Back to Journals » Pragmatic and Observational Research » Volume 10
Integrating Machine Learning With Microsimulation to Classify Hypothetical, Novel Patients for Predicting Pregabalin Treatment Response Based on Observational and Randomized Data in Patients With Painful Diabetic Peripheral Neuropathy
Authors Alexander Jr J ![]() , Edwards RA, Manca L
, Edwards RA, Manca L ![]() , Grugni R
, Grugni R ![]() , Bonfanti G, Emir B, Whalen E, Watt S, Brodsky M, Parsons B
, Bonfanti G, Emir B, Whalen E, Watt S, Brodsky M, Parsons B ![]()
Received 4 May 2019
Accepted for publication 15 October 2019
Published 31 October 2019 Volume 2019:10 Pages 67—76
DOI https://doi.org/10.2147/POR.S214412
Checked for plagiarism Yes
Review by Single anonymous peer review
Peer reviewer comments 2
Editor who approved publication: Professor David Price
Joe Alexander Jr,1,* Roger A Edwards,2,* Luigi Manca,3 Roberto Grugni,3 Gianluca Bonfanti,3 Birol Emir,4 Ed Whalen,4 Steve Watt,1 Marina Brodsky,5 Bruce Parsons6
1Global Medical Affairs, Pfizer Inc, New York, NY 10017, USA; 2Health Services Consulting Corporation, Boxborough, MA 01719, USA; 3Fair Dynamics Consulting, SRL, Milan, Italy; 4Global Statistics, Pfizer Inc, New York, NY 10017, USA; 5Global Medical Affairs, Pfizer Inc, Groton, CT 06340, USA; 6Global Medical Product Evaluation, Pfizer Inc, New York, NY 10017, USA
*These authors contributed equally to this work
Correspondence: Roger A Edwards
Health Services Consulting Corporation, 169 Summer Road, Boxborough, MA 01719, USA
Tel +1 508472-0406 Fax +1 978264-0713
Email [email protected]
Purpose: Variability in patient treatment responses can be a barrier to effective care. Utilization of available patient databases may improve the prediction of treatment responses. We evaluated machine learning methods to predict novel, individual patient responses to pregabalin for painful diabetic peripheral neuropathy, utilizing an agent-based modeling and simulation platform that integrates real-world observational study (OS) data and randomized clinical trial (RCT) data.
Patients and methods: The best supervised machine learning methods were selected (through literature review) and combined in a novel way for aligning patients with relevant subgroups that best enable prediction of pregabalin responses. Data were derived from a German OS of pregabalin (N=2642) and nine international RCTs (N=1320). Coarsened exact matching of OS and RCT patients was used and a hierarchical cluster analysis was implemented. We tested which machine learning methods would best align candidate patients with specific clusters that predict their pain scores over time. Cluster alignments would trigger assignments of cluster-specific time-series regressions with lagged variables as inputs in order to simulate “virtual” patients and generate 1000 trajectory variations for given novel patients.
Results: Instance-based machine learning methods (k-nearest neighbor, supervised fuzzy c-means) were selected for quantitative analyses. Each method alone correctly classified 56.7% and 39.1% of patients, respectively. An “ensemble method” (combining both methods) correctly classified 98.4% and 95.9% of patients in the training and testing datasets, respectively.
Conclusion: An ensemble combination of two instance-based machine learning techniques best accommodated different data types (dichotomous, categorical, continuous) and performed better than either technique alone in assigning novel patients to subgroups for predicting treatment outcomes using microsimulation. Assignment of novel patients to a cluster of similar patients has the potential to improve prediction of patient outcomes for chronic conditions in which initial treatment response can be incorporated using microsimulation.
Clinical trial registries: www.clinicaltrials.gov: NCT00156078, NCT00159679, NCT00143156, NCT00553475.
Keywords: coarsened exact matching, hierarchical cluster analysis, time series regressions, agent-based modeling and simulation, machine learning
Plain Language Summary
Patients respond differently to the same treatments for chronic pain, which can make it difficult to select the best treatment for an individual patient. Clinicians must rely on evidence from care delivered in real-world conditions (observational data) and from randomized clinical studies that were designed to evaluate the cause and effect relationship of a drug treatment using stringent predefined patient selection criteria. This article discusses an analysis of an observational study of patients treated with pregabalin for painful diabetic peripheral neuropathy (a chronic pain condition that results from diabetes-related nerve damage). Data from randomized clinical trials were used to enrich the observational study data, using statistical techniques and simulation to predict the potential therapeutic responses of individual patients to pregabalin treatment. Predicting responses of patients who are similar (but not identical) to the patients in the original studies would enable better use of existing data. To this end, we identified how to accomplish this by combining two “machine learning” techniques (i.e., a computer-based modeling approach that analyzes patterns without specific instructions in order to “learn” and draw a conclusion). The analyses demonstrated the feasibility and potential application of how machine learning techniques can be used to learn more from observational and randomized data.
Introduction
With the increasing knowledge about patient variations in treatment responses, the expectations and resources dedicated to understanding this variability are growing, with the hope of delivering better and more individualized care.1 Electronic health records, biomarkers, and patient-generated data (eg, related to lifestyle choices) are widely available, but effective approaches must be designed to integrate, understand, and interpret these overwhelming amounts of patient data.2 Proper analyses of these data may potentially assist in identifying patient characteristics and patterns predictive of treatment responses and outcomes. The “Triple Aim” goals are to improve population health,3 enhance patients’ experiences of care, and reduce the cost of care per capita.4 The use of classification, data mining, and predictive analytic techniques has begun to explore questions related to these aims.1,2 To further the clinical application of these large amounts of data, techniques could be used to blend evidence-based medicine from traditional randomized clinical trial (RCT) sources together with observational “big data” methods.2 Since evidence from observational data focuses on external validity that supports confidence about the relevance of a specific treatment choice, inference about cause-and-effect relationships related to that treatment choice is more challenging.5 If the strengths of observational data could be combined with those of RCT data (which are designed to achieve internal validity), then their respective weaknesses can be reduced. Integrating both types of data quantitatively offers a way to reduce the covariate bias (one of the notable shortfalls of observational data), while still incorporating one of its core strengths related to external validity. That goal guided our analytical and prediction efforts.
Pregabalin is an α2δ ligand that is currently approved in the United States for treating neuropathic pain related to diabetic peripheral neuropathy (pDPN) and spinal cord injury, as well as postherpetic neuralgia (PHN), fibromyalgia, and as an adjunctive therapy for partial onset seizures.6 It is also approved in multiple other countries as well for treating neuropathic pain, partial onset seizures (as adjunctive therapy), and generalized anxiety disorder.7 Previously, we used hierarchical cluster analyses, coarsened exact matching (CEM), and cluster-specific time-series regressions with lagged variables as inputs to identify profiles that might be associated with treatment response outcomes in patients treated with pregabalin for pDPN.8 We then incorporated them into an agent-based modeling and simulation (ABMS) platform that enabled various applications.5 Applied to pDPN, ABMS provides a mechanism for comparing a novel patient’s baseline characteristics against the cluster characteristics, to predict trajectories for treatment response (eg, reductions in pain levels or changes in responder status over time). In addition, such microsimulation has the potential for use to evaluate the impact on outcomes of changes in certain variables over time (eg, pain, pain-related sleep interference, dosing and titration strategies).8–10 Such simulation approaches may address the considerable heterogeneity of patients with pDPN, which may affect the response to pregabalin. However, specific methods for how best to address patient heterogeneity are lacking. Promising approaches to treatment optimization in the context of this patient heterogeneity may be identified more efficiently through integration of non-randomized data with randomized data.
To improve prediction of patient pain outcomes in response to treatment, a strict alignment method was used in the first generation of this work.11 That work factored in variables such as age, gender, body mass index (BMI), pDPN duration group (5-year increments), medical history or presence of depression, previous use of gabapentin, pregabalin monotherapy, and pain and pain-related sleep interference at baseline. For pain and pain-related sleep interference at baseline, we used six categories based on a 0–10 numeric rating scale with higher values indicating more severe levels of pain or sleep interference: 0–1, 2–3, 4–5, 6–7, 8–9, and 10. This assignment to a cluster then triggered which time-series regression (with lagged variables as inputs) would be applied to simulate pain levels for each novel patient being considered. Although we considered these results promising, they underscored the need to identify the techniques to expand the alignment criteria to predict the responses of a broader array of potential patients without reducing predictive accuracy (data on file).
The objective of this study was to identify, implement, and evaluate machine learning methods as tools to predict novel, individual patient responses to pregabalin for the treatment of patients with pDPN, utilizing an ABMS platform that integrates data from one large German observational study (OS) and nine RCTs described in detail elsewhere.8 The key steps are summarized in Figure 1. The current work focuses on improvements to Step 2 of the overall prediction effort. More details on other steps in the overall prediction process—including candidate predictors—are published elsewhere.8
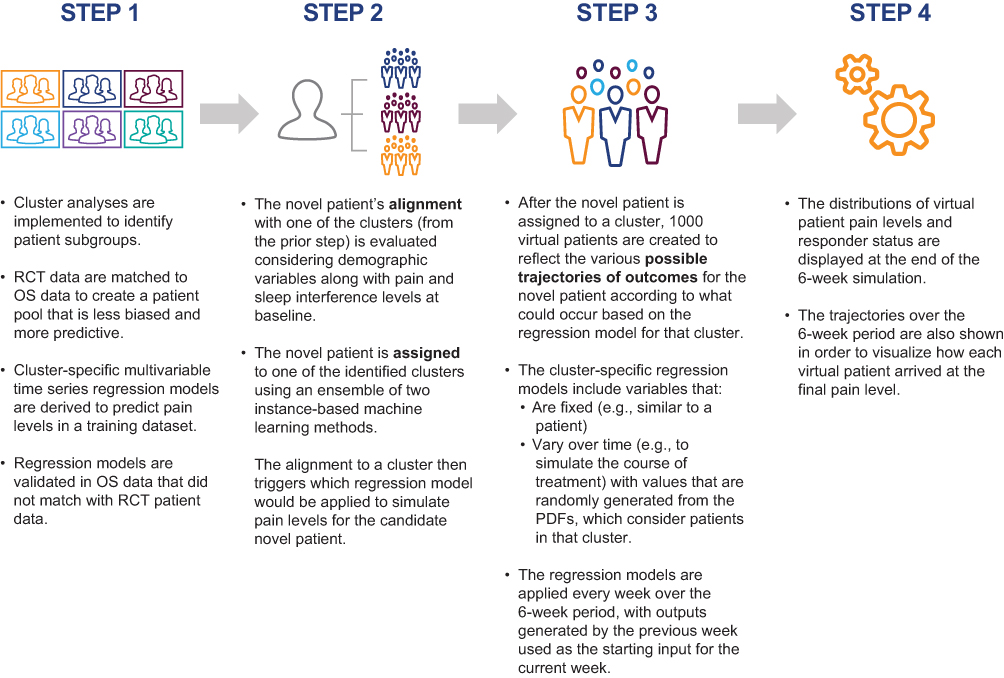 |
Figure 1 Simulation steps. Reproduced from Alexander J, Edwards RA, Brodsky M, et al Using time-series analysis approaches for improved prediction of pain outcomes in subgroups of patients with painful diabetic peripheral neuropathy. PLoS One. 2018;13(12):e0207120. Creative commons license and disclaimer available from http://creativecommons.org/licenses/by/4.0/legalcode.8Abbreviations: OS, observational study; PDF, probability density function; RCT, randomized controlled trial. |
Materials And Methods
To identify the suitability of different machine learning approaches, we examined the literature on other studies that used these methods in subjects with pDPN. Kazemi et al used a multi-category support vector machine (SVM) model to predict the severity of diabetic neuropathy, with about 76% accuracy.12 Rubio and Castillo used various SVM and artificial neural network (ANN) methods to examine pulse-wave sequences of blood volume, in order to improve the classification and prediction of diabetic neuropathy with 100% accuracy.13 Published literature also includes a summary of various machine learning techniques that have been used to identify diabetic patients14 as well as a systematic review of the applications of machine learning, data mining techniques, and tools in the field of diabetes research with respect to prediction and diagnosis, diabetic complications, genetic background and environment, and healthcare and management.15 The latter review noted that ~85% of the analyses used supervised approaches and that the accuracy of the algorithm depended heavily on the type of data (dimensionality, origin, and kind) and preprocessing of the data (eg, feature selection) accordingly. Emir et al used a spectrum of modern analytic techniques for evaluation of clinical and demographic characteristics of patients with pDPN to identify potential predictors of treatment response to pregabalin.16 Since we could find no suitable precedents matching our goals, we focused our efforts on reviewing the effectiveness of supervised machine learning algorithms with different types of data (see review by Kavakiolis et al15) in order to identify the best technique for assigning a patient with pDPN to a cluster of sufficiently similar patients to predict his/her pain outcomes. Five types of supervised machine learning algorithms were examined: logic-based (eg, decision trees, such as Random Forest,17 rule learners18), perception-based (eg, ANNs,19 radial basis function networks20), statistical learning (eg, Naive Bayes, Bayesian networks18), non-linear interpolators (eg, SVM21), and instance-based (eg, k-nearest neighbors [kNN], supervised fuzzy c-means [SFCM]22).
Based on our review, we chose instance-based methods for this analysis because of their better performance with mixed types of data (dichotomous, categorical, continuous), as others have noted.23 We also selected machine learning methods that were deterministic and more transparent for clinicians. We assessed a novel patient’s alignment with a cluster based on three approaches: (1) the kNN method alone, (2) the SFCM method alone, and (3) the combination of the kNN and SFCM together (hereon labeled as the “ensemble method”). We used a training dataset and a testing dataset that were derived from prior work.8 This analysis used data from nine placebo-controlled, multicenter, international RCTs, which evaluated the efficacy of pregabalin (flexible- or fixed-dose pregabalin in doses of 75, 150, 300, or 600 mg/day for 5–13 weeks) for treatment of pDPN (data on file for study A0081071; www.clinicaltrials.gov registration numbers: NCT00156078, NCT00159679, NCT00143156, and NCT00553475; the other trials were not registered on www.clinicaltrials.gov).24–31 The OS data were from a 6-week, open-label study in standard outpatient settings in Germany,32 wherein physicians were free to prescribe pregabalin 150–600 mg/day as either monotherapy or add-on therapy for the treatment of neuropathic pain, in accordance with the European Medicine Agency’s Summary of Product Characteristics dosing schedule.7 The training dataset included those patients from the OS group who matched with patients from nine RCTs based on the following variables: gender, age group, BMI group, baseline pain score, and baseline pain-related sleep interference score. The testing dataset consisted of those patients in the OS dataset who had not matched with RCT patients.
The kNN approach defines “closest” based on considering patients as vectors and calculating the Euclidean distance between the novel patient and the patients in the cluster, according to the considered variables. Then, the patients are sorted from the nearest to the farthest. There is not an absolute cutoff based on Euclidean distance. Rather, the subgroup of patients within the nearest cluster is defined based on the “k” patients (where “k” is the square root of the dataset’s size) who are closest and based on whichever Euclidean distances are associated with these “k” patients. We selected this option after systematically evaluating different values for k. The kNN approach also assigned a patient to a cluster, by not selecting clusters that would not be applicable to that patient (eg, if the patient is male, then the all-female clusters could not be considered for assigning that patient).
The SFCM approach belongs to the broader class of fuzzy clustering algorithms. In contrast to “hard” or “non-fuzzy” methods, each data point in fuzzy classifiers (in this case, consisting of the novel patient to be assigned) can belong to more than one cluster, and this relationship is assessed by a certain degree of membership (ie, the degree of membership of the novel patient to each of the existing clusters). SFCM completes the unsupervised learning of fuzzy c-means with labeled patterns (eg, training dataset), incorporated additively as a part of the objective function, which is defined as the sum of distances between the features and the corresponding clusters’ centers. The SFCM algorithm is an iterative process that comes to convergence when the difference between two objective functions, measured in two consecutive iterations, is negligible (by convention, negligible is defined as a difference lower than 10–5). When the objective function converges, SFCM returns the last calculated fuzzy partition matrix, which indicates the degree of membership of the novel patient to each of the existing clusters. We then select the cluster associated with the higher degree of membership.
For evaluating the classifier approach, we took the patients in the calibration dataset and tried to align each of them to one of the existing clusters; we then counted how many patients could be aligned with the proper cluster (the cluster previously assigned in the cluster analysis). Then, we implemented the same procedure with the patients in the validation dataset and tried to align each of them to one of the existing clusters, in order to count how many of these patients would be aligned with the proper cluster.
We chose to examine the two instance-based algorithms because:
(a) The requirement for training data is comparatively low;
(b) They have higher stability, since small changes in the training dataset do not result in large changes in the classifier;
(c) They are well suited to incremental learning (ie, when adding data to the training dataset, it is not necessary to perform a complete training again);
(d) They consider instances as points in an n-dimensional space, and the (dis)similarity between them as distance; and
(e) The “tuning” of model parameters is straightforward.18
While several other methods have some of these advantages, they also have notable disadvantages relative to our aims. Logic-based algorithms typically have lower stability, in that small changes in the training dataset may result in greater changes in the classifier. Statistical learning algorithms typically assume that the dataset can be summarized with a single probability distribution. Perceptron-based algorithms: a) have requirements for training data that are comparatively higher, b) incorporate an operating and training process that is a “black box,” and c) deal less easily with numerous dichotomous variables. Non-linear interpolator algorithms also have high training data requirements and the tuning of the parameters strongly affects performance.18 While different variations are possible to minimize some of these trade-offs, we utilized instance-based algorithms, because they reflected the best balance.
We evaluated the performance of the methods we chose using the accuracy ratio defined as the proportion of true positive and true negative outcomes in all evaluated cases.33
Results
The full sample sizes and additional details of this model have been published previously and are available via open access.8 The results of utilizing the kNN approach alone and the SFCM approach alone are shown in Table 1 and Figure 2. In the training dataset (n=1766), the accuracy ratio for evaluating a patient’s alignment with a cluster varied widely across the clusters, ranging from 2.4% to 96.3% for the kNN approach alone, with an overall accuracy of 59.5%. The overall accuracy for the SFCM approach alone was 42.0% (range: 23.1% to 67.2% across the individual clusters). The best assessments of novel patient’s alignments resulted from the ensemble method (combined kNN and SFCM). When we used the ensemble method, we correctly classified 98.4% (range: 95.3% to 100.0% across the individual clusters) of the patients overall in the training dataset (Table 1 and Figure 2).
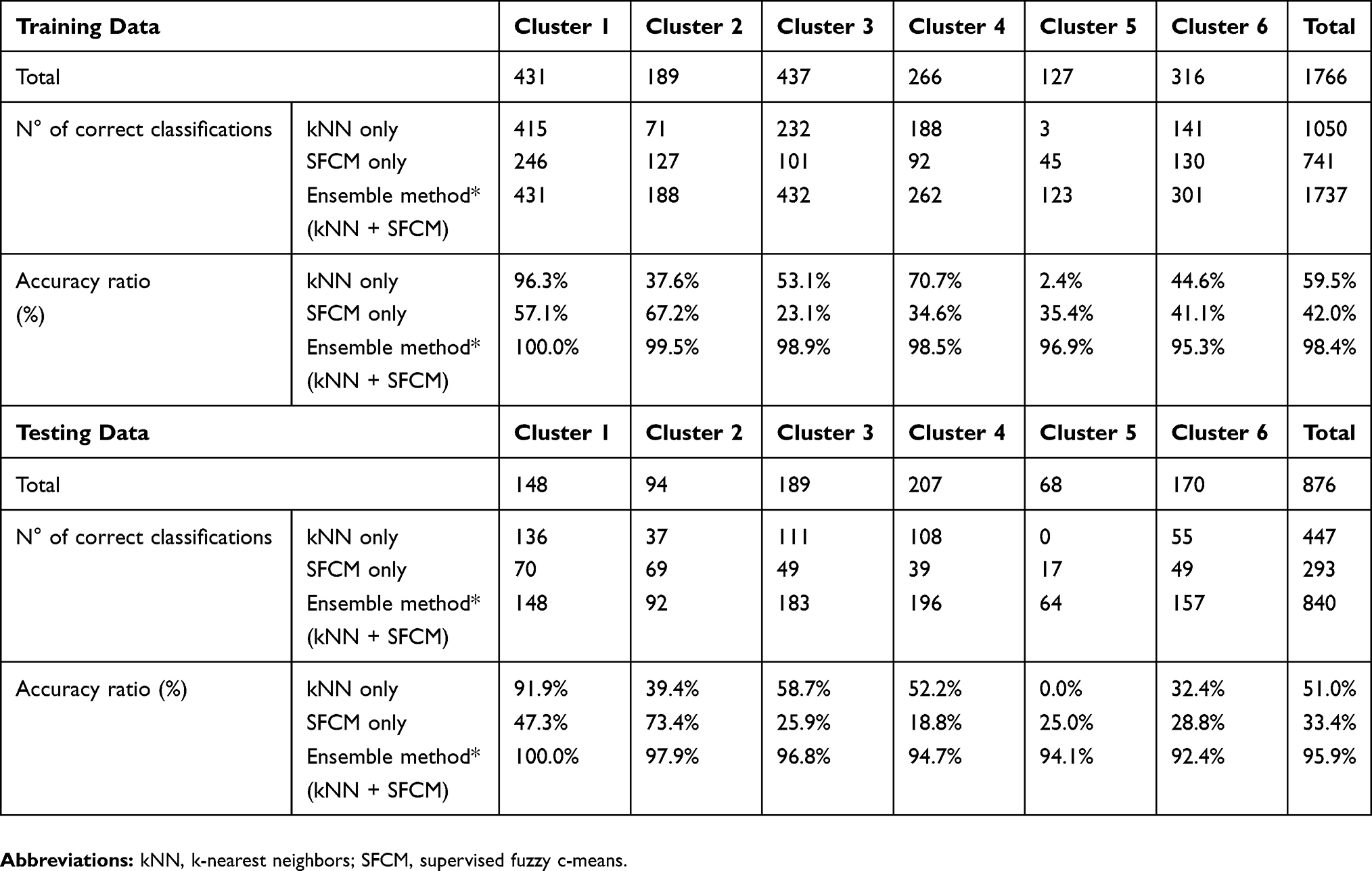 |
Table 1 Results for Training Dataset and Testing Dataset for kNN Method Only, SFCM Method Only, and the Ensemble Method |
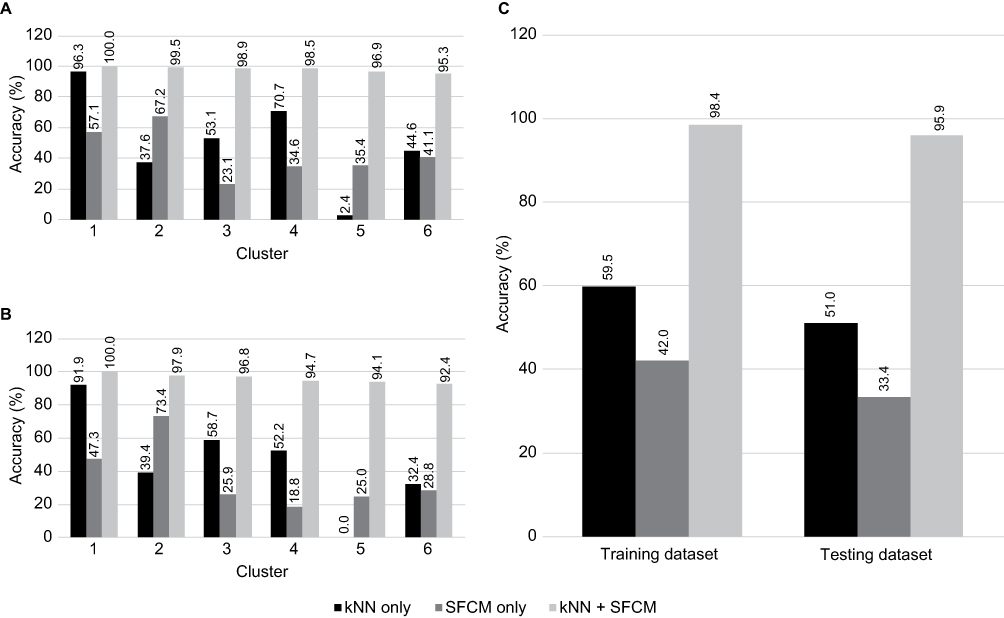 |
Figure 2 Accuracy results for the kNN method only, SFCM method only, and the ensemble method in (A) training dataset by cluster, (B) testing dataset by cluster, and (C) overall testing and training datasets. Abbreviations: kNN, k-nearest neighbors; SFCM, supervised fuzzy c-means. |
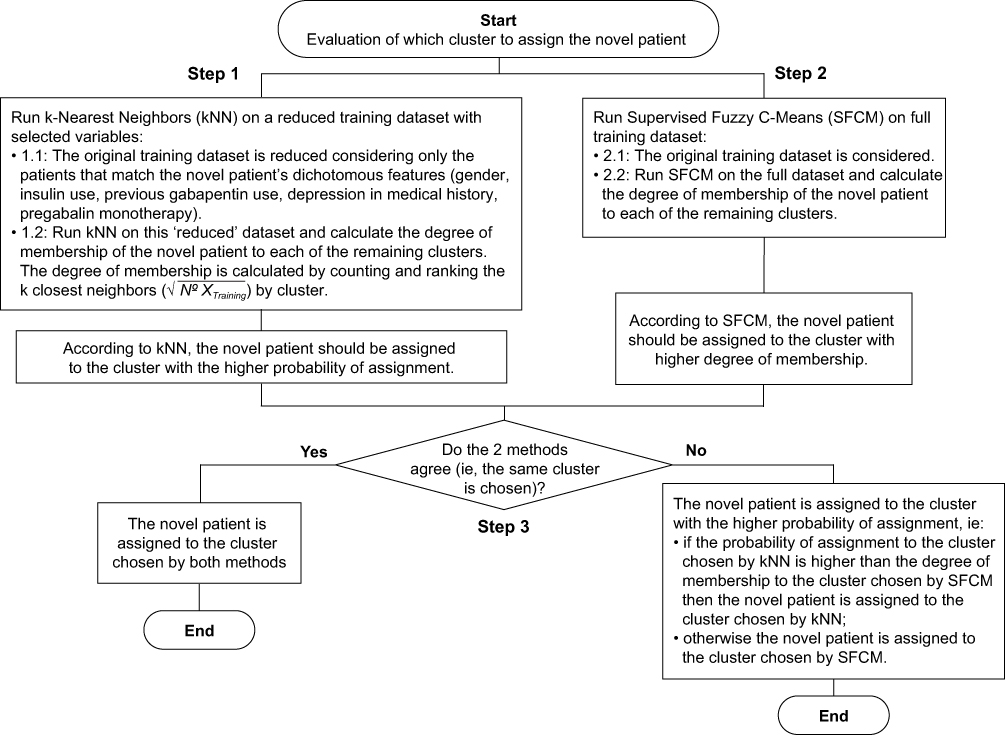 |
Figure 3 Ensemble method flowchart. |
The results in the testing dataset (n=876) are also shown in Table 1 and Figure 2. They mirrored those in the training dataset with a 95.9% (range: 92.4% to 100.0% across the individual clusters) overall accuracy when the ensemble method was used. When we analyzed the kNN method alone, it yielded an accuracy ratio of 51.0% overall in the testing dataset (range: 0% to 91.9% across the clusters). When we used the SFCM method alone, we correctly classified 33.4% of the 876 patients in the testing dataset (range: 18.8% to 69.3% across the clusters). Figure 3 shows the steps for the ensemble method.
Discussion
In our predictive analytics strategy, the assignment of a novel patient to a specific cluster is critically important given the role of the time-series regressions with lagged variables as input in the platform for predicting pain scores for individual patients.34 Consequently, we focused substantial efforts in this next generation of the platform on how to broaden the characteristics of patients who could be assigned to a cluster, since each cluster has its own specific regression. When broadening the range of patients whose outcomes could be predicted, we also wanted to maintain or enhance the accuracy of the prediction. Due to the inherent numerous dichotomous characteristics of the data combined with some variables that were continuous, determining how to assign a patient posed formidable challenges for various machine learning techniques. Moreover, we sought to include an ability to incorporate additional data as it might become available. After analyzing the inherent strengths and weaknesses of a number of machine learning techniques, we determined that the instance-based methods (kNN and SFCM, in particular) proved to be the best choices. However, alone, neither provided the performance required to achieve at least 95% accuracy, so we adopted an “ensemble method” that utilized both. This ensemble approach entailed implementation of the kNN method separately from the SFCM method, in order to determine independently to which cluster each method would ordinarily assign a novel patient. If the kNN and SFCM methods agreed in their cluster assignments (essentially converging on the same result), then the choice would be straightforward. When these methods disagreed, however, we chose to select the cluster assignment generated by the method that afforded the strongest evidence of alignment for the novel patient (ie, the highest value in terms of a probability for kNN or degree of membership for SFCM). This enabled a reproducible way of comparing options for assigning a patient to a cluster and reduced the overall likelihood of the undesirable impacts of any limitations specific to a given method. The effects were particularly striking for patients in Clusters 2 and 5, in which the kNN method performed poorly as compared to our “ensemble method” that led to 97.9% and 94.1% correct assignments for those clusters, respectively (see Table 1 and Figure 2). Since the ensemble method achieved excellent performance in assigning patients, we had greater confidence that the variables that were underlying the creation of the clusters initially were being effectively captured and utilized within this combined approach.
The addition of the ensemble method for assigning a novel patient and achieving the correct cluster assignment at least 95% of the time has important implications. The ability to assign a novel patient to a cluster is a critical component when subgroup-specific (cluster-specific) regressions are used for prediction. The rationale for different patient clusters has been described elsewhere34 and incorporates the clinical recognition that different patients have different pathways to outcomes, and that they might be grouped according to those pathways for improved prediction. By using the ensemble of two machine learning techniques for aligning a patient with a cluster, we could enable correct prediction of a wider range of patients, with characteristics that differ to some extent from those in the dataset. By predicting outcomes accordingly, we were able to extend the capabilities of our dataset, which was already unique in its incorporation of OS and RCT data with cluster-specific regressions. Expanding the potential utility of integrated OS and RCT data by applying machine learning techniques is a promising way to leverage available evidence to improve patient outcomes—an approach that deserves further investigation in various applications.
The superior performance of the ensemble method is not surprising, given other evidence in the literature of using two or more methods together to converge on a correct prediction.35–37 Given the mixed types of data (dichotomous, categorical, continuous), it makes sense that no single method would outperform an approach that utilizes multiple methods to converge on a correct prediction.
Limitations And Future Work
One limitation of these analyses was that they were confined to a single large OS, in terms of assessing which patients could be correctly assigned. Future work will need to see how these same five variables (gender, age group, BMI group, baseline pain score, and baseline pain-related sleep interference score) could be utilized to assign novel patients to a cluster. It remains to be explored what other variables might be needed for which patients; however, these variables provided a solid starting point, because they are typically collected in RCTs and OSs.
We have not yet tried prospectively to assign an actual new patient to predict pain outcomes using our platform. Future work will need to examine how such efforts could work in practice. We need to explore how the proposed approach—including a capability for dynamic real-time updates of experiences with patients through ongoing use—could be used in providing care to patients. Finally, these findings are specific to patients with pDPN, and not all patient variables associated with pDPN have yet been studied. Other clinical circumstances may require less or more complex approaches to enable prediction.
Conclusion
Better prediction of treatment outcomes for patients upon initiation of therapy holds tremendous potential for improving treatment decisions, the patients’ experiences of care, and overall health care system performance. These analyses with pregabalin in patients with pDPN suggest that instance-based machine learning techniques hold promise as a way of evaluating and applying the diverse types of patient data. Combined with microsimulation, they enabled a novel, individual patient to be assigned to a patient subgroup that could be utilized for predicting individual patient outcomes.
Abbreviations
ABMS, agent-based modeling and simulation; ANN, artificial neural network; BMI, body mass index; CEM, coarsened exact matching; kNN, k-nearest neighbor; OS, observational study; pDPN, painful diabetic peripheral neuropathy; PHN, postherpetic neuralgia; RCT, randomized controlled trial; SVM, support vector machine.
Ethics Approval And Informed Consent
These analyses pooled data from previous clinical trials to implement microsimulation modeling. Internal review board and committee approvals are reported in the source studies, which are referenced. No human subjects were directly enrolled in these current analyses.
Data Availability
Upon request, and subject to certain criteria, conditions and exceptions (see https://www.pfizer.com/science/clinical-trials/trial-data-and-results for more information), Pfizer will provide access to individual deidentified participant data from Pfizer-sponsored global interventional clinical studies conducted for medicines, vaccines, and medical devices (1) for indications that have been approved in the US and/or EU, or (2) in programs that have been terminated (ie, development for all indications has been discontinued). Pfizer will also consider requests for the protocol, data dictionary, and statistical analysis plan. Data may be requested from Pfizer trials 24 months after study completion. The deidentified participant data will be made available to researchers whose proposals meet the research criteria and other conditions, and for which an exception does not apply, via a secure portal. To gain access, data requestors must enter into a data access agreement with Pfizer.
Acknowledgments
These analyses were sponsored by Pfizer, which maintains the Virtual Lab database and verifies the data for accurate reporting of the numbers. Pfizer does not play a role in the final scientific or clinical interpretations of the data. The Observational Study and RCTs were sponsored by Pfizer. Editorial support in the form of copy editing and formatting was provided by Ray Beck, Jr, PhD, of Engage Scientific Solutions, and was sponsored by Pfizer.
Author Contributions
Roger Edwards and Joe Alexander Jr, conceived, designed, and led all aspects of the analyses and related article. Luigi Manca, Gianluca Bonfanti, and Roberto Grugni performed all statistical analyses and/or simulation/analytics related to this study. Ed Whalen and Birol Emir performed the statistical analyses for the original RCTs and OS and offered insights related to those studies and analyses. Bruce Parsons, Marina Brodsky, and Steve Watt provided interpretations of the data related to clinical relevance and unmet medical needs. All authors participated in the drafting of the article and final approval of its content. All authors endorse and agree to be accountable for all aspects of these analyses and this publication, including the accuracy and integrity of any part of the work, and will strive to ensure any questions are resolved.
Disclosure
Birol Emir, Bruce Parsons, Stephen Watt, and Ed Whalen are employees of Pfizer. Joe Alexander Jr and Marina Brodsky were employed by Pfizer at the time the study was conducted. Roger A Edwards is an employee of Health Services Consulting Corporation who was a paid consultant by Pfizer in connection with this study and development of this manuscript. Luigi Manca, Roberto Grugni, and Gianluca Bonfanti are employees of Fair Dynamics Consulting, who were paid subcontractors to Health Services Consulting Corporation in connection with this study and the development of this manuscript. The authors report no other conflicts of interest in this work.
References
1. Collins FS, Varmus H. A new initiative on precision medicine. N Engl J Med. 2015;372(9):793–795. doi:10.1056/NEJMp1500523
2. Sim I. Two ways of knowing: big data and evidence-based medicine. Ann Intern Med. 2016;164(8):562–563. doi:10.7326/M15-2970
3. Berwick DM, Nolan TW, Whittington J. The triple aim: care, health, and cost. Health Aff (Millwood). 2008;27(3):759–769. doi:10.1377/hlthaff.27.3.759
4. Amarasingham R, Patzer RE, Huesch M, Nguyen NQ, Xie B. Implementing electronic health care predictive analytics: considerations and challenges. Health Aff (Millwood). 2014;33(7):1148–1154. doi:10.1377/hlthaff.2014.0352
5. Hannan EL. Randomized clinical trials and observational studies: guidelines for assessing respective strengths and limitations. JACC Cardiovasc Interv. 2008;1(3):211–217. doi:10.1016/j.jcin.2008.01.008
6. Pfizer Inc. Lyrica (pregabalin) Prescribing Information. New York, NY; 2018.
7. European Medicines Agency. Lyrica (pregabalin) Summary of Product Characteristics. London, UK; 2017.
8. Alexander J
9. Alexander J
10. Alexander J, Edwards RA, Savoldelli A, et al. Integrating data from randomized controlled trials and observational studies to predict the response to pregabalin in patients with painful diabetic peripheral neuropathy. BMC Med Res Methodol. 2017;17(1):113. doi:10.1186/s12874-017-0389-2
11. Alexander J
12. Kazemi M, Moghimbeigi A, Kiani J, Mahjub H, Faradmal J. Diabetic peripheral neuropathy class prediction by multicategory support vector machine model: a cross-sectional study. Epidemiol Health. 2016;38:e2016011. doi:10.4178/epih/e2016011
13. Rubio TG, Castillo AS. Evaluation of ANN and SVM for the classification and prediction of patients with diabetic neuropathy.
14. Gujral S. Early diabetes detection using machine learning: a review. IJIRST. 2017;3(10):57–62.
15. Kavakiotis I, Tsave O, Salifoglou A, Maglaveras N, Vlahavas I, Chouvarda I. Machine learning and data mining methods in diabetes research. Comput Struct Biotechnol J. 2017;15:104–116. doi:10.1016/j.csbj.2016.12.005
16. Emir B, Johnson K, Kuhn M, Parsons B. Predictive modeling of response to pregabalin for the treatment of neuropathic pain using 6-week observational data: a spectrum of modern analytics applications. Clin Ther. 2017;39(1):98–106. doi:10.1016/j.clinthera.2016.11.015
17. Ho TK. Random decision forest.
18. Alpaydin E. Introduction to Machine Learning.
19. Bishop C. Neural Networks for Pattern Recognition. New York, NY: Oxford University Press; 1995.
20. Broomhead DS, Lowe D. Radial Basis Functions, Multi-Variable Functional Interpolation and Adaptive Networks. UK: Royal Signals and Radar Establishment Malvern; 1988.
21. Cortes C, Vapnik V. Support vector machine. Mach Learn. 1995;20(3):273–297. doi:10.1007/BF00994018
22. Bezdek JC. Pattern Recognition With Fuzzy Objective Function Algorithms. New York, NY: Plenum Press; 1981.
23. Gagliardi F. Instance-based classifiers applied to medical databases: diagnosis and knowledge extraction. Artif Intell Med. 2011;52(3):123–139. doi:10.1016/j.artmed.2011.04.002
24. Lesser H, Sharma U, LaMoreaux L, Poole RM. Pregabalin relieves symptoms of painful diabetic neuropathy: a randomized controlled trial. Neurology. 2004;63(11):2104–2110. doi:10.1212/01.WNL.0000145767.36287.A1
25. Richter RW, Portenoy R, Sharma U, Lamoreaux L, Bockbrader H, Knapp LE. Relief of painful diabetic peripheral neuropathy with pregabalin: a randomized, placebo-controlled trial. J Pain. 2005;6(4):253–260. doi:10.1016/j.jpain.2004.12.007
26. Rosenstock J, Tuchman M, LaMoreaux L, Sharma U. Pregabalin for the treatment of painful diabetic peripheral neuropathy: a double-blind, placebo-controlled trial. Pain. 2004;110(3):628–638. doi:10.1016/j.pain.2004.05.001
27. Freynhagen R, Strojek K, Griesing T, Whalen E, Balkenohl M. Efficacy of pregabalin in neuropathic pain evaluated in a 12-week, randomised, double-blind, multicentre, placebo-controlled trial of flexible- and fixed-dose regimens. Pain. 2005;115(3):254–263. doi:10.1016/j.pain.2005.02.032
28. Arezzo JC, Rosenstock J, Lamoreaux L, Pauer L. Efficacy and safety of pregabalin 600 mg/d for treating painful diabetic peripheral neuropathy: a double-blind placebo-controlled trial. BMC Neurol. 2008;8:33. doi:10.1186/1471-2377-8-33
29. Hoffman DL, Sadosky A, Dukes EM, Alvir J. How do changes in pain severity levels correspond to changes in health status and function in patients with painful diabetic peripheral neuropathy? Pain. 2010;149(2):194–201. doi:10.1016/j.pain.2009.09.017
30. Satoh J, Yagihashi S, Baba M, et al. Efficacy and safety of pregabalin for treating neuropathic pain associated with diabetic peripheral neuropathy: a 14 week, randomized, double-blind, placebo-controlled trial. Diabet Med. 2011;28(1):109–116. doi:10.1111/j.1464-5491.2010.03152.x
31. Tölle T, Freynhagen R, Versavel M, Trostmann U, Young JP
32. Toelle RT, Varvara R, Nimour M, Emir B, Brasser M. Pregabalin in neuropathic pain related to DPN, cancer and back pain: analysis of a 6-week observational study. Open Pain J. 2012;5:1–11. doi:10.2174/1876386301205010001
33. Baratloo A, Hosseini M, Negida A, El Ashal G. Part 1: simple definition and calculation of accuracy, sensitivity and specificity. Emerg (Tehran). 2015;3(2):48–49.
34. Alexander J
35. Acion L, Kelmansky D, van der Laan M, Sahker E, Jones D, Arndt S. Use of a machine learning framework to predict substance use disorder treatment success. PLoS One. 2017;12(4):e0175383. doi:10.1371/journal.pone.0175383
36. Allyn J, Allou N, Augustin P, et al. A comparison of a machine learning model with EuroSCORE II in predicting mortality after elective cardiac surgery: a decision curve analysis. PLoS One. 2017;12(1):e0169772. doi:10.1371/journal.pone.0169772
37. Zheng T, Xie W, Xu L, et al. A machine learning-based framework to identify type 2 diabetes through electronic health records. Int J Med Inform. 2017;97:120–127. doi:10.1016/j.ijmedinf.2016.09.014
 © 2019 The Author(s). This work is published and licensed by Dove Medical Press Limited. The
full terms of this license are available at https://www.dovepress.com/terms
and incorporate the Creative Commons Attribution
- Non Commercial (unported, 3.0) License.
By accessing the work you hereby accept the Terms. Non-commercial uses of the work are permitted
without any further permission from Dove Medical Press Limited, provided the work is properly
attributed. For permission for commercial use of this work, please see paragraphs 4.2 and 5 of our Terms.
© 2019 The Author(s). This work is published and licensed by Dove Medical Press Limited. The
full terms of this license are available at https://www.dovepress.com/terms
and incorporate the Creative Commons Attribution
- Non Commercial (unported, 3.0) License.
By accessing the work you hereby accept the Terms. Non-commercial uses of the work are permitted
without any further permission from Dove Medical Press Limited, provided the work is properly
attributed. For permission for commercial use of this work, please see paragraphs 4.2 and 5 of our Terms.