Back to Journals » Drug Design, Development and Therapy » Volume 20
Pharmacokinetic Model Based on Stochastic Simulation and Estimation for Therapeutic Drug Monitoring of Teicoplanin in Korean Neutropenic Hematopoietic Stem Cell Transplant Recipients
Authors Chae H, Cha HJ, Kang M, Han S ![]() , Lee DG
, Lee DG
Received 21 July 2025
Accepted for publication 16 November 2025
Published 29 January 2026 Volume 2026:20 550736
DOI https://doi.org/10.2147/DDDT.S550736
Checked for plagiarism Yes
Review by Single anonymous peer review
Peer reviewer comments 2
Editor who approved publication: Professor Mariana Carmen Chifiriuc
Hyojin Chae,1 Hwa Jun Cha,2,3 Minji Kang,2,3 Seunghoon Han,2,3 Dong-Gun Lee4,5
1Department of Laboratory Medicine, Seoul St. Mary’s Hospital, College of Medicine, The Catholic University of Korea, Seoul, Korea; 2Department of Pharmacology, College of Medicine, The Catholic University of Korea, Seoul, Korea; 3PIPET (Pharmacometrics Institute for Practical Education and Training), College of Medicine, The Catholic University of Korea, Seoul, Korea; 4Catholic Hematology Hospital, College of Medicine, The Catholic University of Korea, Seoul, Korea; 5Divison of Infectious Diseases, Department of Internal Medicine, College of Medicine, The Catholic University of Korea, Seoul, Korea
Correspondence: Seunghoon Han, Department of Pharmacology, College of Medicine, the Catholic University of Korea, 222, Banpo-Daero, Seocho-Gu, Seoul, 06591, Korea, Tel +82 2 3147 8357, Fax +82 2 2258 7876, Email [email protected] Dong-Gun Lee, Division of Infectious Diseases, Department of Internal Medicine, College of Medicine, The Catholic University of Korea, Banpo-Daero, Seocho-Gu, Seoul, 06591, Korea, Tel +82 10 5019 2105, Fax +82 2 2258 7876, Email [email protected]
Purpose: This study aimed to develop the first population pharmacokinetic (PK) model of teicoplanin for Korean neutropenic patients after hematopoietic stem cell transplantation (HSCT), to improve the precision of therapeutic drug monitoring (TDM) and support individualized dosing strategies.
Patients and Methods: TDM data comprising 568 trough concentrations were retrospectively collected from 405 post-HSCT patients at a single hospital in Korea. Because only trough samples were available, 360 simulated concentration–time points were generated from two Korean PK models at six post-dose timepoints (0.3, 1, 1.5, 2.5, 4, and 6 hr) to supplement the dataset. The combined dataset was analyzed in NONMEM to construct a base model for stochastic simulation and estimation (SSE). Covariates were identified using generalized additive modeling and stepwise covariate selection. Model performance was assessed with bootstrap and prediction-corrected visual predictive checks. Finally, the SSE procedure was implemented, with parameter re-estimation repeated 1000 times to obtain stable estimates despite the trough-only design.
Results: The final model identified creatinine clearance (eGFR) and albumin as significant covariates, reflecting the effects of renal function and protein binding. Model evaluation confirmed robust predictive performance within the 720-hour TDM window, although prediction intervals widened at later times due to sparse data. Based on the SSE procedure, the final clearance estimate was 1.26 L/h, higher than values reported in non-HSCT populations (0.63– 0.69 L/h) and consistent with the elevated mean eGFR in this cohort (113 mL/min/1.73 m²), partially due to reduced muscle mass and altered serum creatinine in HSCT patients.
Conclusion: This SSE-based PK model provides a practical framework for precision TDM of teicoplanin in Korean HSCT patients. By incorporating renal function and protein binding, it supports individualized dosing in this vulnerable population. Prospective validation is warranted to confirm its broader clinical application.
Keywords: teicoplanin, population pharmacokinetics, therapeutic drug monitoring, hematopoietic stem cell transplantation, stochastic simulation and estimation (SSE)
Introduction
Teicoplanin, a glycopeptide antibiotic, is extensively used for treating serious Gram-positive bacterial infections, particularly methicillin-resistant Staphylococcus aureus (MRSA) and enterococci.1 Teicoplanin is favored in the clinical setting due to its strong therapeutic efficacy and comparatively lower toxicity profile relative to vancomycin, which makes it particularly valuable for patients requiring complex and prolonged treatments, such as those undergoing hematopoietic stem cell transplantation (HSCT).2 HSCT patients are highly vulnerable to severe infections, not only because of their immunocompromised status but also due to the cumulative stress from intensive conditioning regimens. This vulnerability makes accurate antimicrobial therapy essential, with teicoplanin being particularly important for preventing life-threatening infections and supporting patient recovery.3,4
Teicoplanin exhibits a high protein binding rate (90–95%) and is primarily excreted unchanged by the kidneys, with minimal hepatic metabolism.5,6 In patients with severe infections, pharmacokinetic (PK) parameters may vary considerably due to pathophysiological changes such as altered renal clearance, hypoalbuminemia, and increased distribution volume.7,8 As these variations complicate infection management, tailoring therapy through therapeutic drug monitoring (TDM) has become a recognized strategy in clinical practice. In Korea, TDM of teicoplanin is commonly performed by monitoring trough concentrations (Cmin) to ensure they remain above a target threshold.4,9 However, the correlation between Cmin and overall exposure may not be reliable in patients with high PK variability, and Bayesian approaches using population PK models are increasingly applied to address this limitation.4,10
For accurate Bayesian TDM, a population-specific PK model tailored to the target patient group is essential. Only a few teicoplanin PK models have been reported in Korean patients, but none have been developed or validated in the HSCT setting. Consequently, TDM in Korean HSCT patients often depends on models derived from other populations, which may compromise predictive accuracy and dosing precision. Despite this knowledge gap, conducting a prospective full-PK study in this population is challenging, given the high disease severity and the intensive blood sampling already required during hospitalization. As a practical alternative, an approach that leverages Cmin data obtained from routine TDM, combined with stochastic simulation and estimation (SSE), provides a feasible way to generate reliable PK information. Developing such a model is essential to improve the reliability of TDM and enable individualized therapy in this high-risk clinical group.
The objective of this study was to develop a PK model specifically for Korean post-HSCT neutropenic patients. Because Cmin data alone are insufficient to construct a reliable model, we supplemented them with simulated datasets generated from two recently published Korean teicoplanin PK models.11,12 However, even with this hybrid dataset, a single estimation may not yield sufficiently stable parameter values. Therefore, we applied an SSE approach, in which repeated simulations and parameter re-estimations allowed us to obtain robust estimates. This strategy provided a reliable foundation for precision TDM of teicoplanin and has the potential to improve infection control and safety outcomes in this vulnerable patient population.
Materials and Methods
Patient Population and Observed Data
TDM data were obtained by retrospectively collecting actual observations of patients treated at the Bone Marrow Transplantation Center (now separated into Catholic Hematology Hospital) at The Catholic University of Korea Seoul St. Mary’s Hospital from 2015 to 2017. The study population was patients aged 18 years and older who were diagnosed with hematologic malignancies, underwent HSCT, were hospitalized for infections, and received teicoplanin. Teicoplanin treatment was selectively administered in the presence of (i) positive gram-positive bacterial cultures, (ii) severe sepsis or shock with pending blood culture results, (iii) history of MRSA infection or colonization, (iv) skin and soft tissue infections, and (v) suspected catheter-related infections. Patients were excluded if it was determined that the PK characteristics of teicoplanin were not representative of the general characteristics of this patient group (eg, receiving massive fluid therapy, renal replacement therapy). No formal prospective sample size calculation was performed; rather, the study included all eligible patients who underwent TDM during the study period, thereby ensuring maximal utilization of available clinical data.
The standard dosing regimen consisted of three loading doses of 400 mg intravenously at 12-hr intervals, followed by a maintenance dose of 400 mg once daily. However, the actual dosing amount was determined at the discretion of physicians, and the standard regimen was not always applied. TDM blood samples were collected approximately one hour before a scheduled dose administration (23 hrs after the last administered dose during the maintenance period), following the general recommendations in Korea as described by Kim et al13 after maintaining a stable dosing regimen for at least 48–96 hours. However, minor variations occurred due to practical constraints in routine clinical practice. In this regard, all actual dosing history and sampling time information were obtained and reflected in the analysis. Samples were analyzed with ultra-high performance liquid chromatography tandem mass spectrometry (UHPLC-MS/MS) in a prior study.14 The calibration range was 3.9–52.9 mg/L. Separately, the lower limit of quantification was validated at 0.72 mg/L, demonstrating the analytical sensitivity of the method and confirming that it can accurately quantify teicoplanin concentrations even below the routine calibration range.14 Demographic data, including weight, height, sex, age, creatinine, and albumin concentrations, were also captured. Estimated glomerular filtration rate (eGFR) was calculated using the CKD-EPI (Chronic Kidney Disease Epidemiology Collaboration) formula.
This research was reviewed and approved by the institutional review board (IRB) of The Catholic University of Korea Seoul St. Mary’s Hospital (KC17SESI0654). The dataset was obtained retrospectively from electronic medical records, during which all subject-identifiable information was removed. As such, the study constituted a retrospective study using anonymized data and the requirement for informed consent was waived by the IRB. This study was conducted in accordance with the Declaration of Helsinki.
Simulated Dataset
Only two previous studies have reported teicoplanin PK models developed specifically for the Korean population.11,12 The first model, a two-compartment model, was derived from a study involving 15 critically ill elderly Korean patients aged 60 years or older. Trough and peak concentrations were measured after multiple doses of teicoplanin, with the dosing intervals adjusted according to renal function.11 The second model, a three-compartment model, was developed based on a full-PK study (8 PK samples taken post-infusion) in 12 healthy Korean individuals who received a single 200 mg dose of teicoplanin.12 Although these populations do not exactly match the patients in the present study, they were considered suitable for generating simulated data for two reasons: i) the simulated dataset was restricted to uninformative timepoints and used only as backbone data for model development, applied consistently across all cases; and ii) the population PK parameter values and covariates were derived from Korean subjects, rather than from disease-specific conditions.
Simulations were conducted to obtain backbone data for model building based on the PK properties of these existing models. Covariates used for calculating PK parameter values included body weight, gender, age, serum creatinine, and eGFR, consistent with those adopted in the published models. To reflect realistic patient characteristics, multivariate normal distributions of these covariates were generated based on the distributions reported in the published Korean PK models. For each simulation run, random sampling was performed to create virtual subjects, ensuring that the number of simulated individuals matched the intended population size.
To keep the resulting model as dependent as possible on the observed TDM data, the number of simulated data points was minimized. Specifically, six early post-dose timepoints (0.3, 1, 1.5, 2.5, 4, and 6 hr) were selected to capture the initial distribution and early disposition phases of teicoplanin, which cannot be adequately characterized by trough-only (Cmin) data. This strategy ensured that essential PK processes were represented while minimizing the influence of simulated data, despite teicoplanin’s long half-life. Furthermore, 30 subjects were simulated from each model (60 subjects in total), which is the minimum sample size required by the central limit theorem to estimate between-subject variability (ω²). Each dataset therefore contained 360 simulated concentrations (6 timepoints × 60 subjects). In this process, between-subject variability reported in the literature was incorporated into the PK parameters, and residual error was reflected according to the original models.
All random sampling and estimation procedures were performed using R (version 4.4.0) with the “tmvtnorm” package (version 1.6.0), and the simulated datasets were subsequently generated in NONMEM (version 7.5, Icon Development Solutions, Ellicott City, MD).
Base Model Building
The first combined dataset of observed and simulated data was used to develop the base model. Population PK analysis was performed using non-linear mixed-effects modeling with NONMEM. The first-order conditional estimation with interaction (FOCE-I) method was used throughout the modeling process. Two- and three-compartment models with first-order elimination were assessed, as these models were used to generate the simulated dataset. The individual variability of each PK parameter was described using a lognormal distribution.
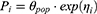
Pi represents the individual parameter, θpop represents the typical parameter value for the population, and ηi is the between-subject variability (BSV), which follows a normal distribution with a mean of zero and a variance of ω2. Possible correlations between the individual variabilities were evaluated using OMEGA BLOCK option. Proportional, additive, and combined error models (ε) were assessed for residual variability, which follows a normal distribution with a mean of zero and a variance of σ2. To identify the optimal structural model, the objective function value (OFV) was used to compare nested models, and the Akaike information criterion (AIC) was used to compare non-nested models. Additional criteria such as goodness-of-fit plots, parameter stability, and parsimony were also comprehensively considered in the final model selection process. Covariate analysis was conducted to evaluate the impact of the potential covariates on the model. Prior to covariate selection, covariate screening was performed using generalized additive models (GAM) and graphical analysis to identify potential covariates. Stepwise covariate modeling in Perl-speaks-NONMEM (PsN, version 5.3.1)15 was then used, which included both forward selection (p<0.05, ΔOFV > 3.84) and backward elimination (p<0.01, ΔOFV > 6.63). Tested covariates included height, weight, sex, albumin, serum creatinine level, and estimated creatinine clearance. Biologically plausible and physiologically relevant covariates were selected for the final base model to ensure clinical relevance and improve the predictive performance of the model.
Base Model Evaluation
The bootstrap method and visual predictive check (VPC) were used to evaluate the final base model. 1000 randomly resampled datasets were generated from the combined dataset. The medians and the 5th and 95th percentiles of 1000 parameter estimates were compared with the original base model parameter estimates. For the VPC, simulations were performed 1000 times, and the results were plotted, comparing the observed concentrations and 90% prediction interval of the simulated concentrations. Both bootstrapping and VPC were performed using PsN (version 5.3.1), NONMEM, and R (version 4.4.0).
Stochastic Simulation and Estimation (SSE) to Obtain Final Parameter Estimates
Using the base model, the process of 1) obtaining simulated data, 2) constructing the dataset by merging with observed data, and 3) estimating parameters through model fitting was repeated 1000 times. The FOCE-I method was used for all estimations. In each estimation output file, it was evaluated whether the minimization was successful and whether the parameter values were reliable, and the proportion of estimation runs that satisfied both conditions was reported. Using only the estimation results that satisfied both conditions, the mean and 90% confidence intervals of the parameter estimates were presented along with the relative standard error (RSE).
Predictive Performance Evaluation for the Final Model
To assess the final model and estimated parameters from SSE, a prediction-corrected visual predictive check (pcVPC) was performed.16 Traditional VPC can be affected by binning across a large variability in dose and/or influential covariates, leading to misinterpretation of the data. Also, it can be inaccurate when used with adaptive designs, such as dose adjustments. Therefore, the presence of different dosing regimens, sampling times, and covariate values in the combined dataset makes pcVPC the appropriate method to evaluate instead of traditional VPC. pcVPC enables correction of the variability coming from binning across the independent variables such as dose, time, and covariate by normalizing the dependent variables based on the typical population prediction. The formula for population prediction correction is as follows:
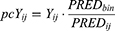
pcYij is the prediction-corrected observation or prediction for the ith individual and jth time point, Yij is the observation or prediction for the ith individual and jth time point, PREDbin is the median of typical population predictions for the specific bin of independent variables, and PREDij is the typical population prediction for the ith individual and jth time point. Only observed data were utilized in the pcVPC procedure, not the actual dosing history. Because of the unevenly distributed sampling time points throughout the sampling period, the binning was manually set to 32 bins, considering the dosing and observed time.
Results
Observed Dataset
A total of 417 individuals (222 males and 195 females) who underwent teicoplanin TDM were initially included in the analysis. After excluding 12 patients with missing covariate values and one patient with an erroneously recorded concentration, the final observed dataset comprised 405 patients with 568 valid observations. Sampling times ranged from 19 to 2879 hours after the first dose, yielding 581 teicoplanin concentration measurements. Among these, data records from patients with a regimen maintenance period of less than 48 hours accounted for 7.6%, and the latest sample was collected 47 hours after the final dose. The baseline characteristics of these patients are summarized in Table 1.
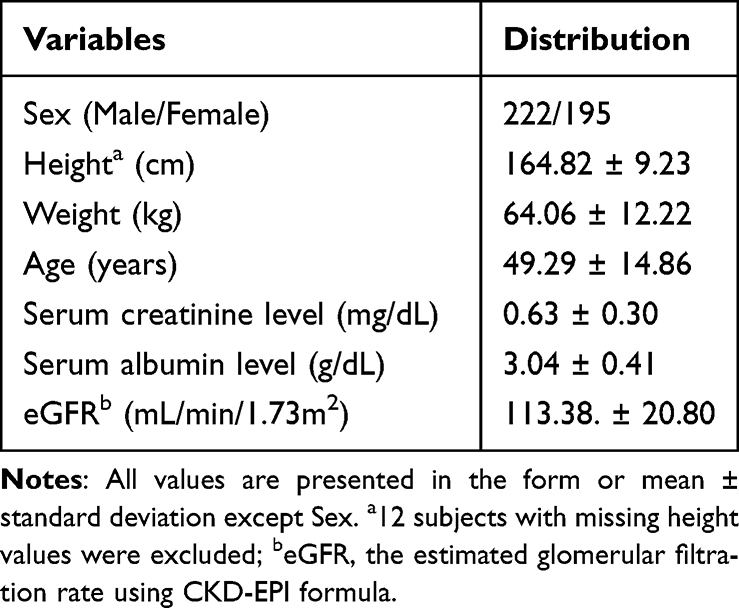 |
Table 1 Demographics of Study Patients |
Base Model and Evaluation Outcomes
Because the simulated dataset inherently contained early timepoints that required at least a two-compartment structure, both two- and three-compartment models were evaluated during base model development. The three-compartment model produced superior results in terms of diagnostic criteria, including a lower OFV as well as better normality and homoscedasticity. However, not all patients were adequately described by the three-compartment structure, and a substantial proportion could be sufficiently explained by a two-compartment model alone. In the SSE procedure, where subject-level random sampling is repeated, the inclusion of such individuals increased the likelihood of convergence failure when using the three-compartment model. Therefore, despite acknowledging some degree of structural misspecification, the two-compartment model was selected as the final base structure because it provided more stable and reliable parameter estimation across repeated simulations (Figure 1). Larger weighted residuals were observed at higher concentrations, but this was considered unavoidable given the limited number of such samples and the variability inherent in routine clinical sampling.
 |
Figure 1 Basic goodness-of-fit plots of the base population PK model. Each panel displays four standard diagnostic plots. Top left (A) is a scatterplot of observed concentrations versus population predictions (PRED). Top right (B) is a scatterplot of observed concentrations versus individual predictions (IPRED). Bottom left (C) is a scatterplot of individual weighted residuals (IWRES) versus IPRED. Bottom right (D) is a scatterplot of conditional weighted residuals (CWRES) versus time. The circles indicate the observed or predicted plasma concentration of teicoplanin (mg/L). The black line and red line indicate the line of identity, and locally weighted scatterplot smoothing line, respectively. |
Among the two-compartment models, the model with BSV on CL and V2 had the lowest OFV and was selected as the base structural model. As a result of forward selection and backward elimination in stepwise covariate modeling, eGFR and albumin were identified as potential covariates for CL. Considering biologically plausible and physiologically relevant covariates, eGFR and albumin were selected as final covariates. A comparison of the fit statistics (minimized OFV) by model structure is presented in Table 2.
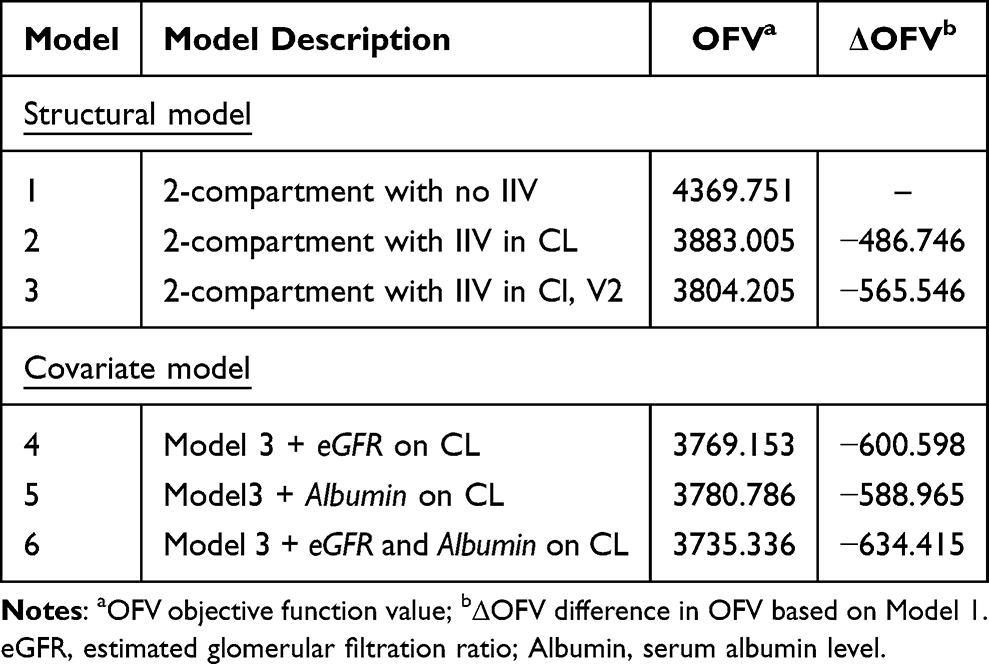 |
Table 2 Comparison of Structural Model |
Bootstrap evaluation showed that most of the estimations were completed successfully, and no particular problems were found with the point estimates and interval estimates of the parameters. In addition, VPC results showed that the model reproduces the trend of the dataset well enough, although there is some variation depending on the density of the data at each time point (Figure 2). This confirmed that the final model satisfied the basic requirements for a base model for SSE analyses. The final base model PK parameter estimates and bootstrap results are summarized in Table 3.
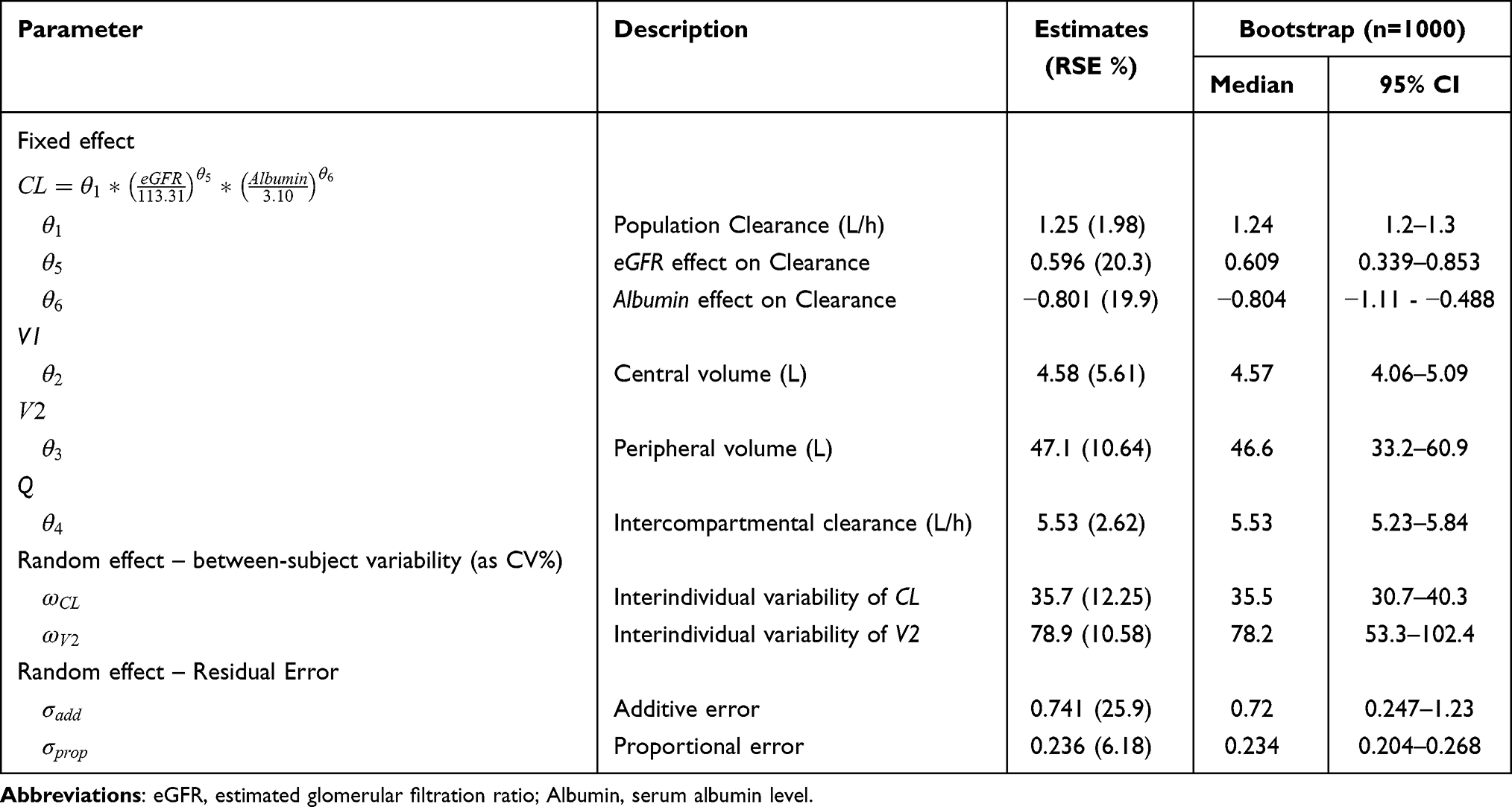 |
Table 3 Parameter Estimates of Base Pharmacokinetic Model with Bootstrap Results |
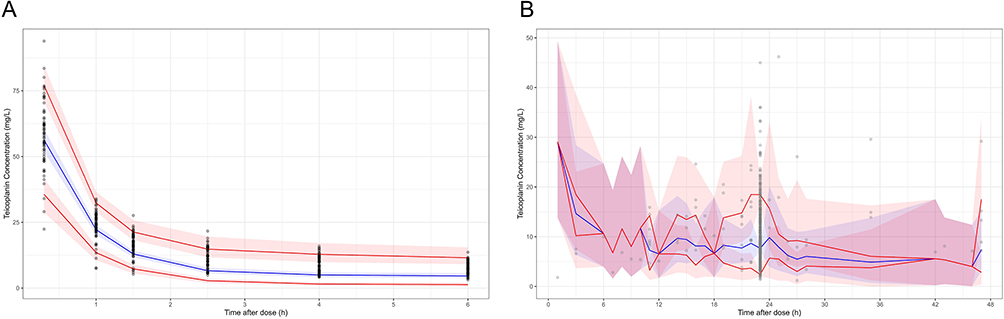 |
Figure 2 VPC plots for the base model. (A) Simulated data (B) Observed TDM data. All time points were converted to time after dose. Simulated data and observed trough concentrations are depicted as gray dots. The figure presents the VPC with the prediction intervals for the 5th, 50th, and 95th percentiles of simulations from bottom to top. The solid lines correspond to 5th, 50th, and 95th percentiles. The red shaded areas correspond to the 95th confidence interval of the 5th and 95th percentile. The blue shaded area corresponds to the 95th confidence interval of the 50th percentile. |
Final Model From SSE Procedures
Out of 1000 SSE runs, the total number of cases where the estimation was not done properly (minimization failure, parameter near boundary, or rounding error) was 11.9% (88.1% of successful runs). The bias of the mean parameter estimates, calculated from the successful runs relative to the final estimates of the base model, was not significant. The RSEs ranged from 0.522% to 8.88% depending on the parameters. In particular, the RSEs for CL and V2 were 2.09% and 6.81%, respectively, which were deemed to have sufficient reliability to be used for post hoc parameter (empirical Bayesian estimate) estimation. The final PK parameter estimates are summarized in Table 4. The plot of pcVPC results (Figure 3) using the final model parameters obtained from SSE demonstrates that the PK model is capable of accurately reproducing the observed trend, reflecting the actual dosing history and sampling time. Notably, the predictive performance was optimal within the range of 720 hours from the first dose, which coincides with the primary period for TDM procedures. However, the prediction interval exhibited some inflation in the later time ranges, where the data became increasingly sparse.
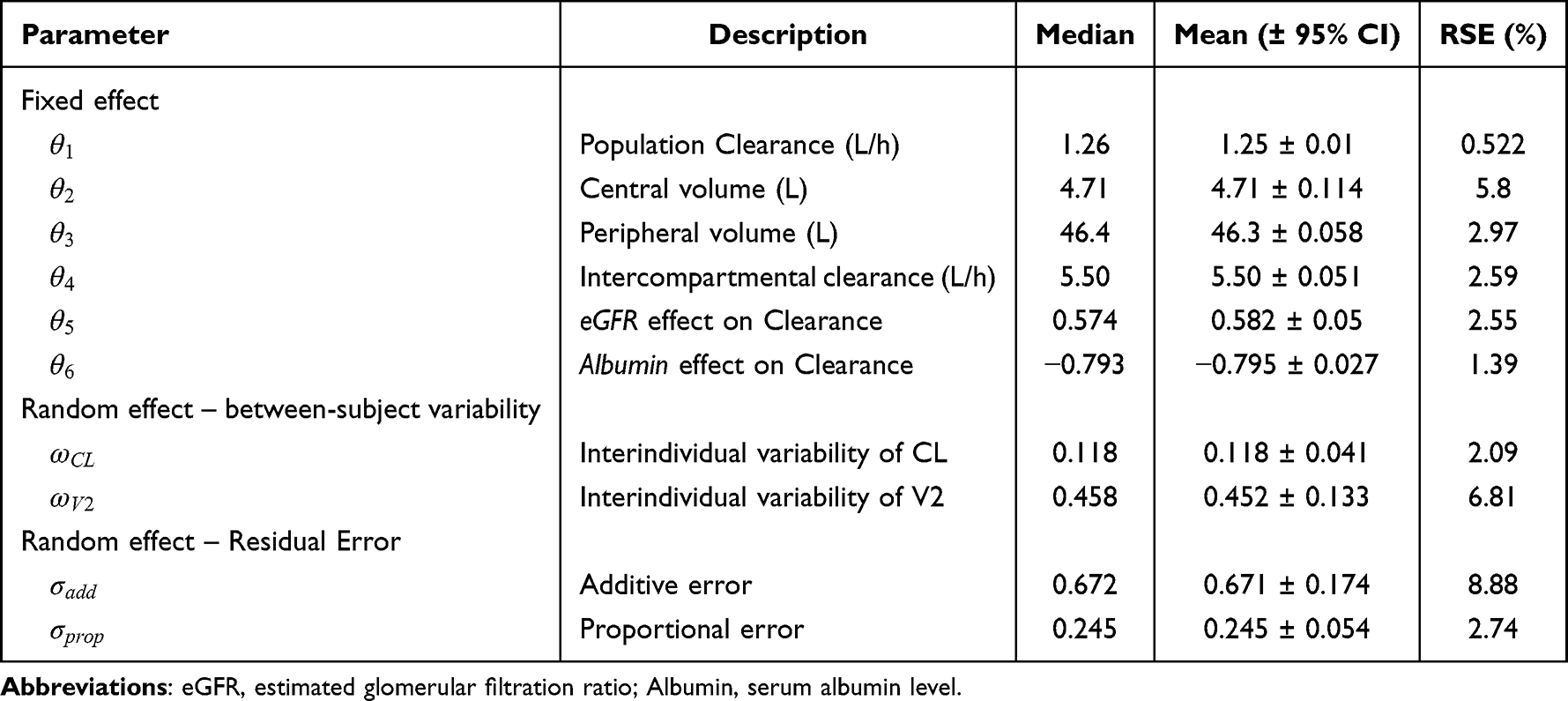 |
Table 4 Parameter Estimates of the Final Pharmacokinetic Model Using SSE (N = 1000) |
 |
Figure 3 pcVPC plots for the final model. (A) Data up to 720 hours. (B) Data after 720 hours. Solid red line represents the median of prediction corrected concentration (mg/L), and semitransparent red field represents a simulation-based 95% confidence interval for the median. The observed 10% and 90% percentiles are presented with blue dashed lines, and the 95% confidence intervals for the corresponding simulation-based percentiles are shown as semitransparent blue fields. Black dots are the prediction-corrected observed concentrations. |
Discussion
In this study, we developed a population PK model of teicoplanin specifically for Korean HSCT patients with neutropenia, providing the first population-specific parameter estimates in this setting. The model was further refined by identifying eGFR and albumin as covariates of clearance, which strengthens its clinical relevance for individualized dosing. By applying the SSE approach, we overcame the limitation of relying solely on Cmin data and achieved stable parameter estimation. The adequacy of this methodology was demonstrated through the satisfactory predictive performance of the final two-compartment model for observed concentrations across various dosing histories. Taken together, these results indicate that the model can improve the reliability of TDM in Korean HSCT patients, particularly within the clinically relevant timeframes in which teicoplanin monitoring is usually performed.
The two published Korean studies that informed our simulations employed two- and three-compartment models, respectively, explaining some of the parameter similarities with our results. V1 was estimated at 4.71 L, close to values reported previously (4.79 and 3.96 L), indicating that the simulated dataset adequately fulfilled its intended role in model development. By contrast, clearance was estimated at 1.26 L/h, nearly double the values reported in the earlier studies (0.63 and 0.69 L/h). Because our analysis assumed the same distribution characteristics, the larger clearance estimate indicates that HSCT recipients had lower Cmin than prior populations. When a model derived from a reference population is applied to this study population, observed concentrations are therefore likely to be consistently lower than the predicted values. As a result, Bayesian TDM based on such external models may yield theoretical Cmin values that are higher than those actually observed. This in turn reduces the likelihood of appropriate upward dose adjustment. Our model instead provides a basis for Bayesian TDM that mitigates this systematic bias and supports more reliable individualized dosing in HSCT patients.
This finding illustrates the significance of population specificity in PK modeling. Even within the Korean population, models developed in patient groups without neutropenia or HSCT are unlikely to capture the PK characteristics of our study cohort. Likewise, although models have been reported in other ethnic groups with hematologic malignancies and neutropenia, the documented inter-ethnic variability in glycopeptide PK raises serious concerns about their applicability to Korean patients.17,18 Applying such externally developed models without rigorous validation carries a substantial risk of systematic bias and clinically inappropriate predictions, particularly for clearance estimates and covariate–parameter relationships.19 Therefore, although the use of SSE with simulated data represents only a provisional approach, the development of population-specific PK models in groups where dense PK sampling is rarely feasible due to clinical and ethical constraints can nonetheless be regarded as methodologically sound and contributes to the establishment of clinically relevant TDM strategies.
The covariates identified in our model were consistent with those reported in the literature and were deemed appropriate for representing the known PK properties of teicoplanin. The higher mean eGFR in our population (113 mL/min/1.73 m² compared with 64 and 103 in the literature) may have partially contributed to the greater clearance estimate, plausibly reflecting the reduced muscle mass and lower serum creatinine levels commonly observed in HSCT patients.20 The between-subject variability was larger than that reported previously but remained within a reasonable range, which can be explained by the heterogeneous nature of the HSCT population. These results indicate that the final model was not solely dependent on such data and adequately reflected the characteristics of the TDM patient cohort.
The present study was partially based on existing PK models derived from a Korean population, which may not fully align with the specific characteristics of post-HSCT neutropenic patients targeted in this analysis. This is because reliance on external datasets introduces potential variability that may not be fully representative of this population. In addition, an increased distribution volume may have contributed to the lower trough concentrations observed, but due to the limited information these effects were primarily reflected in clearance, which may have led to its overestimation. Taken together, these factors highlight a degree of uncertainty regarding the model’s ability to fully capture the distinctive PK profile of teicoplanin in this patient group. Future studies incorporating sparse sampling and real-world data on covariates (eg, CKD-EPI-based eGFR and serum albumin levels) from post-HSCT neutropenic patients will be essential to validate the model, improve its accuracy, and enable further optimization of individualized dosing strategies.
Conclusion
This study developed the first population PK model of teicoplanin tailored to Korean HSCT patients with neutropenia. The model provided population-specific parameter and variability estimates and identified eGFR and albumin as clinically relevant covariates of clearance. By applying the SSE approach, we were able to overcome the limitation of trough-only data and obtain stable parameter estimates. The final two-compartment model demonstrated satisfactory predictive performance within the clinically relevant timeframe for TDM, offering a reliable basis for individualized dosing in this vulnerable group. Although our approach relied partly on simulated data, the results underscore the value of developing population-specific models in populations where dense PK sampling is rarely feasible. Future studies incorporating real-world covariates and sparse sampling will be essential to validate and refine this model to further support safe and effective teicoplanin therapy in HSCT patients.
Disclosure
The author(s) report no conflicts of interest in this work.
References
1. Paritala ST, Gandhi G, Agrawal K, Sengupta P, Sharma N. Glycopeptides: insights towards resistance, clinical pharmacokinetics and pharmacodynamics. Indian J Microbiol. 2024;1–11.
2. Kato‐Hayashi H, Niwa T, Ohata K, et al. Comparative efficacy and safety of vancomycin versus teicoplanin in febrile neutropenic patients receiving hematopoietic stem cell transplantation. J Clin Pharm Therapeutics. 2019;44(6):888–894. doi:10.1111/jcpt.13011
3. George B, Bhattacharya S. Infections in hematopoietic stem cell transplantation (HSCT) patients. Contemporary Bone Marrow Transplant. 2021;545–560.
4. Hanai Y, Takahashi Y, Niwa T, et al. Clinical practice guidelines for therapeutic drug monitoring of teicoplanin: a consensus review by the Japanese society of chemotherapy and the Japanese society of therapeutic drug monitoring. J Antimicrob Chemother. 2022;77(4):869–879. doi:10.1093/jac/dkab499
5. Aulin L, De Paepe P, Dhont E, et al. Population pharmacokinetics of unbound and total teicoplanin in critically ill pediatric patients. Clin Pharmacokinet. 2021;60:353–363. doi:10.1007/s40262-020-00945-4
6. Inno Y, Taogoshi T, Matsumoto A, et al. Evaluation of teicoplanin protein-binding variability and clinical utility of its free serum concentration measurement. Sci Rep. 2025;15:31546. doi:10.1038/s41598-025-17321-6
7. Brink A, Richards G, Lautenbach E, et al. Albumin concentration significantly impacts on free teicoplanin plasma concentrations in non-critically ill patients with chronic bone sepsis. Int J Antimicrob Agents. 2015;45(6):647–651. doi:10.1016/j.ijantimicag.2015.01.015
8. Tanaka R. Pharmacokinetic variability and significance of therapeutic drug monitoring for broad-spectrum antimicrobials in critically ill patients. J Pharm Health Care Sci. 2025;11(1):21. doi:10.1186/s40780-025-00425-6
9. Wang Y-W, Hou H-A, Lin -C-C, et al. Early therapeutic drug monitoring optimizes teicoplanin use in febrile neutropenic patients with hematological malignancies. Adv Ther. 2024;1–12.
10. Emoto C, Johnson TN, Yamada T, Yamazaki H, Fukuda T. Teicoplanin physiologically based pharmacokinetic modeling offers a quantitative assessment of a theoretical influence of serum albumin and renal function on its disposition. Eur J Clin Pharmacol. 2021;77:1157–1168. doi:10.1007/s00228-021-03098-w
11. Kang SW, Jo HG, Kim D, et al. Population pharmacokinetics and model-based dosing optimization of teicoplanin in elderly critically ill patients with pneumonia. J Crit Care. 2023;78:154402. doi:10.1016/j.jcrc.2023.154402
12. Kim Y-K, Jo K-M, Lee J-H, et al. Beyond one-size-fits-all: tailoring teicoplanin regimens for normal renal function patients using population pharmacokinetics and monte carlo simulation. Pharmaceutics. 2024;16(4):499. doi:10.3390/pharmaceutics16040499
13. Kim S-H, Lee S-Y, Kang C-I. Appropriate use of glycopeptide antibiotics and therapeutic drug monitoring for invasive infections. Korean J Med. 2021;96(6):463–477. doi:10.3904/kjm.2021.96.6.463
14. Chae H, Lee JJ, Cha K, et al. Measurement of teicoplanin concentration with liquid chromatography-tandem mass spectrometry method demonstrates the usefulness of therapeutic drug monitoring in hematologic patient populations. Ther Drug Monitoring. 2018;40(3):330–336. doi:10.1097/FTD.0000000000000498
15. Lindbom L, Pihlgren P, Jonsson EN. PsN-Toolkit--a collection of computer intensive statistical methods for non-linear mixed effect modeling using NONMEM. Comput Methods Programs Biomed. 2005;79(3):241–257. doi:10.1016/j.cmpb.2005.04.005
16. Bergstrand M, Hooker AC, Wallin JE, Karlsson MO. Prediction-corrected visual predictive checks for diagnosing nonlinear mixed-effects models. AAPS J. 2011;13:143–151. doi:10.1208/s12248-011-9255-z
17. Byrne C, Roberts J, McWhinney B, et al. Population pharmacokinetics of teicoplanin and attainment of pharmacokinetic/pharmacodynamic targets in adult patients with haematological malignancy. Clin Microbiol Infect. 2017;23(9):674.e7–674.e13. doi:10.1016/j.cmi.2017.02.032
18. Mouton JW, De Clercq A, De Paepe P, et al. Pharmacokinetics and target attainment of teicoplanin: a systematic review. Clin Pharmacokinet. 2025;64:1–43. doi:10.1007/s40262-024-01459-z
19. Baklouti S, Marolleau S, Chavanet P, Bonnet E, Concordet D, Gandia P. Why is it desirable to do the external evaluation of a population pharmacokinetic model? Antimicrob Agents Chemother. 2022;66(1):e01493–21. doi:10.1128/AAC.01493-21
20. Takekiyo T, Morishita S. Exercise therapy on muscle mass and physical function in patients undergoing allogeneic hematopoietic stem cell transplantation. In: Physical Therapy and Research in Patients with Cancer. Springer; 2023:163–190.
 © 2026 The Author(s). This work is published and licensed by Dove Medical Press Limited. The
full terms of this license are available at https://www.dovepress.com/terms
and incorporate the Creative Commons Attribution
- Non Commercial (unported, 4.0) License.
By accessing the work you hereby accept the Terms. Non-commercial uses of the work are permitted
without any further permission from Dove Medical Press Limited, provided the work is properly
attributed. For permission for commercial use of this work, please see paragraphs 4.2 and 5 of our Terms.
© 2026 The Author(s). This work is published and licensed by Dove Medical Press Limited. The
full terms of this license are available at https://www.dovepress.com/terms
and incorporate the Creative Commons Attribution
- Non Commercial (unported, 4.0) License.
By accessing the work you hereby accept the Terms. Non-commercial uses of the work are permitted
without any further permission from Dove Medical Press Limited, provided the work is properly
attributed. For permission for commercial use of this work, please see paragraphs 4.2 and 5 of our Terms.
Recommended articles
A Comprehensive Analysis of Teicoplanin Population Pharmacokinetic Models in Pediatric Populations: Age-Dependent Variability and Implications for Dose Optimization
Yu B, Wan Y, Ji W, Mao J, Zhang R, Shen Z, Hu Y, Cai H
Infection and Drug Resistance 2025, 18:5529-5548
Published Date: 27 October 2025
A Step Toward Precision Dosing of Escitalopram in Chinese Patients: An External Evaluation of Published Population Pharmacokinetic Models
Yan K, Xie X, Shao Q, Wang N, Yang M
Drug Design, Development and Therapy 2025, 19:10937-10951
Published Date: 11 December 2025
Population Pharmacokinetics of Tiapride in Children and Adolescents with Tic Disorders: Leveraging Plasma and Saliva Concentration to Guide Individualized Dosing
Huang W, Shen J, Luo X, Wu Y, Zheng Y, Zhou J, Xu B, Yin X, Wu X
Drug Design, Development and Therapy 2026, 20:587387
Published Date: 21 April 2026