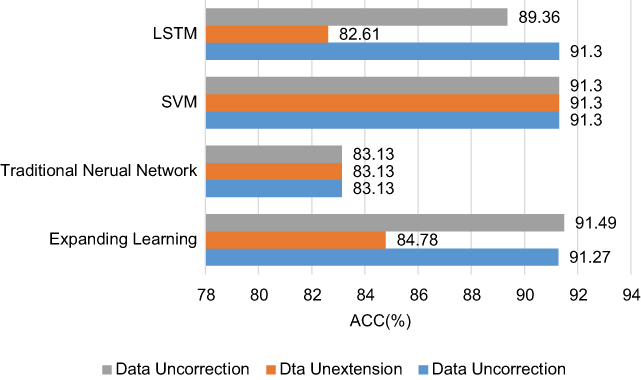
The results showed that the AI system proposed in this paper could diagnose hyperlipidemia better. For this condition, patients can initially be referred to different departments to save medical resources. The performance of different models is shown in Figure 5. The confusion matrix of expanding learning is shown in Figure 6. The expanding learning algorithm achieved 91.49% accuracy, 87.50% sensitivity, 93.33% specificity, and 87.50% precision with the data from the test dataset.
 | Figure 5 The accuracy (ACC) of each model.Abbreviations: LSTM, long-short-term memory; SVM, Support Vector Machine. |
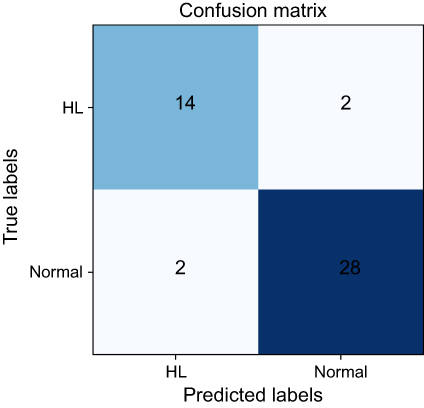 | Figure 6 The confusion matrix of expanding learning.Abbreviation: HL, Hyperlipemia. |
Discussion
In this paper, an expanding learning algorithm was proposed to diagnose hyperlipidemia by using human hematologic parameters and urinology. By using the previously mentioned expanding learning algorithm, the model proposed in this paper could achieve better performance without requiring a large amount of raw data and labor, so it shows great potential in processing medical text data. Moreover, the model’s performance was compared with other models. As shown in Figure 5, the performance of the expanding learning algorithm and LSTM model was improved by same extended data and raw data, this phenomenon demonstrated that the expanding learning algorithm has the ability to increase the diagnostic accuracy and robustness of the model, even when facing a lack of raw data. In the experiment, we found that the performance of LSTM, which was trained using the same dataset, did not exceed that of the extended learning model. We speculate that the reason for this phenomenon is that LSTM is more suitable for recognizing time series. Therefore, the expanding learning algorithm is not a bad choice to process medical text data when there is a lack of original data.
At the same time, we found that the quantification of diagnostic reports has an impact on the performance of the model. In experiments, diagnostic reports are quantified in different ways. As shown in Figure 5, the performance of the expanding learning model and LSTM model mentioned previsously could be improved by data correction. We suspect that this is because the data-correction algorithm turns more input into valid input. It means that the negative parameters (the medical test results were negative) can be learned more easily by the model. Proof, by facts, shows that the quantification method of non-numeric medical text data also decides the model’s performance. Therefore, in future work, we will explore more data quantization methods to further improve the performance of the model.
As shown in Figure 5, the traditional neural network algorithm and SVM algorithm’s performance could not be improved by the method of data expanding and data correction. This phenomenon not only confirms that the expanding learning algorithm mentioned previously is a better choice when lacking the necessary original data, but also illuminates that the model has more possibilities that can be optimized.
Within a limited range, we found similar work in disease diagnosis using deep learning to process text-based medical data. Pradeep and Naveen used classification techniques of decision-making tree, SVM, and Naive Bayes algorithm to predict lung cancer survivability by using EHRs and achieved precision of 82.6%, 70.5%, and 78.6%, respectively.37 Our expanding algorithm achieved 87.50% precision. Their methods used a machine learning algorithm to diagnosis many kinds of diseases using EHRs. All of these studies have achieved good verification results using traditional feature extraction and machine learning processing structures. The processing structure we proposed can directly process all the information in the original data without the need to artificially extract features. At the same time, the human physiological parameters used in this paper come from standard medical tests rather than artificial descriptions, so it has subjectivity and unity. Hence, after the previously mentioned model automatically extracts the characteristics of data, it can also make a good judgment on the data outside of the training set.
Based on this, a new method for detecting hyperlipidemia was proposed, which can detect hyperlipidemia automatically and accurately even when facing lack of necessary raw data. With this algorithm, all available information can be automatically extracted from the raw data without human involvement. Because the algorithm mentioned previously does not artificially lose raw data, it may have the potential to find more diagnostic markers of different diseases. Besides, in this paper we used human physiological parameters of hematology and urinology to diagnose hyperlipidemia rather than only using blood, which gives the model better comprehensiveness. Data extension method can improve the lack of data and data correction method can improve the model’s performance by learning the negative parameters better. Therefore, these methods could improve the model’s accuracy effectively. As a consequence, the computer-aided diagnosis system achieved robust and accurate results (it achieved 91.49% accuracy, 87.50% sensitivity, 93.33% specificity, and 87.50% precision with test dataset).
Even though it has great potential, it still has some limitations. One limitation of our study was that we used only hematological and urinology parameters to diagnosis disease. The identification of some diseases also requires other types of medical data (such as antibody detection).38 Therefore, we will supplement our dataset with other kinds of medical data in future work. The other limitation is that some factors affecting cholesterol levels have not been applied to training models, such as age, sex, etc. Compared with the golden criteria for diagnosis of hyperlipidemia, the accuracy of our model has not yet met the clinical requirements. This phenomenon may have been caused by the model’s lack of judgment on physiological parameters of the same patient over a period of time. Therefore, in future work, we will study how to add more factors in our model such as age, sex, family history of disease, history of disease, diagnostic recorders, to name a few.
We proposed an AI system which can automatically provide an auxiliary diagnosis of hyperlipidemia based on human urinary and hematological parameters. Moreover, the model also showed strong generalization ability, so it has the potential to be applied to a wider range of medical text data to achieve assistant clinical diagnosis. This view can be proved by comparing the performance of the models mentioned previously and discussing the possibility that the expanding learning algorithm may be further optimized. Medical text data play a crucial role in the process of diagnosing diseases. Therefore, more effective analysis of textual medical data is the basis for further improvement of medical level. According to the experimental results, the medical text data-based auxiliary diagnosis has the ability to effectively identify more complex data with less raw data. It improves the efficiency of diagnosis, saves social resources and medical resources, and reduces the medical treatment cycle. It has positive significance for the development of auxiliary diagnosis technology using medical text data.
Conclusion
In this paper, an expanding learning algorithm was proposed to automatically diagnose hyperlipidemia. It achieved 91.49% accuracy, 87.50% sensitivity, 93.33% specificity, and 87.50% precision with the data from a test dataset. This paper also compared the performance of different models for diagnosing hyperlipidemia and the influence of quantitative methods of diagnostic reports on a model’s performance.
A new method was proposed to precisely detect hyperlipidemia by expanding learning algorithm automatically, even if raw data are lacking. The influence of quantitative methods of diagnostic reports on models’ performance was also studied. It can help us to make sense of that data, thereby reducing the workload of clinicians. Therefore, its potential benefit to patients is that it may speed up the patient’s medical treatment process. Moreover, because it does not need to reduce original data manually, for clinical research, it might be able to find new pathogenic factors and study the influence weights of different pathogenic factors.
Future work should center on enabling assistive diagnostic systems to diagnose more types of human diseases. Not only the physiological parameters mentioned in this paper, but also many other physiological parameters are necessary for the diagnosis of other diseases, such as electrocardiography etc. In order to identify more types of diseases, we will expand our data with more types of text-based medical data and consider more disease-related factors such as age, sex, etc. Because the computer-aided diagnosis system mentioned previously gets all the information hidden in the selected data, the information of original data is not reduced by feature extraction. Therefore, we will study the pathogenic factors of different diseases and their weights. In addition to solving the problem from the perspective of medical engineering, we also plan to optimize the structure and algorithm of the model from the perspective of engineering in the future (such as computational resource consumption, hyperparameters optimization method).
Acknowledgment
This work was funded by the National Natural Science Foundation of China (51674176, 61873187).
Author contributions
All authors contributed to data analysis, drafting or revising the article, gave final approval of the version to be published, and agree to be accountable for all aspects of the work.
Disclosure
The authors report no conflicts of interest in this work.
References
1. Wong D, Yip S. Machine learning classifies cancer. Nature. 2018;555:446–447. doi:10.1038/d41586-018-02881-7
2. Camacho DM, Collins KM, Powers RK, Costello JC, Collins JJ. Next-generation machine learning for biological networks. Cell. 2018;173(7):1581–1592. doi:10.1016/j.cell.2018.05.015
3. Churchill O. China’s AI dreams. Nature. 2018;553(7688):S10. doi:10.1038/d41586-018-00539-y
4. Fleming N. How artificial intelligence is changing drug discovery. Nature. 2018;557(7707):S55. doi:10.1038/s41586-018-0096-0
5. Ghahramani Z. Probabilistic machine learning and artificial intelligence. Nature. 2015;521:452–459. doi:10.1038/nature14541
6. Hosny A, Parmar C, Quackenbush J, Schwartz LH, Aerts HJWL. Artificial intelligence in radiology. Nat Rev Cancer. 2018;18(8):500–510. doi:10.1038/s41568-018-0016-5
7. Leachman SA, Merlino G. The final frontier in cancer diagnosis. Nature. 2017;542:36. doi:10.1038/nature21048
8. Taddeo M, Floridi L. How AI can be a force for good. Science. 2018;361(6404):751–752. doi:10.1126/science.aat5991
9. Wainberg M, Merico D, Delong A, Frey BJ. Deep learning in biomedicine. Nat Biotechnol. 2018;36(9):829–838. doi:10.1038/nbt.4233
10. Webb S. Deep learning for biology. Nature. 2018;554(7693):555–557. doi:10.1038/d41586-018-02174-z
11. Yang GZ, Bellingham J, Dupont PE, et al. The grand challenges of Science Robotics. Sci Robot. 2018;3(14):eaar7650.
12. Kermany DS, Goldbaum M, Cai W, et al. Identifying medical diagnoses and treatable diseases by image-based deep learning. Cell. 2018;172(5):
13. Coudray N, Ocampo PS, Sakellaropoulos T, et al. Classification and mutation prediction from non-small cell lung cancer histopathology images using deep learning. Nat Med. 2018;24:1559–1567. doi:10.1038/s41591-018-0177-5
14. Schwemmer MA, Skomrock ND, Sederberg PB, et al. Meeting brain–computer interface user performance expectations using a deep neural network decoding framework. Nat Med. 2018;24:1669–1676. doi:10.1038/s41591-018-0171-y
15. Maxmen A. AI researchers embrace Bitcoin technology to share medical data. Nature. 2018;555(7696):293–294. doi:10.1038/d41586-018-02641-7
16. Lynch CJ, Liston C. New machine-learning technologies for computer-aided diagnosis. Nat Med. 2018;24(9):1304–1305. doi:10.1038/s41591-018-0178-4
17. Manak MS, Varsanik JS, Hogan BJ, et al. Live-cell phenotypic-biomarker microfluidic assay for the risk stratification of cancer patients via machine learning. Nat Biomed Eng. 2018;2:761–772. doi:10.1038/s41551-018-0285-z
18. Singal AG, Mukherjee A, Joseph Elmunzer B, et al. Machine learning algorithms outperform conventional regression models in predicting development of hepatocellular carcinoma. Am J Gastroenterol. 2013;108:1723–1730. doi:10.1038/ajg.2013.332
19.
20. Gers FA, Schmidhuber J, Cummins FJNC. Learning to forget: continual prediction with LSTM. Neural Comput. 2000;12(10):2451–2471.
21. Liang Z, Liu J, Ou A, Zhang H, Li Z, Huang JX. Deep generative learning for automated EHR diagnosis of traditional Chinese medicine. Comput Methods Programs Biomed. 2018. doi:10.1016/j.cmpb.2018.05.008
22. Choi, E., Schuetz A, Stewart WF, Sun J. Using recurrent neural network models for early detection of heart failure onset. J Am Med Inform Assoc. 2016;24(2):361–370.
23. Busquets S, Carbó N, Almendro V, Figueras M, López-Soriano FJ, Argilés JM. Hyperlipemia: a role in regulating UCP3 gene expression in skeletal muscle during cancer cachexia? FEBS Lett. 2001;505(2):255–258.
24. Rasmy L, Wu Y, Wang N, et al. A study of generalizability of recurrent neural network-based predictive models for heart failure onset risk using a large and heterogeneous EHR data set. J Biomed Inform. 2018;84:11–16. doi:10.1016/j.jbi.2018.06.011
25. Weiskopf NG, Weng C. Methods and dimensions of electronic health record data quality assessment: enabling reuse for clinical research. J Am Med Inform Assoc. 2013;20(1):144–151. doi:10.1136/amiajnl-2011-000681
26. Ben-Assuli O, Sagi D, Leshno M, Ironi A, Ziv A. Improving diagnostic accuracy using EHR in emergency departments: a simulation-based study. J Biomed Inform. 2015;55:31–40. doi:10.1016/j.jbi.2015.03.004
27. Martínez-Costa C, Schulz S. Validating EHR clinical models using ontology patterns. J Biomed Inform. 2017;76:124–137. doi:10.1016/j.jbi.2017.11.001
28. Varpio L, Rashotte J, Day K, King J, Kuziemsky C, Parush A. The EHR and building the patient’s story: a qualitative investigation of how EHR use obstructs a vital clinical activity. Int J Med Inform. 2015;84(12):1019–1028. doi:10.1016/j.ijmedinf.2015.09.004
29. Simard P, Steinkraus D, Platt JC. Best practices for convolutional neural networks applied to visual document analysis. In: Seventh International Conference on Document Analysis and Recognition. 2003. Proceedings, Edinburgh, UK, 2003;958–963. doi:10.1109/ICDAR.2003.1227801.
30. Hsu JH, Chien IC, Lin CH. Increased risk of hyperlipidemia in patients with bipolar disorder: a population-based study. Gen Hosp Psychiatry. 2015;37(4):294–298.
31. Xu C-F, Lin X-R, Wang Y-K. Clinical observation on hyperlipemia treated with antihyperlipidemic decoction. J Tradit Chin Med. 2009;29(2):121–124.
32. Nie C, Zhang F, Ma X, et al. Determination of quality markers of Xuezhiling tablet for hyperlipidemia treatment. Phytomedicine. 2018;44:231–238. doi:10.1016/j.phymed.2018.03.004
33. Denicola DB. Advances in hematology analyzers. Top Companion Anim Med. 2011;26(2):52–61. doi:10.1053/j.tcam.2011.02.001
34. Li C, Ni ZM, Ye LX, Chen JW, Wang Q, Zhou YK. Dose-response relationship between blood lead levels and hematological parameters in children from central China. Environ Res. 2018;164:501–506.
35. Garcia GH, Liu JN, Wong A, et al. Hyperlipidemia increases the risk of retear after arthroscopic rotator cuff repair. J Shoulder Elbow Surg. 2017;26(12):2086–2090. doi:10.1016/j.jse.2017.05.009
36. Kawasaki T, Kambayashi J, Sakon M. Hyperlipidemia: a novel etiologic factor in deep vein thrombosis. Thromb Res. 1995;79(2):147–151.
37. Pradeep KR, Naveen NC. Lung cancer survivability prediction based on performance using classification techniques of support vector machines, C4.5 and Naive Bayes algorithms for healthcare analytics. Proc Comput Sci. 2018;132:412–420. doi:10.1016/j.procs.2018.05.162
38. Faust O, Shenfield A, Kareem M, San TR, Fujita H, Acharya UR. Automated detection of atrial fibrillation using long short-term memory network with RR interval signals. Comput Biol Med. 2018;102:327–335. doi:10.1016/j.compbiomed.2018.07.001
39. Cohen JF, Korevaar DA, Altman DG, et al. STARD 2015 guidelines for reporting diagnostic accuracy studies: explanation and elaboration. BMJ Open. 2016;6(11):e012799. doi:10.1136/bmjopen-2016-012799
 © 2019 The Author(s). This work is published and licensed by Dove Medical Press Limited. The
full terms of this license are available at https://www.dovepress.com/terms
and incorporate the Creative Commons Attribution
- Non Commercial (unported, 3.0) License.
By accessing the work you hereby accept the Terms. Non-commercial uses of the work are permitted
without any further permission from Dove Medical Press Limited, provided the work is properly
attributed. For permission for commercial use of this work, please see paragraphs 4.2 and 5 of our Terms.
© 2019 The Author(s). This work is published and licensed by Dove Medical Press Limited. The
full terms of this license are available at https://www.dovepress.com/terms
and incorporate the Creative Commons Attribution
- Non Commercial (unported, 3.0) License.
By accessing the work you hereby accept the Terms. Non-commercial uses of the work are permitted
without any further permission from Dove Medical Press Limited, provided the work is properly
attributed. For permission for commercial use of this work, please see paragraphs 4.2 and 5 of our Terms.