Back to Journals » Clinical Interventions in Aging » Volume 13
Categorization of sentence recognition for older adults under noisy and time-altered conditions
Authors Kim S ![]() , Ma S, Lee J
, Ma S, Lee J ![]() , Han W
, Han W ![]()
Received 25 June 2018
Accepted for publication 14 September 2018
Published 1 November 2018 Volume 2018:13 Pages 2225—2235
DOI https://doi.org/10.2147/CIA.S178191
Checked for plagiarism Yes
Review by Single anonymous peer review
Peer reviewer comments 2
Editor who approved publication: Dr Richard Walker
Saea Kim, Sunmi Ma, Jihyeon Lee, Woojae Han
Laboratory of Hearing and Technology, Division of Speech Pathology and Audiology, College of Natural Science, Hallym University, Chuncheon, Korea
Purpose: While evaluating the speech recognition ability of older adults, the present study aimed to analyze their error types in parts of speech and find error patterns under various conditions of background noise level and speed of speech.
Methods: Twenty older adults with normal hearing for their age (NHiA) and 20 older adults with sensorineural hearing loss (SNHL) participated. Their cognitive function was screened as within the normal range (mini-mental state examination scores >25). The SNHL listeners were divided into high performers (SNHL-H; n=12) and low performers (SNHL-L; n=8), based on their achieving word recognition scores above or below 70%, respectively. A sentence recognition test was conducted at four levels of signal-to-noise ratio (SNR; eg, no noise, +6, +3, 0 dB) and four conditions of time alteration (eg, 30% and 15% of compression and expansion) at the most comfortable level for each participant.
Results: As expected, the three groups showed that the error percentage increased in sentence recognition as either the SNR decreased or the speech rate became faster. Interestingly, a larger performance difference was found between the SNHL-H and SNHL-L groups in the condition of time alteration than in that of background noise. Among the parts of speech, nouns presented the highest error scores for all participants regardless of degree of listening difficulty. The noun errors of the three groups mainly consisted of no response and fail patterns, but substitution and omission were identified as the third pattern of noun error for background noise and fast speech, respectively.
Conclusion: Deterioration of speech recognition from the hearing threshold and supra-threshold auditory processing was seen in the elderly in difficult listening environments such as background noise and time alteration. Although different group performance ran across the eight experimental conditions, the robustness of noun errors and the error patterns were very similar, which might be extended to a possible clinical application of aural rehabilitation for the elderly population.
Keywords: age-related perceptual error, sentence perception, noun error, error pattern, distracting listening condition
Introduction
Common characteristics of age-related hearing loss are elevated hearing threshold, degradation of speech recognition ability, dysfunction of central auditory processing, and poor performance in sound localization.1,2 With aging, a noticeable hearing loss in the high frequency range of 2,000 Hz and above makes it difficult for elderly listeners to detect speech sounds in those frequencies and to discriminate between sounds.3 Consequently, the elderly with hearing loss frequently complain that they can hear speech by using hearing aids but still cannot understand what the speech means.4,5
Age-related difficulties in speech recognition are presumed by many researchers to involve several factors, from age-related loss in hearing sensitivity to various changes in cognitive performance as mental health declines.6,7 In particular, supra-threshold auditory processing abilities by age-dependent changes include subclinical loss from pure-tone audiometric diagnosis, although the changes have a negative impact on speech identification of the elderly.8 In a trustworthy age-matched study, Füllgrabe et al9 measured the correct percentage in sentence identification for 21 older adults with normal hearing under background noise and compared their speech identification scores with those of younger peers. Although all participants had similar hearing sensitivity, there was a big score difference between younger and older adults. The results suggest an age-related deficit for speech recognition even in the elderly with normal hearing, while having a large individual variance. As one of the factors contributing to poor performance in speech recognition, Füllgrabe8 proposed that the ability to process temporal-fine-structure cues dropped significantly with age, the loss even being observed in the middle-aged. Tun et al10 added that age-related sensory loss exacerbated elderly listeners’ vulnerability to distraction by either a multi-talker background or a fast rate in the talker’s speech, which go beyond auditory acuity or simple acoustic masking. That is, the aging effects are negatively noticeable in listening to target speech in those difficult listening conditions, whether having good hearing for the listener’s age or not,11 consequently resulting in a possible large individual variance of speech recognition for the elderly if they have hearing loss.
On the other hand, elderly listeners are predisposed to assume the meaning in a way that their younger counterparts are not.7,12 Nittrouer and Boothroyd12 found that the elderly used lexical constraints to a greater extent than young children and that extent was even more dependent than their younger peers on semantic context for speech recognition. They argued that the recognition scores of the elderly did not interfere with their ability to use linguistic knowledge in perceiving speech although the elderly had lower scores than younger adults. That is, elderly listeners have more or at least similar knowledge of semantic constraints as young listeners, and thus they can use that knowledge to the same extent and show an enhanced effect of lexical context. However, as already mentioned in the previous paragraph, performance deficits in elderly listeners were often observed even when hearing levels were matched between younger and older subjects.8,9 The researchers concluded that declines in speech perception affected by cognitive and perceptual changes with age might be distinguished from simple age-related audiometric loss.13 In other words, this suggests that older adults have their own specific way to perceive speech even though their audiometric hearing threshold is not as perfect as their young peers’. Therefore, while examining overall speech recognition, their performance should be scrutinized to identify the important attributes of speech recognition deficits in the elderly.11
In summary most researchers have agreed that speech recognition ability between younger and older adult groups differs even with similar levels of hearing sensitivity.9 Furthermore, the consensus is that age-related hearing difficulties, auditory processing deficits, and cognitive decline make it difficult for both the elderly with normal hearing and the hearing-impaired elderly to understand speech, especially in difficult listening conditions such as background noise and a fast rate of speech.14,15 Nevertheless, these findings did not connect to improve speech recognition ability in the elderly in terms of aural rehabilitation. In other words, although a few studies have begun to describe phonemic confusion only in hearing-impaired adults,16 there is still a lack of information about error types and patterns in perceiving speech,17,18 which would describe an additional aspect of speech recognition for the elderly. If their nature is identified, a new strategy for auditory training can be developed in terms of more effective aural rehabilitation.9,19,20
A previous study found that the hearing-impaired elderly made prominent and common noun errors in sentence recognition, although the study was conducted with a small sample.9 Nouns are the names of things, and they do not change in the form of parts of speech. They can be subjects, objects, or adjectives, but they play a larger role than other parts of speech.21 On the other hand, there were relatively few errors in other parts of speech because it is easy to guess or listen according to the context within sentences. Therefore, if errors in nouns, which play the most important role in conveying the meaning of sentences, are higher than in other parts of speech, this can have the most negative effect on the elderly listener’s perception.22 In this light, the purpose of the present study was to measure error percentage and analyze prominent error types and specific error patterns in the elderly with differences in audiometric loss and word recognition, under various listening conditions. We hypothesized that the elderly with hearing loss has higher error percentage in the difficulty listening condition although both groups with and without hearing loss show some degree of error. We also hypothesized that noun errors become noticeable as listening conditions deteriorate for the elderly, as supported by previous research, but a different error pattern exists in the hearing-ability groups.
Materials and methods
Subjects
Forty older adults with normal hearing for their age (NHiA; n=20) and sensorineural hearing loss (SNHL; n=20) who had a normal range of cognitive function (>25 scores in MMSE-K)23 voluntarily participated in this study. They came from senior communities in Chuncheon, South Korea. Their average age was 73.51 years, and the age range was 68–81 years. Tympanometry and pure-tone audiometry of both air and bone conduction were conducted as a hearing screening. All subjects had normal ear-drum mobility and a type-A tympanogram. The NHiA group had thresholds within the normal hearing range as a function of age (average of 0.5–1, 2 kHz ≤29 dB HL),24 whereas the SNHL group showed moderate-to-severe sensorineural hearing loss (40 dB HL ≤ average of 0.5–1, 2 kHz ≤75 dB HL) in the better ear.
Among 20 moderate-to-severe SNHL listeners, 12 having high performance in word recognition score (WRS). Four lists which consisted of 50 standardized monosyllables were randomized and one list was presented at the most comfortable level of participants26 (>70%) and eight having low performance in WRS (<70%) were designated as SNHL with high performance (SNHL-H) and low performance (SNHL-L), respectively.25 No significant difference in hearing sensitivity existed between the two groups (P>0.05). The SNHL subjects had used hearing aids for approximately 3 years (detailed group information is listed in Table 1). All subjects were native Korean speakers and signed an informed consent form before beginning the experiment. All procedures were approved by the Institutional Review Board of Hallym University (#HIRB-2015–027).
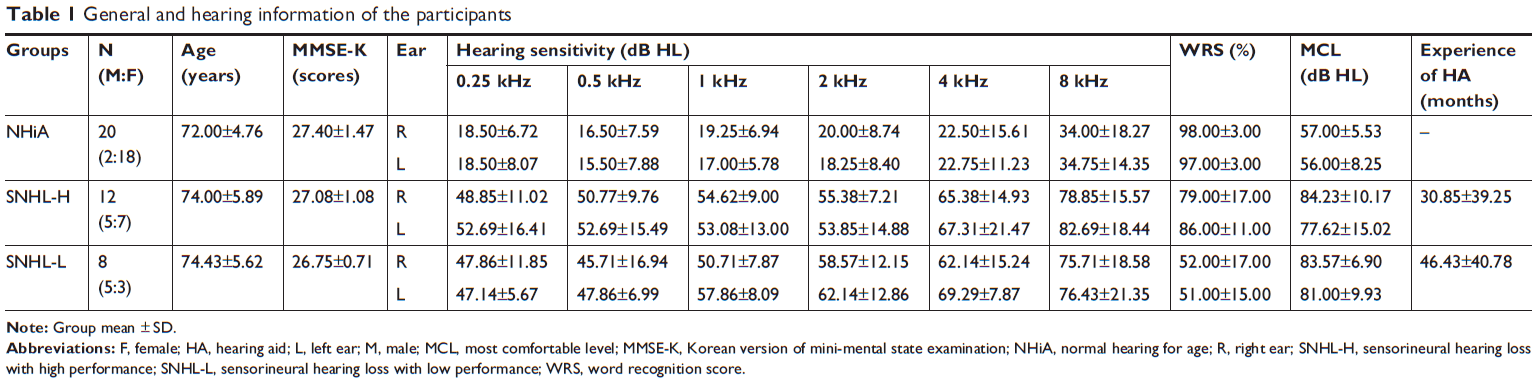 | Table 1 General and hearing information of the participants |
Sentence stimuli
To estimate participants’ performance in sentence recognition, the Korean Speech Perception in Noise (KSPIN)27 was used; question tags of the original KSPIN sentences were removed because they had overlapping words with sentences that might provide clues to participants. Twenty sentences per list comprise the KSPIN lists. After being recorded on a compact disc (CD) by a male speaker, the sentences were equalized in root mean square (RMS) using Adobe Audition software (version CC2014.2, Adobe Systems Incorporated, San Jose, CA, USA). Then, the sentences were presented in quiet (or no noise) and mixed with a 12-talker babble for three noise levels (+6, +3, and 0 dB signal-to-noise ratios [SNRs]). The multi-talker babble noise was typically combined with either the original SPIN in English or the KSPIN because of interfering sentences for informational masking.28
For the sentence recognition test based on speech rate change, four conditions of time alteration, which is two expansions (+30% for very slow rate and +15% for slow rate) and two compressions (−15% for fast rate and −30% for very fast rate) were developed by the Adobe Audition software. Except for speech speed manipulated in the time domain, the other components for speech, such as fundamental frequency and formants, were retained.22
Experimental procedures
During the measurement of speech recognition, subjects were asked to listen to sentences played on the CD player at their most comfortable listening level through a loud speaker located at 0 degrees azimuth and a 1-meter distance; the CD player was connected to an audiometer (Model GSI 61; Grason-Stadler, Eden Prairie, MN, USA) in a sound isolation double-chamber. Twelve sentence lists were pseudo-randomized across the subjects in four different SNRs and four different time-altered conditions from easy to hard (ie, quiet to 0 dB SNR, 30% expansion to 30% compression). After completing the measurement, the total number of errors and the error types and patterns of each subject were analyzed as a function of the conditions by two trained audiologists.
Data analysis
The error percentage of the three groups was calculated by the number of incorrect syllables in the given sentences in each condition. The percentage scores of the three groups were compared and statistically confirmed by a two-way repeated-measures analysis of variance (ANOVA) using SPSS software (version 22; IBM Corporation, Armonk, NY, USA). If necessary, a Bonferroni correction was applied for post-hoc testing. The criterion of statistical significance was P<0.05.
To analyze error types and patterns, the number of incorrect answers was calculated by two audiologists. They also classified the error types into nine parts of speech: noun, pronoun, numeral, verb, adjective, determiner, adverb, interjection, and postposition (lists of KSPIN tests used in the present study had been developed and standardized by considering Korean word frequency.27 In addition, a linguistic professional confirmed similar degree of each part of speech across the 12 lists before conducting the experiment).
Then, among the nine parts of speech, the noun errors, which represented the most dominant errors of the sentence, were tabulated as seven subgroups of substitution, addition, omission, substitution plus omission, substitution plus addition, fail (or 100% incorrect), and no response, following strategies from a previous study.17 For example, when the word, ‘C1-V-C2, V-C3’ (C: consonant, V: vowel), was spoken as ‘C4-V-C2, V-C3’, this error was defined as ‘substitution.’ However, if a morpheme was skipped (C4-V-C2, V) or added (C4-V-C2, C5-V-C3), we called those errors ‘substitution plus omission’ and ‘substitution plus addition,’ respectively. ‘Addition’ was the supplement of morpheme, whereas ‘omission’ was the removal of morpheme. ‘Fail’ was 100% incorrect with respect to morphemes in words. Nonresponse to sentences was considered ‘no response.’ Two audiologists discussed and determined the type and pattern of an error if a discrepancy arose. Their inter-rater reliability was κ=0.797 (P<0.001) with high consistency. Finally, another researcher verified the parts of speech using a dictionary function of NAVER, one of the most powerful search engines in Korea.
Results
Effect of background noise
Figure 1 displays the percentage scores for sentence recognition of the three groups in the four SNR conditions. For the NHiA group, error percentages were much lower than for both SNHL-H and SNHL-L, at 26.25% (SD: 15.12), 28.42% (SD: 14.72), 28.75% (SD: 14.06), and 33.08% (SD: 15.94) in quiet and +6, +3, and 0 dB SNR conditions, respectively. Also, error percentages only increased slightly with decreasing SNR. The two SNHL groups showed a similar slope and pattern with decreasing SNR. The SNHL-H group scored 44.72% (SD: 19.87), 60.14% (SD: 21.11), 58.06% (SD: 22.88), and 65.00% (SD: 24.44) in quiet and +6, +3, and 0 dB SNR conditions, respectively. SNHL-L showed the highest error percentage among the three groups at 53.89% (SD: 16.76), 67.50% (SD: 17.54), 66.67% (SD: 16.09), and 75.56% (SD: 12.72) in quiet and +6, +3, and 0 dB SNR conditions, respectively.
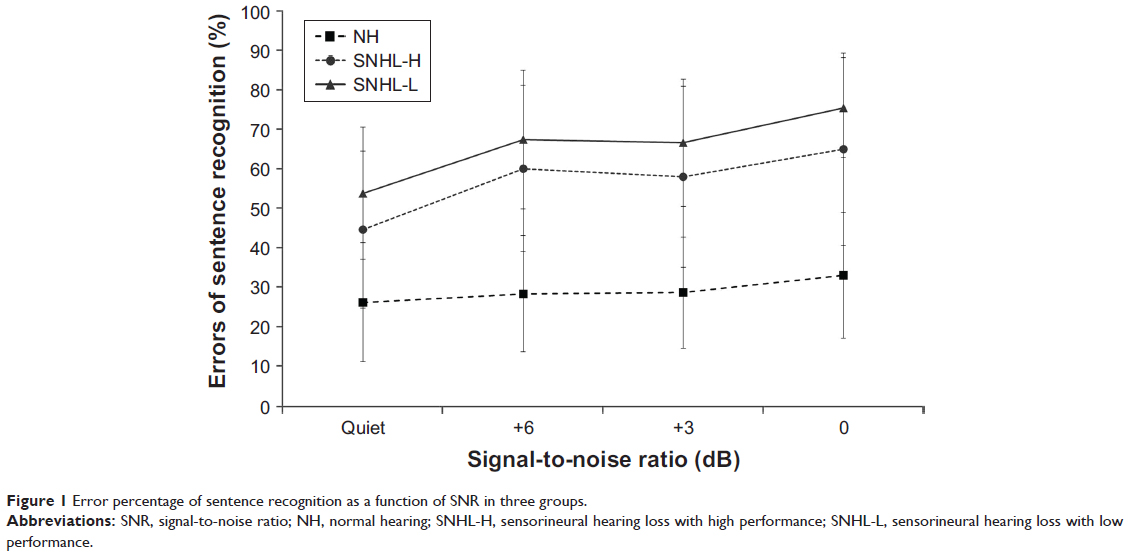 | Figure 1 Error percentage of sentence recognition as a function of SNR in three groups. |
The ANOVA confirmed a significant main effect for SNR [F(3, 105)=17.807, P<0.001] and group of hearing loss [F(2, 35)=17.853, P<0.001]. In the degree of background noise, the quiet condition (mean: 41.62%, SD: 3.14) showed a significantly lower error than the +6 dB (P=0.001; mean: 52.02%, SD: 3.20) and +3 dB SNR (P=0.006; mean: 51.16%, SD: 3.24), which were significantly lower than in the 0 dB SNR condition (P=0.000; mean: 57.88%, SD: 3.44). For the group of hearing loss, the NHiA group (mean: 29.13%, SD: 3.61) had a significantly lower error percentage than both SNHL-H and SNHL-L at 56.98% (SD: 4.67) and 65.90% (SD: 6.60), respectively. Although a small difference was found in the error percentage among the three groups in the quiet condition, there was a significant difference in the error percentage between one NHiA group and two SNHL groups that showed a high error percentage of approximately 55%–70% as a factor of hearing loss when background noise was presented.
Table 2 shows that for all groups the total error number increased as the level of background noise increased. The total error number of the NHiA group was not sensitive to the noise level. As confirmed in Figure 1, however, two SNHL groups produced higher errors as the noise level increased. Among the nine parts of speech, noun errors were the most prominent regardless of noise level and hearing status, which seemed to be a cognitive aging factor. In addition, postposition and verb errors were analyzed as the second and third most common error types, respectively. However, interjection errors were not seen since the sentences of the KSPIN test did not include any declarative sentences.
 | Table 2 Percentage scores in sentence recognition for three groups |
Noun errors, the highest, as shown in bold style of Table 3, were reanalyzed into seven error patterns (Table 4). A pattern of no response was remarkable in all groups. The NHiA group had a 65%–69% no response pattern in total noun errors, and the two SNHL groups had a very high error rate in the no response pattern of up to 87%. Fail and substitution error patterns followed as the second and third highest. The rest of the noun errors were categorized into one of four error patterns.
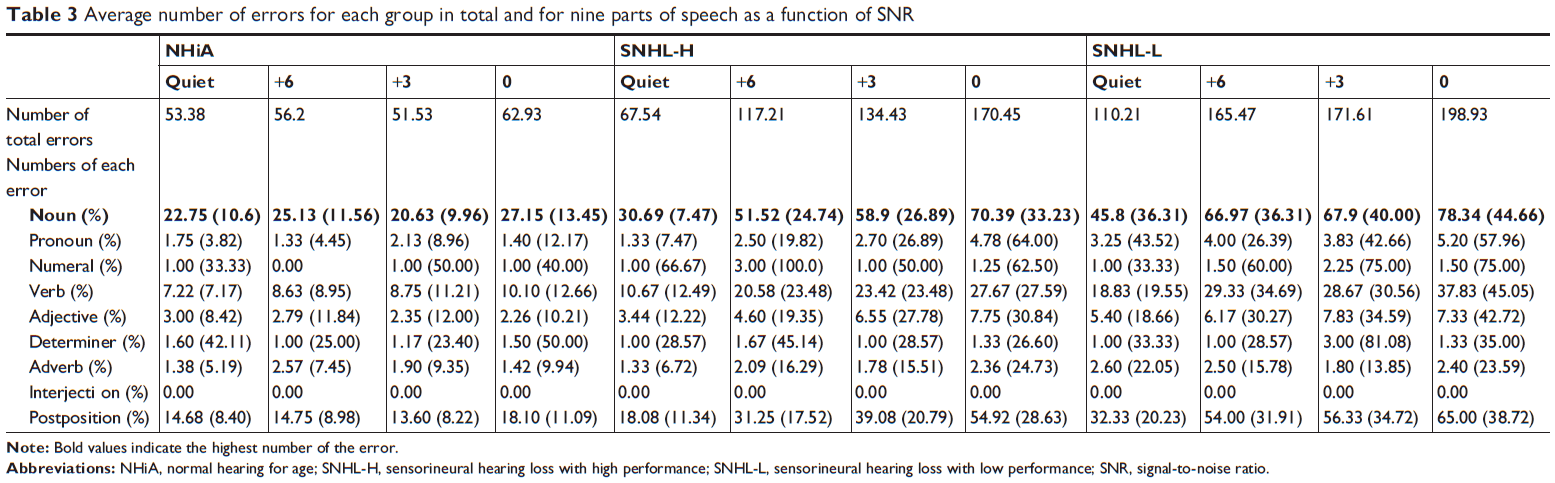 | Table 3 Average number of errors for each group in total and for nine parts of speech as a function of SNR |
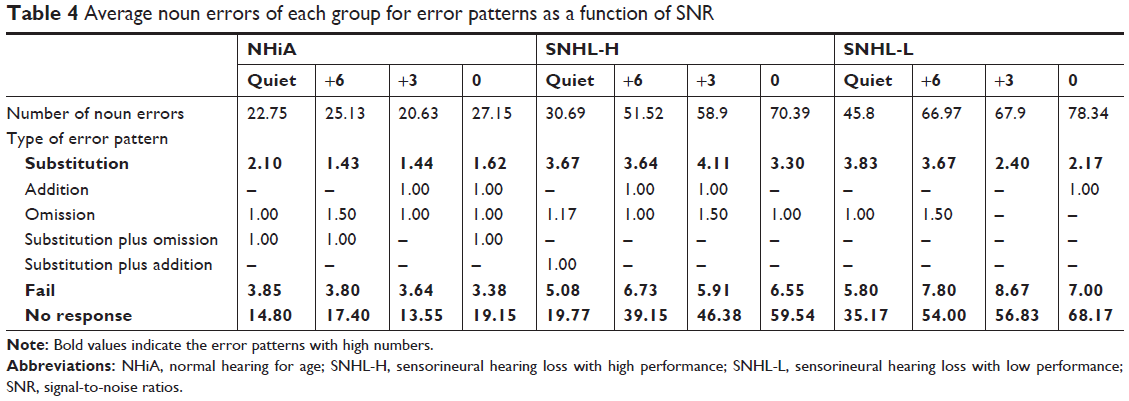 | Table 4 Average noun errors of each group for error patterns as a function of SNR |
Effect of slow/fast rate of speech
Figure 2 displays the percentage scores for sentence recognition for the three groups in four time-altered conditions. The error percentages for the NHiA group were much lower than for both SNHL-H and SNHL-L, at 25.67% (SD: 18.01), 29.33% (SD: 16.85), 31.42% (SD: 20.21), and 31.08% (SD: 18.38) in +30%, +15%, −15%, and −30% time-alteration conditions, respectively. Although the error percentage of the NHiA group did not change regardless of the speed of speech, the error percentage of the two SNHL groups gradually increased as the rate of speech grew faster. SNHL-H scored 38.89% (SD: 25.68) for the +30% condition, 42.50% (SD: 24.52) for +15%, 49.03% (SD: 27.29) for −15%, and 58.06% (SD: 25.72) for −30%. SNHL-L had the highest error percentage at 54.44% (SD: 5.54), 59.44% (SD: 6.64), 67.78% (SD: 4.43), and 83.33% (SD: 6.41) in the +30%, +15%, −15%, and −30% conditions, respectively.
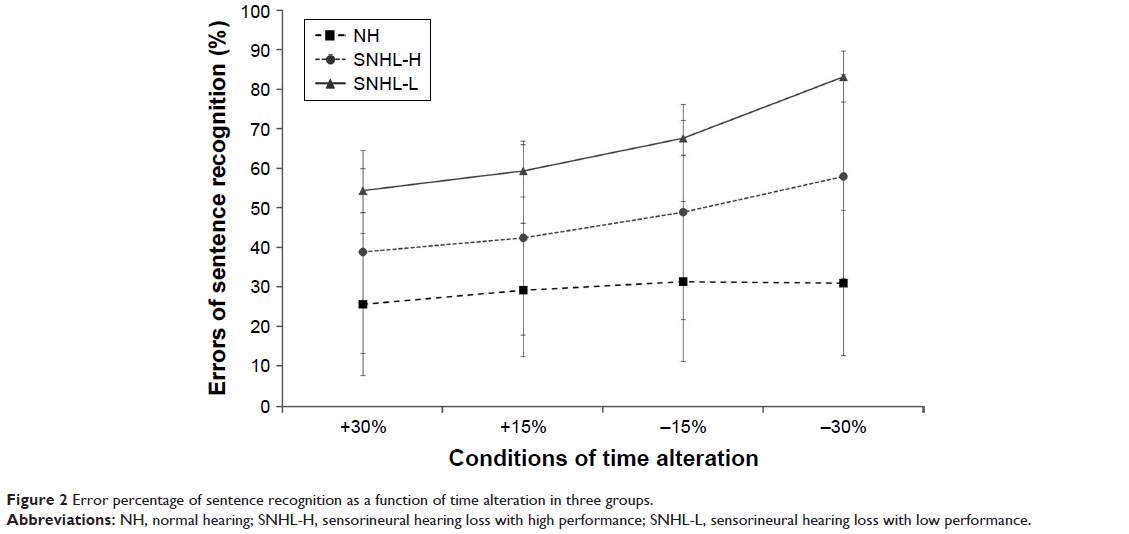 | Figure 2 Error percentage of sentence recognition as a function of time alteration in three groups. |
The ANOVA confirmed a significant main effect for both the speed of speech [F(3, 105)=38.88, P<0.001] and the group [F(2, 35)=9.34, P<0.001]. In the speed of speech, the +30% condition (mean: 39.67%, SD: 3.64) showed a significantly lower error rate than the +15% (P=0.019; mean: 43.76%, SD: 3.45) and −15% (P=0.000; mean: 49.41%, SD: 3.96) conditions, which were significantly lower than in the −30% condition (P=0.000; mean: 57.49%, SD: 3.68). For the type of hearing loss, the NHiA group (mean: 29.13%, SD: 3.61) showed a significantly lower error rate (37.12%) than the SNHL-L group (P=0.012; mean: 66.25%, SD: 7.89), but it did not differ from the SNHL-H group (P=0.057; mean: 47.12%, SD: 5.58). That is, the NHiA and SNHL-H groups were not significantly divided by time alteration in terms of speech recognition, which means that the degree of hearing loss was not reflected in the error percentage. Instead, according to time alteration, the NHiA group and SNHL-L group had significant differences possibly induced by audiometric hearing sensitivity, poor supra-threshold auditory processing, declined cognitive abilities, or a possible combination of these factors.
Using a similar method as used in Table 3, Table 5 also summarizes the number of total errors and of each error for the three groups in the time-altered conditions. Compared to a slow speed, such as +30% and +15%, the fast speed condition showed a higher number of errors in all groups, as expected. Among the nine parts of speech, noun errors ranked highest (Please see the bold style in Table 5). In particular, the SNHL-L group had much higher error numbers when speech was faster. Like the condition of background noise, postposition and verbs were the second and third highest error types, respectively, in all groups. It seemed a feature of the elderly listeners to perceive the sentences.
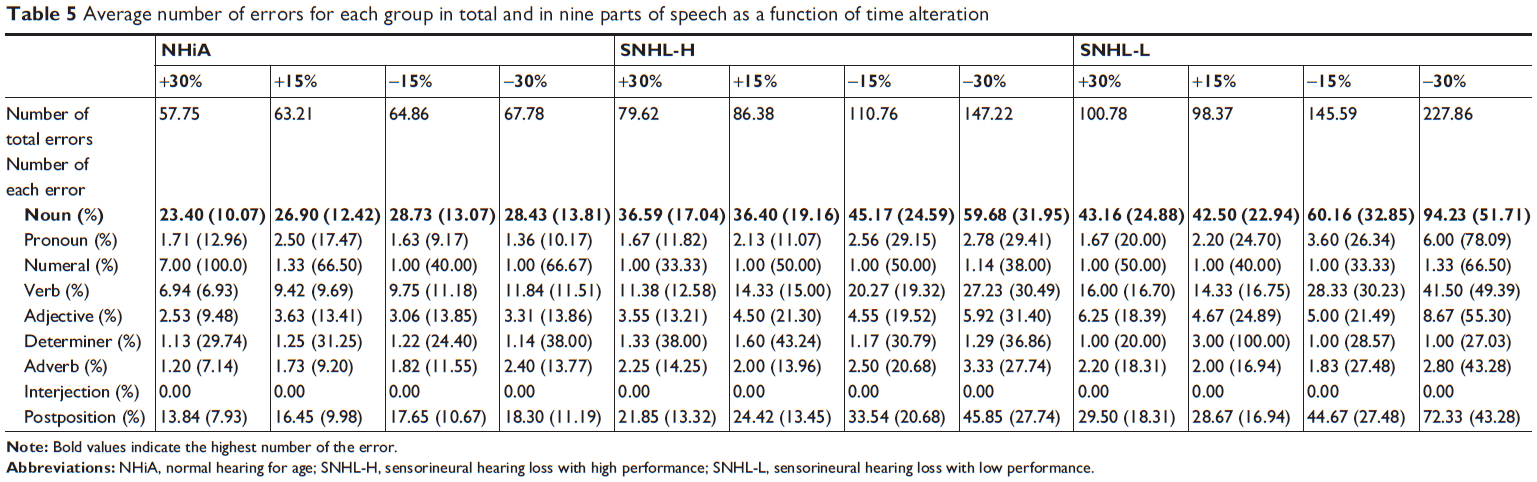 | Table 5 Average number of errors for each group in total and in nine parts of speech as a function of time alteration |
Based on the display in Table 6, the pattern of noun errors under time alteration was no response, fail, and omission. The no response pattern increased in terms of number of errors in the three groups as speech grew faster, especially in the two SNHL groups. However, numbers for the fail and omission error patterns did not change much in respect to the rate of speech, but did differ across the groups (Please see the bold style in Table 6). Compared to Table 4, reflecting results from the background noise condition, the omission pattern did appear in the time alteration although it did not have a high error rate.
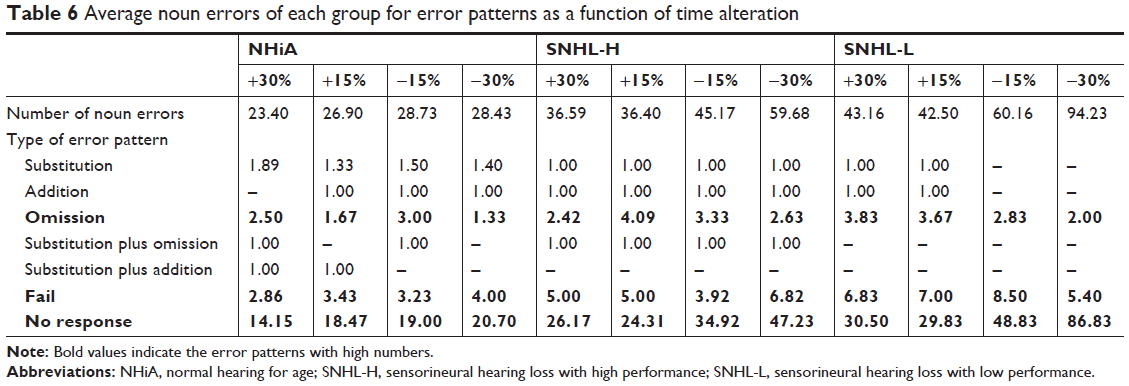 | Table 6 Average noun errors of each group for error patterns as a function of time alteration |
Discussion
The purpose of the present study was to evaluate the error percentage and prominent error types among nine parts of speech in older adults and to investigate which major error patterns appeared in various levels of background noise and speeds of speech.
As expected, the number of errors increased in sentence recognition as either the SNR decreased or the rate of speech grew faster. Although the current results were supported by several previous studies,17,18,20 they additionally showed a different pattern between the difficult conditions of background noise and time alteration. For instance, the data for background noise demonstrated that the SNHL groups’ speech recognition was significantly more vulnerable to interference from noise than the NHiA groups (Figure 1).7,10 However, error scores in the speed of speech conditions revealed that the SNHL-L group that had a reduced supra-threshold auditory processing and cognitive function had significantly more difficulty in comprehension of compressed/fast speech than the SNHL-H group that had similar audiometric hearing loss and better performance for word recognition (Figure 2).10 Some researchers have proposed that sentence recognition of the elderly with different hearing thresholds, such as the NHiA and two SNHL groups in our study, can be differentiated in background noise as frequency resolution,1,4 while the elderly groups with the same hearing loss and different word recognition ability (eg, SNHL-H and SNHL-L) showed dissimilar performance in speed of speech conditions, which means that the hearing-impaired elderly with poor word recognition were especially distracted by semantically meaningful speech with speed (or poor temporal resolution).9,10 This is consistent with Gordon-Salant’s results11 in that no significant difference in speech recognition existed among the elderly with different configurations of hearing loss due to age-related neuronal loss in the superior olivary complex.10 In addition, Hwang et al7 indicated that the elderly may find it more difficult than younger adults to use the harmonic structure of speech associated with prosody in fast speech due to temporal processing difficulty. A very recent study conducted by Füllgrabe et al13 well explained that age-dependent changes influenced to reduced sensitivity and processing of temporal fine structures information, resulting in impact on speech recognition of the elderly even though there was a large individual difference.
On the other hand, among the parts of speech, the noun, postposition, and verb presented the highest error numbers for all participants regardless of noise level or time alteration. It seems that elderly listeners have a specific way to perceive a sentence in terms of having poor cognitive function. This result was well supported by Na et al,22 who reported prominent noun and postposition error types. Ironically, the noun, for which elderly listeners made large errors, is one of the key factors in understanding sentences. Hwang et al7 pointed out that error rates for nouns, which play the most important role in conveying the meaning of a sentence, are higher than for other parts of speech; thus, they can have the most negative effect on the elderly listener’s perception. Furthermore, the high level of noun errors even in a quiet environment suggested that rehabilitation is likely needed, especially for the elderly.22,28 Of course, each list of 20 sentences consisted of a high number of nouns, close to 40% – noun (38%), postposition (31%), verb (16%), adjective (5%), adverb (5%), determiner (2%), pronoun (2%), interjection (0.3%), and numeral (0.3%) – in general, which highly supported Seo’s analysis.29 One can argue that more noun errors exist in the present study since more nouns were used in the sentence materials. However, if having reversed thought, noun errors should be the focus in aural diagnosis and treatment of older adults because of the high number of nouns in Korean aural language (and even in other languages).
The noun errors mainly consisted of no response and fail patterns in both the NHiA and SNHL groups, a trend that was magnified as either noise levels increased or speech grew faster. Chun et al17 reported a similar pattern in a sample that did not include elderly subjects. Their adult group with normal hearing showed substitution errors dominantly regardless of the noise level, but hearing-impaired groups wearing hearing aids and/or having a cochlear implant had remarkable no response error types, rather than declined substitution errors. As one possibility for these contradictory findings, their study used monosyllabic words to measure errors in speech recognition, but we used sentences for this. More interestingly, the current study showed that the third pattern in noun errors was not the same in noise and time-alteration conditions. For example, a substitution pattern was revealed in the noise condition and an omission pattern was found in the time-alteration condition, which interfered through difficult listening conditions rather than the elderly listener’s ability to perceive speech. Tun et al10 explained that this phenomenon may impose especially heavy processing demands on older adults’ more limited resources relative to younger adults. As a result, such a decline in executive control may underlie older adults’ particular difficulty in ignoring irrelevant information. Although the current study did not include data of young adults as a control group, elderly listeners are more impaired than younger listeners by meaningful distractors, particularly when the distractors are semantically related to the target material.10 We assumed that background noise drove the elderly toward a substitution pattern, whereas fast speech reflected an omission error pattern, but comparative data do not yet exist from previous studies, even in other languages, since this approach is a new and challengeable concept.
Limitations
This research had limitations that warrant further study. First, the number of participants should be increased to generalize the current results in a more powerful way, although inclusion of 40 older adults was not easy. Moreover, the test-retest reliability of the current data needs to be confirmed. Bilger and Wang16 also reported idiosyncratic patterns of speech recognition for individual hearing-impaired patients. That is, error patterns for individual listeners stabilized rather quickly, with the largest number of errors occurring in the first testing session. A second issue stems from not including younger listeners as counterparts to our subjects. We need to confirm more obvious aging or auditory-cognitive functions while comparing elderly listeners to younger listeners with similar hearing loss. Third, our normal hearing participants had hearing sensitivity within the normal range for their age. Although their inclusion criteria followed the international standard (ISO-7029),24 the best sensitivity match, like the study conducted by Füllgrabe et al,9 should be considered. Finally, in a similar study contrasting patients with several possible pathologies related to presbycusis, both within and between diagnostic group data might provide highly useful diagnostic and rehabilitation directions.
Conclusion
Under various levels of background noise and time-alteration conditions, speech perception was measured in 40 elderly participants who had NHiA and SNHL-H and SNHL-L performance with criteria of 70% correct;25 the subjects’ sentence perception was then analyzed in terms of error percentage, error type, and error pattern to identify the factors associated with audiometric loss and age-related deficits. Key findings include the following: as either the noise level grew louder or speech became faster, the percentage scores significantly increased in the SNHL groups. However, background noise and time alteration conditions showed different patterns. With background noise, there was a significant difference in the percentage scores between the NHiA and SNHL groups as a factor of audiometric loss, whereas the error percentage of the NHiA group differed from that of the SNHL-L group, which considered lower hearing sensitivity, poor supra-threshold auditory processing, and differences in cognitive abilities, but not from that of the SNHL-H group. In the background noise and time-alteration conditions, all three groups had the highest noun error rate in their perceptions of sentences, although their error numbers differed. Also, postposition and verb errors followed noun errors as common error types in the elderly. Specifically, when the noun errors were divided into seven error patterns, the no response error pattern was highly robust in all groups and the fail error pattern was the second most robust. However, the third pattern in noun errors was not the same in the background noise and time-alteration conditions. For example, a substitution pattern was revealed in the noise condition, but an omission pattern appeared in time alteration. Although the percentage scores, error types, and error patterns were affected by either the audiometric loss or age-related deficits in the elderly, the type of difficult listening condition also affected their speech recognition performance.
In conclusion, the effects of hearing and cognitive loss were seen under difficult listening environments such as background noise and time alteration in the elderly. Regardless of a slightly different group performance across the eight experimental conditions, the robustness of the noun errors and their error patterns were very similar, which might be extended to a possible clinical application of aural rehabilitation for the elderly population.22
Acknowledgments
The preliminary data of this work were presented at 2018 Audiology Now in American Academy of Audiology (Nashville, TN, USA). This paper was supported by Hallym University Research Fund 2018 (H20180250) and the Ministry of Education of the Republic of Korea and the National Research Foundation of Korea (NRF-2015S1A3A2046760).
Disclosure
The authors report no conflicts of interest in this work.
References
Gates GA, Mills JH. Presbycusis. Lancet. 2005;366(9491):1111–1120. | ||
Morrell CH, Gordon-Salant S, Pearson JD, Brant LJ, Fozard JL. Age- and gender-specific reference ranges for hearing level and longitudinal changes in hearing level. J Acoust Soc Am. 1996;100(4 Pt 1):1949–1967. | ||
Spoor A. Presbycusis values in relation to noise induced hearing loss. Int Audiol. 1967;6(1):48–57. | ||
Dubno JR, Dirks DD, Morgan DE. Effects of age and mild hearing loss on speech recognition in noise. J Acoust Soc Am. 1984;76(1):87–96. | ||
Hanratty B, Lawlor DA. Effective management of the elderly hearing impaired – a review. J Public Health Med. 2000;22(4):512–517. | ||
Pichora-Fuller MK, Schneider BA, Daneman M. How young and old adults listen to and remember speech in noise. J Acoust Soc Am. 1995;97(1):593–608. | ||
Hwang JS, Kim KH, Lee JH. Factors affecting sentence-in-noise recognition for normal hearing listeners and listeners with hearing loss. J Audiol Otol. 2017;21(2):81–87. | ||
Füllgrabe C. Age-dependent changes in temporal-fine-structure processing in the absence of peripheral hearing loss. Am J Audiol. 2013;22(2):313–315. | ||
Füllgrabe C, Moore BC, Stone MA. Age-group differences in speech identification despite matched audiometrically normal hearing: contributions from auditory temporal processing and cognition. Front Aging Neurosci. 2014;6:347. | ||
Tun PA, O’Kane G, Wingfield A. Distraction by competing speech in young and older adult listeners. Psychol Aging. 2002;17(3):453–467. | ||
Gordon-Salant S. Consonant recognition and confusion patterns among elderly hearing-impaired subjects. Ear Hear. 1987;8(5):270–276. | ||
Nittrouer S, Boothroyd A. Context effects in phoneme and word recognition by young children and older adults. J Acoust Soc Am. 1990;87(6):2705–2715. | ||
Füllgrabe C, Sęk AP, Moore BCJ. Senescent changes in sensitivity to binaural temporal fine structure. Trends Hear. 2018;22:2331216518788224. | ||
Gordon-Salant S. Hearing loss and aging: new research findings and clinical implications. J Rehabil Res Dev. 2005;42(4 Suppl 2):9–24. | ||
Humes LE, Coughlin M, Talley L. Evaluation of the use of a new compact disc for auditory perceptual assessment in the elderly. J Am Acad Audiol. 1996;7(6):419–427. | ||
Bilger RC, Wang MD. Consonant confusions in patients with sensorineural hearing loss. J Speech Hear Res. 1976;19(4):718–748. | ||
Chun H, Ma S, Han W, Chun Y. Error patterns analysis of hearing aid and cochlear implant users as a function of noise. J Audiol Otol. 2015;19(3):144–153. | ||
Han W, Chun H, Kim G, Jin IK. Substitution patterns of phoneme errors in hearing aid and cochlear implant users. J Audiol Otol. 2017;21(1):28–32. | ||
Ferguson MA, Henshaw H, Clark DP, Moore DR. Benefits of phoneme discrimination training in a randomized controlled trial of 50- to 74-year-olds with mild hearing loss. Ear Hear. 2014;35(4):e110–e121. | ||
Lee JY, Hwang HK, Jang HS. Communication difficulties as a function of hearing sensitivity and speech recognition in elderly with hearing loss. J Rehabilitat Res. 2014;8:331–352. | ||
Hong SI. Development of phonological awareness in Korean children. Commun Sci Disord. 2002;7(1):49–64. | ||
Na W, Kim G, Kim G, Lee J, Han W. Sentence recognition error of hearing-impaired elderly in background noise and time alteration: case analysis. Audiol Speech Res. 2016;12(4):280–288. | ||
Kwon YC, Park JH. Korean version of mini-mental state examination (MMSE-K). Part I: development of the test for the elderly. J Korean Neuropsychiatr Assoc. 1989;28:125–135. | ||
International Organization for Standardization (ISO)-7029. Acoustics – statistical distribution of hearing threshold as a function of age. 2000(en). Available from: https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=3&ved=2ahUKEwiK9Pal-OfdAhWBwLwKHTAOCSAQFjACegQIBxAC&url=https%3A%2F%2Fwww.sis.se%2Fapi%2Fdocument%2Fpreview%2F616590%2F&usg=AOvVaw1gpbfmms8WMpGpPhDYStsi. Accessed October 2, 2018. | ||
Phillips SL, Gordon-Salant S, Fitzgibbons PJ, Yeni-Komshian G. Frequency and temporal resolution in elderly listeners with good and poor word recognition. J Speech Lang Hear Res. 2000;43(1):217–228. | ||
Kim JS, Lim DH, Hong HN. Development of Korean standard monosyllabic word lists for adults (KS-MWL-A). Audiology. 2008;4(2):126–140. | ||
Kim JS, Bae SY, Lee JH. Development of a test of Korean speech intelligibility in noise (KSPIN) using sentence materials with controlled word predictability. Korean J Speech Sci. 2000;7(2):37–50. | ||
Brungart DS, Simpson BD, Ericson MA, Scott KR. Informational and energetic masking effects in the perception of multiple simultaneous talkers. J Acoust Soc Am. 2001(110):2527–2538. | ||
Seo SK. Investigation of word frequency based on corpus analysis and its application. Han-geul. 1998;242:225–270. |
 © 2018 The Author(s). This work is published and licensed by Dove Medical Press Limited. The
full terms of this license are available at https://www.dovepress.com/terms
and incorporate the Creative Commons Attribution
- Non Commercial (unported, 3.0) License.
By accessing the work you hereby accept the Terms. Non-commercial uses of the work are permitted
without any further permission from Dove Medical Press Limited, provided the work is properly
attributed. For permission for commercial use of this work, please see paragraphs 4.2 and 5 of our Terms.
© 2018 The Author(s). This work is published and licensed by Dove Medical Press Limited. The
full terms of this license are available at https://www.dovepress.com/terms
and incorporate the Creative Commons Attribution
- Non Commercial (unported, 3.0) License.
By accessing the work you hereby accept the Terms. Non-commercial uses of the work are permitted
without any further permission from Dove Medical Press Limited, provided the work is properly
attributed. For permission for commercial use of this work, please see paragraphs 4.2 and 5 of our Terms.