Back to Journals » Journal of Multidisciplinary Healthcare » Volume 18
Feasibility and Effectiveness of a Low-Code AI Platform for Developing a Neonatal Multimodal Pain Classification Model
Authors Yang N ![]() , Jiang X, Jin X, Dai X, Gu Y, Jiang H, Pu L
, Jiang X, Jin X, Dai X, Gu Y, Jiang H, Pu L ![]() , Shi T
, Shi T
Received 1 April 2025
Accepted for publication 28 August 2025
Published 13 September 2025 Volume 2025:18 Pages 5771—5780
DOI https://doi.org/10.2147/JMDH.S531709
Checked for plagiarism Yes
Review by Single anonymous peer review
Peer reviewer comments 2
Editor who approved publication: Dr Scott Fraser
Nannan Yang,1,* Xiaosong Jiang,2,* Xue Jin,2 Xinran Dai,2 Yuanjing Gu,3 Huiping Jiang,4 Liping Pu,5 Tingqi Shi1,6
1Department of Nursing, Nanjing Drum Tower Hospital Clinical College of Nanjing University of Chinese Medicine, Nanjing, Jiangsu, People’s Republic of China; 2School of Nursing, Nanjing University of Chinese Medicine, Nanjing, Jiangsu, People’s Republic of China; 3Department of Emergency, Nanjing Drum Tower Hospital, Affiliated Hospital of Medical School, Nanjing University, Nanjing, Jiangsu, People’s Republic of China; 4Department of Nursing, Nanjing Drum Tower Hospital, Affiliated Hospital of Medical School, Nanjing University, Nanjing, Jiangsu, People’s Republic of China; 5School of Health Management, Suzhou Vocational Health College, Suzhou, Jiangsu, People’s Republic of China; 6Quality Management Department, Nanjing Drum Tower Hospital, Affiliated Hospital of Medical School, Nanjing University, Nanjing, Jiangsu, People’s Republic of China
*These authors contributed equally to this work
Correspondence: Tingqi Shi, Nanjing Drum Tower Hospital, Affiliated Hospital of Medical School, Nanjing University, 321 Zhongshan Road, Gulou District, Nanjing, Jiangsu, People’s Republic of China, Email [email protected] Liping Pu, School of Health Management, Suzhou Vocational Health College, 20 Shuyuan Lane, Gusu District, Suzhou, Jiangsu, People’s Republic of China, Email [email protected]
Background: Artificial intelligence (AI) has advanced neonatal pain recognition, yet a significant gap persists in translating complex algorithms into practical clinical applications. Low-code AI development platforms, which simplify and automate model creation, offer a potential solution to bridge this gap between research and bedside practice.
Objective: This study aimed to explore the feasibility of constructing and validating a neonatal multimodal pain classification model using a commercial low-code AI development platform (EasyDL). The objective was to develop an accessible, cost-effective, and efficient method that empowers clinical professionals to create their own AI tools without extensive programming expertise.
Methods: We uploaded 426 neonatal acute pain multimodal data segments to the EasyDL platform and trained a video classification model using its AutoML capabilities. The model underwent internal testing on a held-out dataset portion, followed by external validation on an independent prospective cohort. For external validation, we compared model performance against the N-PASS (Neonatal Pain, Agitation, and Sedation Scale) scores assessed by a senior nurse as the clinical gold standard.
Results: The neonatal multimodal pain classification model developed on the platform showed strong performance. Internal validation achieved 89.6% accuracy and an 85.8% F1 score. External validation on unseen data reached 87.7% accuracy, with AUC exceeding 0.95 across all pain categories (no pain, mild pain, severe pain). The streamlined development process enabled seamless API deployment to an Android mobile device for clinical use.
Conclusion: Developing a neonatal multimodal pain classification model using a low-code AI platform proves both feasible and effective. The model demonstrates robust performance and strong clinical integration potential. This approach offers a practical pathway to democratize AI development, enabling healthcare professionals to create digital solutions for neonatal pain management.
Keywords: low-code platform, EasyDL, automated machine learning, AutoML, multimodal pain recognition, neonatal pain
Introduction
Neonatal pain recognition is a crucial component of pediatric clinical care and nursing. Currently, the Neonatal Pain Assessment Scale (N-PASS) is the primary tool employed for assessing neonatal pain in clinical settings.1 However, surveys indicate that its clinical application remains suboptimal, with many practitioners relying on subjective evaluations based on clinical experience rather than standardized, evidence-based methods.2 Several factors contribute to this issue. First, the process of conducting a comprehensive, accurate assessment using the scale is often time-consuming and labor-intensive, which may discourage its consistent use in practice. Additionally, the subtle and frequently insidious nature of neonatal pain complicates its detection, and determining the optimal timing for assessment remains a challenge.3,4 These intrinsic limitations have considerably hindered the advancement of effective neonatal pain assessment in clinical practice.
Recent advancements in artificial intelligence (AI) and machine learning (ML) have significantly enhanced their application in medical decision-making and auxiliary diagnostics, particularly in the identification of neonatal pain.5 The clinical potential for intelligent evaluation algorithms in neonatal pain assessment is vast. Substantial progress has been made in developing pain recognition and classification models based on various modalities, including facial expressions, crying sounds, and physiological parameters. For example, Ashwini6 extracted acoustic features such as intensity, fundamental frequency, and formants from neonatal cry signals to construct a classifier, achieving an evaluation accuracy of 89%. Similarly, Salekin7 combined facial expressions, body movements, and crying sounds to develop a postoperative pain evaluation model for neonates, which demonstrated an accuracy of 79%. These studies highlight the pivotal role of machine learning techniques in neonatal pain assessment and suggest their capacity to substantially improve the efficiency and precision of clinical evaluations. However, much of the research in this domain lies at the intersection of technology and the medical field, often requiring the expertise of skilled engineers. Moreover, these studies primarily focus on the extraction and fusion of multimodal features, the development of complex algorithms, and parameter optimization—areas that necessitate advanced computational proficiency. Additionally, the reliance on high-precision, costly equipment for data acquisition has posed significant challenges in translating these findings into widespread clinical practice.8 While state-of-the-art AI research shows immense promise, its translation into widespread clinical practice is often impeded by significant technical barriers. The development of sophisticated deep learning models typically requires specialized expertise in computer science, complex programming, and resource-intensive computational infrastructure.
To address this challenge, a new generation of low-code AI platforms has emerged. These platforms are designed to democratize AI development by enabling users with limited or no coding expertise to build, train, and deploy custom models through intuitive graphical user interfaces and pre-configured modules.9–11 These platforms are powered by underlying technologies known as Automated Machine Learning (AutoML) and Automated Deep Learning (AutoDL). AutoML automates the highly complex and iterative tasks of the machine learning pipeline, including feature engineering, model selection (for example using Neural Architecture Search to find the best model structure), and hyperparameter tuning. Platforms such as Baidu EasyDL,12 Google Vertex AI,13 and Azure Automated ML14 function as integrated, “one-stop” environments that manage the entire development lifecycle, from data uploading and annotation to model training, evaluation, and deployment via an application programming interface (API). Baidu EasyDL,15 the platform used in this study, is built upon Baidu’s open-source PaddlePaddle deep learning framework and incorporates these advanced automation technologies to simplify model creation. This technological shift facilitates a new paradigm in applied medical AI: a move from model-centric to data-centric development. By abstracting away the complexities of algorithm design, these platforms empower clinical domain experts—the individuals with the deepest understanding of the clinical problem and the data—to focus their efforts on curating high-quality, accurately labeled datasets. This allows clinicians to drive the creation of relevant and effective AI tools, accelerating the translation of AI from the research lab to the patient’s bedside.
To address the limitations of model development thresholds for the clinical application of neonatal pain assessment, this study explores the use of the mature EasyDL platform in China.15 EasyDL is a comprehensive, low-code AI platform based on deep learning algorithms, which provides a robust pre-trained model. The platform incorporates AutoDL and AutoML technologies, enabling automatic adjustment of model structure and parameters to further enhance performance. EasyDL has been successfully applied in medical fields, including tumor detection and fundus lesion identification. For example, Yang et al12 developed a bladder tumor recognition model on this platform, achieving an accuracy of 96.9%, demonstrating its potential for real-world clinical application. Additionally, Zhang16 used CT images of the pancreas from patients with acute pancreatitis and healthy individuals to construct a classification model for acute pancreatitis, with an accuracy of 86%. This model assists clinicians in swiftly and accurately diagnosing pancreatitis and localizing lesions. Beyond healthcare, EasyDL has expanded its applications into various non-medical fields, such as automation and intelligent identification of animals and plants. Thus, the EasyDL platform enables professionals from non-computational backgrounds to utilize multimodal industry data for the development of customized deep learning models, thereby breaking down professional barriers, reducing development costs, and facilitating the rapid integration of traditional industries with emerging AI technologies.
To facilitate the widespread application of intelligent neonatal pain recognition models in real-world clinical settings, we have thoroughly considered the numerous challenges that clinical staff may encounter in computer programming and model development. To address these challenges, we propose a method that is cost-free, low-threshold, highly accessible, easy to implement, and effective in performance. This method is designed to enable convenient promotion and application in clinical environments. In our preliminary research, we constructed a neonatal multimodal pain dataset (MD-NPA).17
Materials and Methods
Ethical Conduct of Research
The study was approved by the Medical Ethics Committee of Nanjing Drum Tower Hospital, Affiliated Hospital of Medical School, Nanjing University (Approval Number: 2024-026-02). The research was conducted in accordance with the principles of the Declaration of Helsinki.1 Written informed consent was obtained from the legal guardians of all participating neonates prior to data collection and inclusion in the study.
Dataset and Ground-Truth Labeling
The data used for model development were sourced from our previously published study, “Multi-modal Data Set for Acute Pain in Neonates (MD-NPA)”. This dataset includes multimodal recordings from 142 healthy newborns undergoing routine acute painful procedures (heel stick or intramuscular injection). For this study, we focused on four data modalities most relevant to observational clinical assessment: video recordings of facial expressions and limb movements, and audio recordings of crying sounds.
To establish a reliable ground truth for model training, pain was assessed and scored in real-time by trained nurses using the Neonatal Pain, Agitation, and Sedation Scale (N-PASS), a validated tool for this patient population. The N-PASS assesses five criteria: crying/irritability, behavior/state, facial expression, extremities/tone, and vital signs. The resulting continuous N-PASS scores were then mapped to three discrete pain categories to serve as labels for the classification model.18 Based on clinical guidelines and literature where an N-PASS score greater than 2 or 3 indicates pain requiring intervention, The scale categorizes neonatal pain intensity into the following three levels based on the scores: No pain: N-PASS score of 0; Mild pain: N-PASS score of 1to 7; Severe pain: N-PASS scored of 8 to 10.
The research content and results concerning dataset quality have been publicly released. This process ensured that the “precise labels” used for model training were based on a standardized and clinically relevant assessment method.1 Three video segments were collected for each neonate, capturing the “before”, “during”, and “after” phases of the procedure, resulting in a total of 426 multimodal data segments. Each segment had a duration of 6 to 7 seconds. The quality of the dataset labels was previously validated, showing a high intraclass correlation coefficient (ICC) of 0.984 and a kappa statistic of 0.899 when compared with assessments by professional nurses, confirming its suitability for model development.17 The distribution of pain levels in the dataset is presented in Table 1.
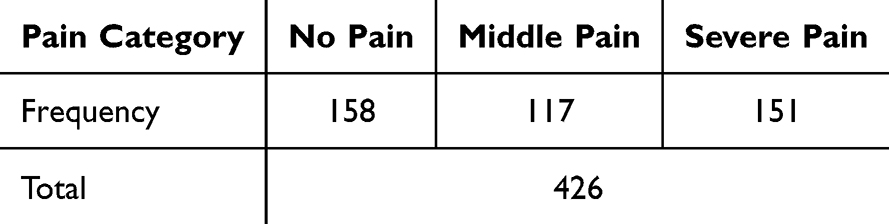 |
Table 1 Distribution of Pain Levels in the Dataset |
The Low-Code AI Development Platform: EasyDL
This study utilized Baidu EasyDL, a cloud-based, low-code AI development platform designed to streamline the entire model development lifecycle for users with limited programming expertise. The platform’s core strength lies in its integration of AutoML and AutoDL technologies, which automate the complex processes of deep learning model architecture selection and hyperparameter tuning.15
For this research, the platform’s video classification module was employed. While the specific underlying model architecture is proprietary to the platform, such tasks are typically handled by hybrid deep learning models that combine a 3D Convolutional Neural Network (3D-CNN) with a Long Short-Term Memory (LSTM) network. In this common architecture, the 3D-CNN is responsible for extracting spatial features from individual video frames, while the LSTM network models the temporal dependencies and patterns across the sequence of frames, making it well-suited for action and event recognition in videos.23 The model was trained on a high-performance computing backend consisting of a Tesla GPU (48GB video memory), a 12-core CPU, and 40GB of RAM.19
Model Development and Validation Strategy
A rigorous, multi-stage validation strategy was employed to assess the model’s performance and generalizability. The data partitioning scheme is as follows:
Training and Internal Validation Set: The initial MD-NPA dataset, comprising 426 video segments from 142 neonates, was uploaded to the EasyDL platform for model development. The platform automatically partitioned this dataset, using a standard 70/30 split. Approximately 70% of the data (299 segments) were used for training the model, while the remaining 30% (127 segments) were held out as an internal validation set to evaluate performance during the development phase.
External Validation Set: To perform a more robust assessment of the model’s real-world performance, a separate, independent cohort of 30 healthy neonates was prospectively recruited from the neonatology department of a tertiary care hospital in Jiangsu Province, China, between October 1, 2024, and December 31, 2024. This resulted in 90 new, unseen video segments (3 per neonate: before, during, and after a heel stick or intramuscular procedure) that were used exclusively for external validation.
Model Deployment and Application
Upon completion of training, the model was deployed using the EasyDL platform, which generated a unique API endpoint for application service access. The trained model and its parameters were packaged as an application and installed on standard Android mobile devices. This allowed for direct clinical application, where the mobile device’s built-in camera could capture video and audio data of a neonate. The application was designed with a simple interface for clinical staff to initiate video recording. Upon completion, the video is processed by the deployed model, and the resulting pain classification (“No pain”, “Mild pain”, or “Severe pain”) is displayed on the screen in near real-time, providing immediate decision support.
Statistical Analysis
The model’s performance was evaluated using several standard classification metrics: accuracy, precision, recall, and F1-score. A confusion matrix was used to visualize the model’s predictions against the actual ground-truth labels. Receiver Operating Characteristic (ROC) curve analysis was conducted, and the Area Under the Curve (AUC) was calculated to assess the model’s discriminatory power for each pain category. Data processing and visualization were performed using Python 3.1. Descriptive statistics for the validation cohort, such as mean and standard deviation (SD) for weight and gestational age, were calculated to characterize the sample. Statistical significance was defined as P<0.05.
Results
Model Training and Internal Validation Performance
A total of 426 multimodal data segments were used for model training and internal validation on the EasyDL platform. During the training process, the platform automatically reserved 127 samples (30%) for testing. The resulting model, named the Neonatal Multi-modal Pain Assessment Model (NMPA-M), achieved a strong overall accuracy of 89.6%. The weighted average precision was 87.4%, recall was 86.5%, and the F1-score was 0.858. Out of the 127 internal test samples, the model correctly classified 111, with 16 misclassifications. The detailed performance metrics for each pain category are provided in Table 2.
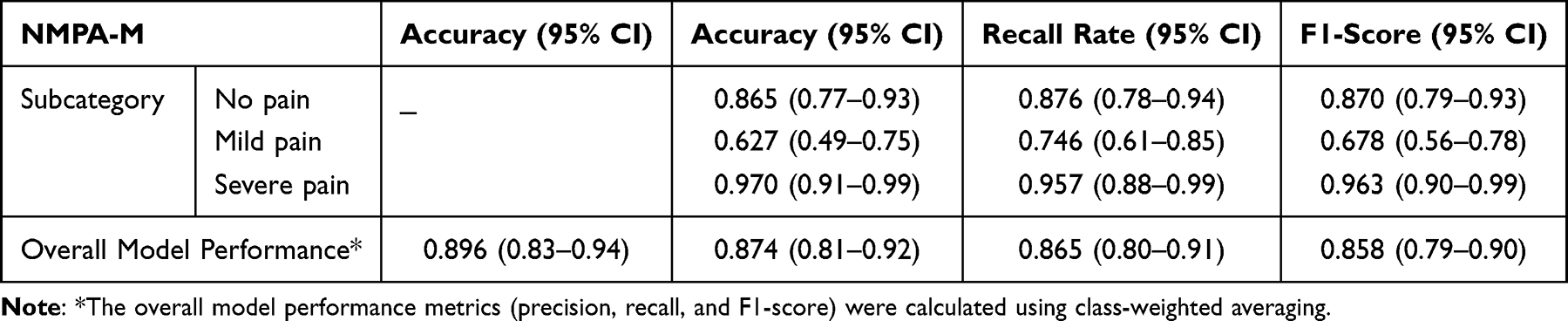 |
Table 2 Performance of the Multi-Modality Assessment Model for Neonatal Pain (NMPA-M) |
External Validation Cohort Characteristics
For external validation, a cohort of 30 healthy neonates was recruited, from whom 90 audio-video samples were collected. The sample consisted of 16 male (53.3%) and 14 female (46.7%) infants. All neonates were full-term and of regular weight. The painful procedures included 7 intramuscular injections (23.3%) and 23 heel pricks (76.7%). On-site pain assessment by a senior nurse using the N-PASS scale categorized the 90 data segments into 32 “no pain”, 25 “mild pain”, and 33 “severe pain” instances. The detailed characteristics of the external validation sample are presented in Table 3.
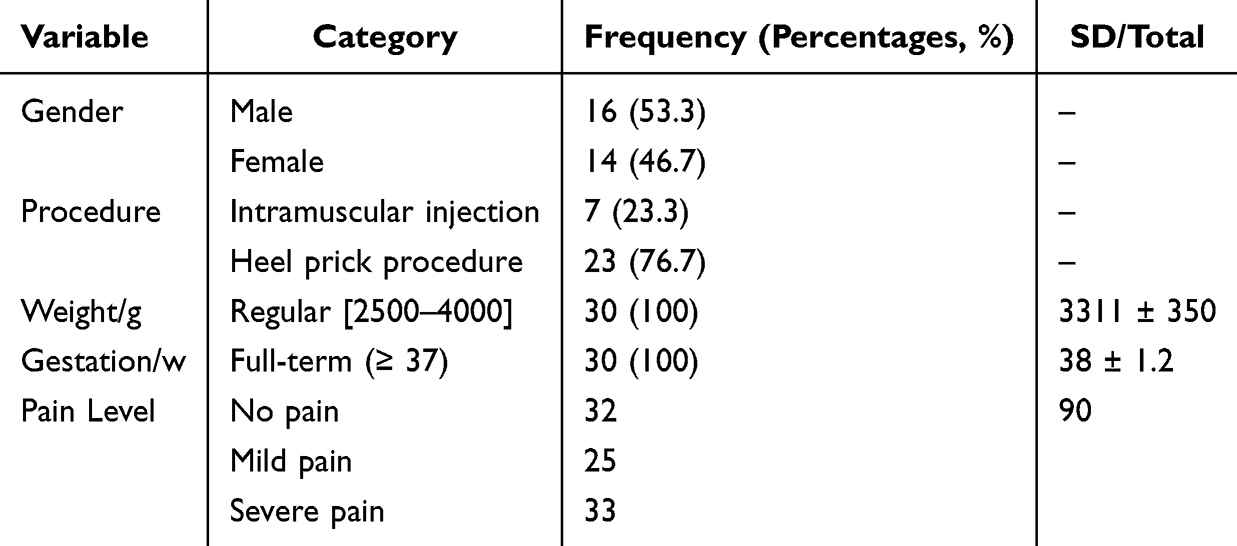 |
Table 3 Sample Characteristics for External Validation Dataset |
Model Performance in External Validation
The NMPA-M model, deployed on an Android mobile device, was used to assess the pain responses in the external validation cohort, with the senior nurse’s N-PASS assessments serving as the gold standard. Of the 90 samples, the model correctly classified 79, yielding an overall accuracy of 87.7%. The overall precision was 86.7%, recall was 87.7%, and the F1-score was 87.1%.
The model’s performance varied across categories. It correctly predicted 29 of the 32 “no pain” cases, 19 of the 25 “mild pain” cases, and 31 of the 33 “severe pain” cases. The confusion matrix in Figure 1 illustrates the distribution of these predictions. Figure 2 shows examples of the model’s output on the mobile application, where the predicted class probabilities are displayed for each category. Panel (D) illustrates a representative case of misclassification, where the model incorrectly predicted “Mild pain” for a “No pain” instance, highlighting a specific area of challenge for the model.
 |
Figure 1 Model external validation set confusion matrix diagram. |
 |
Figure 2 Model External Validation Set Evaluation Results Example. (A–C) Correct classifications for “No Pain”, “Mild Pain”, and “Severe Pain” cases. (D) Misclassification example where a “Mild Pain” case was incorrectly categorized as “No Pain”. The numerical values displayed (eg, 0.87, 0.12, 0.01) indicate the model’s predicted probabilities for each pain category (Severe, Mild, No Pain). |
Performance was highest for the “Severe pain” category (accuracy 93.9%) and lowest for the “Mild pain” category (accuracy 76.0%). Detailed performance metrics for the external validation are provided in Table 4. The ROC analysis demonstrated excellent discriminatory power, with AUC values greater than 0.95 for all three categories, as shown in Figure 3.
 |
Table 4 Model External Validation Performance Indicator Scores |
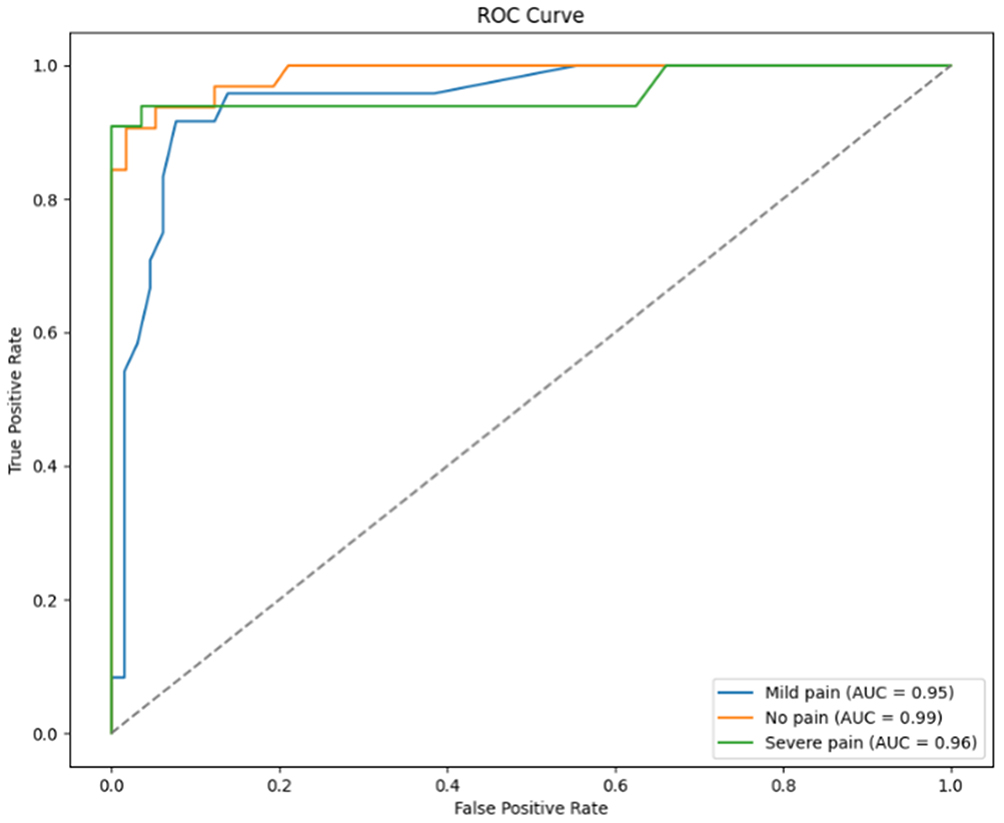 |
Figure 3 Area Under the Subject Profile Curve for the NMPA-M External Validation Dataset. |
A detailed summary of the model’s overall performance and the performance metrics for each category is provided in Table 4.
Discussion
Principal Findings: Feasibility of Clinician-Led AI Development
This study’s principal finding is that it is highly feasible for clinical professionals with limited coding expertise to develop and deploy a high-performing neonatal pain classification model using a low-code AI platform. The NMPA-M model achieved robust performance, with an external validation accuracy of 87.7% and an AUC greater than 0.95 across all classes, demonstrating that this approach can yield clinically relevant results.1 The primary contribution of this work is not the creation of a novel algorithm but rather the demonstration of an accessible and efficient workflow that successfully bridges the persistent gap between advanced AI research and practical clinical application.1 By streamlining the development process, platforms like EasyDL empower healthcare professionals to become creators of AI technology, not just end-users, thereby accelerating the adoption of AI in clinical settings to enhance medical decision-making and operational efficiency. The platform offers a comprehensive, integrated solution encompassing data acquisition, preprocessing, annotation, model training, validation, and deployment. Streamlining the development workflow, lowers the technical barrier to AI model implementation, providing an efficient tool for clinical professionals to enhance medical decision-making and operational efficiency.
Analysis of Model Performance and the Challenge of “Mild Pain” Classification
A detailed analysis of the model’s performance reveals a significant discrepancy between categories. The model demonstrated strong classification performance for the “Severe pain” (93.9% accuracy) and “No pain” (90.6% accuracy) categories, while performance for “Mild pain” was comparatively lower (76.0% accuracy). This finding is particularly insightful as most prior research has focused on a simpler binary classification of pain versus no-pain.1 Our exploration of a three-class problem highlights a fundamental challenge in the field of automated pain assessment.
Several factors likely contribute to this discrepancy. First, pain is an inherently subjective and continuous physiological experience. The use of assessment scales like N-PASS forces this continuum into discrete categories. The boundaries around “mild pain” are particularly fuzzy, relying on qualitative descriptors, such as “intermittent pain performance” versus the more distinct “high-pitched or uninterrupted crying” indicative of severe pain. This inherent ambiguity in the ground-truth labels makes it a more difficult class for the model to learn.
Second, “mild pain” often represents a brief, transitional state between no pain and severe pain. The behavioral and facial expressions associated with this state may be less distinct and more variable, lacking the clear, consistent patterns of severe distress or complete calm that a video classification model can more easily identify.
Third, confounding factors such as general stress or discomfort, which are not necessarily painful, may manifest in ways that are visually similar to mild pain, leading to misclassification. Finally, as shown in our dataset (Table 1 and Table 3), the “Mild pain” category had fewer instances compared to the other two classes. This sample imbalance may have provided the model with less data to robustly learn the features of this specific class. Despite these challenges, the model’s strong ability to distinguish the presence of significant pain from no pain underscores its clinical potential.
Clinical Implications and Future Workflow Integration
The successful development and deployment of the NMPA-M on a mobile device underscores its strong potential for clinical translation. The tool offers a practical solution to the limitations of manual pain assessment. For instance, a nurse in a busy NICU could use the mobile application for a quick, objective “spot-check” of a neonate’s pain status. The AI-generated score could function as a clinical decision support tool, prompting the nurse to conduct a full, manual N-PASS assessment if the model indicates the presence of moderate or severe pain, thereby optimizing the allocation of their time and effort. Looking forward, the API-based architecture of the model facilitates integration with hospital-wide systems like the Electronic Health Record (EHR). An AI-generated pain score could be automatically logged into the patient’s EHR, creating a continuous, objective record of pain status over time. This data could be invaluable for long-term analysis, quality improvement initiatives, and research into the effects of pain management strategies. However, the integration of such AI tools into clinical practice requires careful consideration of the perspectives of both clinicians and parents. Studies have shown that while there is broad support for these technologies, there are also significant concerns regarding over-reliance on AI, data privacy, and the critical need for the AI to serve as an adjunct to, rather than a replacement for, human clinical judgment.20
Limitations and Future Directions
This study has several limitations that warrant discussion. First, the use of a commercial, low-code platform like EasyDL introduces a “black box” element. The proprietary nature of the underlying algorithms means there is a lack of full transparency, which poses a challenge for model interpretability—a critical aspect of AI in high-stakes medical applications.
Second, the model was developed using a single-center dataset (MD-NPA). While our external validation on a separate cohort strengthens the findings, the model’s generalizability may be limited. Future work must involve validation on larger, multi-center, and more ethnically diverse datasets to ensure its robustness across different populations and clinical environments. Additionally, practical data acquisition requirements, such as the need for a clear, unobstructed view of the neonate’s face and limbs and minimal background noise, could limit the model’s adaptability in the unpredictable environment of a NICU.
Future research should focus on several key areas. Efforts should be made to refine the model’s architecture or training strategy to improve the classification accuracy for the challenging “mild pain” category. Most importantly, the next step is to conduct prospective, randomized clinical trials to evaluate the tool’s real-world impact on clinical outcomes.
Conclusion
In this study, a multimodal classification model for neonatal pain was successfully developed and validated using the EasyDL low-code development platform. The model demonstrated strong performance in both internal and external validation and was effectively deployed on mobile devices for direct clinical application. The development process proved to be operationally feasible for clinical professionals, and the resulting model shows significant clinical utility. By demonstrating a practical pathway to bridge the gap between traditional medical practice and emerging AI technologies, this study contributes to the democratization of AI development in healthcare. This approach may facilitate wider adoption of AI tools among healthcare professionals and advance the digitalization and management of neonatal pain.
Ethical Approval and Consent to Participate
The study was approved by the Medical Ethics Committee of Nanjing Drum Tower Hospital, affiliated with Nanjing University Medical School (Approval Number: 2024-026-02). The study complies with the Declaration of Helsinki. Written informed consent was obtained from the legal guardians of all participating neonates.
Consent for Publication
Written informed consent was obtained from the parental guardians of the infant depicted in Figure 2 for the publication of the image.
Acknowledgments
The authors declare that there are no acknowledgments.
Author Contributions
All authors made a significant contribution to the work reported, whether that is in the conception, study design, execution, acquisition of data, analysis and interpretation, or in all these areas; took part in drafting, revising or critically reviewing the article; gave final approval of the version to be published; have agreed on the journal to which the article has been submitted; and agree to be accountable for all aspects of the work.
Funding
This research was supported by the following research funds: Nanjing Health Science and Technology Development Special Fund Project (YKK22074); University-Industry Collaborative Education Program (Program No. 230905329045253).
Disclosure
The authors declare no conflicts of interest related to this study.
References
1. Neonatology Branch of Chinese Medical Association; Editorial Board of Chinese Journal of Contemporary Pediatrics. [Expert consensus on neonatal pain assessment and analgesia management (2020 edition)]. Zhongguo Dang Dai Er Ke Za Zhi. 2020;22(9):923–930. Xhosa. doi:10.7499/j.issn.1008-8830.2006181
2. Perry M, Tan Z, Chen J, et al. Neonatal pain: perceptions and current practice. Crit Care Nurs Clin North Am. 2018;30(4):549–561. doi:10.1016/j.cnc.2018.07.013
3. Polkki T, Korhonen A, Laukkala H, et al. Nurses’ attitudes and perceptions of pain assessment in neonatal intensive care. Scand J Caring Sci. 2010;24(1):49–55. doi:10.1111/j.1471-6712.2008.00683.x
4. Castagno E, Fabiano G, Carmellino V, et al. Neonatal pain assessment scales: review of the literature. Prof Inferm. 2022;75(1):17–28. doi:10.7429/pi.2022.751017
5. Giordano V, Luister A, Vettorazzi E, et al. Comparative analysis of artificial intelligence and expert assessments in detecting neonatal procedural pain. Sci Rep. 2024;14(1):20374. doi:10.1038/s41598-024-71278-6
6. Vincent PM, Srinivasan K, Chang CY. Deep learning assisted neonatal cry classification via support vector machine models. Front Public Health. 2021;9:670352. doi:10.3389/fpubh.2021.670352
7. Salekin M-S, Zamzmi G, Hausmann J, et al. Multimodal neonatal procedural and postoperative pain assessment dataset. Data Brief. 2021;35:106796. doi:10.1016/j.dib.2021.106796
8. Heiderich T-M, Carlini L-P, Buzuti L-F, et al. Face-based automatic pain assessment: challenges and perspectives in neonatal intensive care units. J Pediatr. 2023;99(6):546–560. doi:10.1016/j.jped.2023.05.005
9. Chen H, Zhang S, Matsumoto H, et al. Employing a low-code machine learning approach to predict in-hospital mortality and length of stay in patients with community-acquired pneumonia. Sci Rep. 2025;15(1):309. doi:10.1038/s41598-024-82615-0
10. Delange B, Popoff B, Seite T, et al. LinkR: an open source, low-code and collaborative data science platform for healthcare data analysis and visualization. Int J Med Inform. 2025;199:105876. doi:10.1016/j.ijmedinf.2025.105876
11. Mathur P, Arshad H, Grasfield R, et al. Navigating AI: a quick start guide for healthcare professionals. Cureus. 2024;16(10):e72501. doi:10.7759/cureus.72501
12. Du Y, Yang R, Chen Z, et al. A deep learning network-assisted bladder tumour recognition under cystoscopy based on Caffe deep learning framework and EasyDL platform. Int J Med Robot. 2021;17(1):1–8. doi:10.1002/rcs.2169
13. Sina E-M, Pena J, Zafar S, et al. Automated Machine Learning Classification of Optical Coherence Tomography Images of Retinal Conditions Using Google Cloud Vertex AI. Retina. 2025. doi:10.1097/IAE.0000000000004555
14. Choi W, Choi T, Heo S. A comparative study of automated machine learning platforms for exercise anthropometry-based typology analysis: performance evaluation of AWS SageMaker, GCP VertexAI, and MS Azure. Bioengineering. 2023;10(8):891. doi:10.3390/bioengineering10080891
15. Corporation Baidu. EasyDL.
16. Zhang C, Peng J, Wang L, et al. A deep learning-powered diagnostic model for acute pancreatitis. BMC Med Imaging. 2024;24(1):154. doi:10.1186/s12880-024-01339-9
17. Yang N, Zhuang Y, Jiang H, et al. Developing and validating a multimodal dataset for neonatal pain assessment to improve AI algorithms with clinical data. Adv Neonatal Care. 2024;24(6):578–585. doi:10.1097/ANC.0000000000001205
18. Morgan M-E, Kukora S, Nemshak M, et al. Neonatal pain, agitation, and sedation scale’s use, reliability, and validity: a systematic review. J Perinatol. 2020;40(12):1753–1763. doi:10.1038/s41372-020-00840-7
19. Corporation Baidu. How to publish sound classification models as APIs.
20. Handelman G-S, Kok H-K, Chandra R-V, et al. Peering into the black box of artificial intelligence: evaluation metrics of machine learning methods. AJR Am J Roentgenol. 2019;212(1):38–43. doi:10.2214/AJR.18.20224
 © 2025 The Author(s). This work is published and licensed by Dove Medical Press Limited. The
full terms of this license are available at https://www.dovepress.com/terms
and incorporate the Creative Commons Attribution
- Non Commercial (unported, 4.0) License.
By accessing the work you hereby accept the Terms. Non-commercial uses of the work are permitted
without any further permission from Dove Medical Press Limited, provided the work is properly
attributed. For permission for commercial use of this work, please see paragraphs 4.2 and 5 of our Terms.
© 2025 The Author(s). This work is published and licensed by Dove Medical Press Limited. The
full terms of this license are available at https://www.dovepress.com/terms
and incorporate the Creative Commons Attribution
- Non Commercial (unported, 4.0) License.
By accessing the work you hereby accept the Terms. Non-commercial uses of the work are permitted
without any further permission from Dove Medical Press Limited, provided the work is properly
attributed. For permission for commercial use of this work, please see paragraphs 4.2 and 5 of our Terms.