Back to Journals » Clinical Interventions in Aging » Volume 15
Senescent Decline in Verbal-Emotion Identification by Older Hearing-Impaired Listeners – Do Hearing Aids Help?
Authors Ruiz R, Fontan L, Fillol H, Füllgrabe C ![]()
Received 12 September 2020
Accepted for publication 14 October 2020
Published 3 November 2020 Volume 2020:15 Pages 2073—2081
DOI https://doi.org/10.2147/CIA.S281469
Checked for plagiarism Yes
Review by Single anonymous peer review
Peer reviewer comments 2
Editor who approved publication: Dr Richard Walker
Robert Ruiz,1 Lionel Fontan,2 Hugo Fillol,3,4 Christian Füllgrabe5
1Laboratoire de Recherche en Audiovisuel (LARA-SEPPIA), Université Toulouse II Jean Jaurès, Toulouse, France; 2Archean LABS, Montauban, France; 3Service d’Oto-Rhino-Laryngologie, d’Oto-Neurologie et d’ORL Pédiatrique, Centre Hospitalier Universitaire de Toulouse, Toulouse, France; 4Ecole d’Audioprothèse de Cahors, Université Toulouse III Paul Sabatier, Toulouse, France; 5School of Sport, Exercise and Health Sciences, Loughborough University, Loughborough, UK
Correspondence: Christian Füllgrabe
School of Sport, Exercise and Health Sciences, Loughborough University, Ashby Road, Loughborough LE11 3TU, UK
Tel +44 1509 223009
Email [email protected]
Purpose: To assess the ability of older-adult hearing-impaired (OHI) listeners to identify verbal expressions of emotions, and to evaluate whether hearing-aid (HA) use improves identification performance in those listeners.
Methods: Twenty-nine OHI listeners, who were experienced bilateral-HA users, participated in the study. They listened to a 20-sentence-long speech passage rendered with six different emotional expressions (“happiness”, “pleasant surprise”, “sadness”, “anger”, “fear”, and “neutral”). The task was to identify the emotion portrayed in each version of the passage. Listeners completed the task twice in random order, once unaided, and once wearing their own bilateral HAs. Seventeen young-adult normal-hearing (YNH) listeners were also tested unaided as controls.
Results: Most YNH listeners (89.2%) correctly identified emotions compared to just over half of the OHI listeners (58.7%). Within the OHI group, verbal emotion identification was significantly correlated with age, but not with audibility-related factors. The number of OHI listeners who were able to correctly identify the different emotions did not significantly change when HAs were worn (54.8%).
Conclusion: In line with previous investigations using shorter speech stimuli, there were clear age differences in the recognition of verbal emotions, with OHI listeners showing a significant reduction in unaided verbal-emotion identification performance that progressively declined with age across older adulthood. Rehabilitation through HAs did not provide compensation for the impaired ability to perceive emotions carried by speech sounds.
Keywords: verbal-emotion identification, older adulthood, age-related hearing loss, hearing aids, speech prosody
Introduction
It has long been known that vocalizations play an important role in conveying emotions.1 In the case of speech, the acoustic signal carries emotional information in several ways, for example the duration of the speech segments and their rhythm, the voice quality, the levels of intensity and the fundamental frequency and their variations over time.2–4 There is substantial evidence that the ability to identify vocally transmitted emotions tends to decrease with increasing age.5,6 However, there is no consensus as to the underlying mechanism(s) responsible for this decline (for a discussion, see Mitchell7): Is it the primary consequence of differential aging and degradation in neural mechanisms subtending emotion processing (eg, in the fontal and medial temporal lobes)8,9 or a secondary effect mediated by the ubiquitous age-related changes in hearing sensitivity10,11 and cognitive functioning12 associated with the aging process? Recent clinical interest for this aging phenomenon is based on the assumption that an impairment in the processing of voice emotion is associated with lower quality of life, poorer social relationships, and greater levels of depression.13,14 This raises the question of effective clinical interventions to mitigate the impact of this dysfunction on social interaction and everyday communication.
Hearing sensitivity, generally assessed by pure-tone audiometry, worsens progressively across the lifespan,15,16 with one third of the population aged 65 years and above being affected by disabling hearing loss.17 Hearing aids (HAs) are currently the most common form of treatment for age-related hearing loss (ARHL). They provide frequency-specific amplification that restores, at least partially, audibility of those sounds that are no longer perceived by the hearing-impaired (HI) person. Their benefits in terms of improved speech intelligibility have been widely demonstrated.18 However, relatively little is known about whether HAs also impact the ability to recognize verbal expressions of emotions. It can be speculated that, as for speech identification, the acoustic amplification provided by HAs makes more audible those auditory cues that are important for emotion perception (eg, pitch height and contour).19 On the other hand, some of the signal-processing schemes used in HAs (eg, dynamic range compression affecting the temporal envelope of the processed sounds) might distort acoustic cues,20,21 thereby having a deleterious effect on the ability to process vocal emotions.
So far, only a few studies investigated the auditory processing of voice emotions in speech in older-adult HI (OHI) persons when listening unaided and aided with HAs (for a recent overview, see Picou et al22). Schmidt et al23 assessed the emotional responses to speech sounds by asking OHI listeners (N=23), listening unaided or when wearing their own HAs, to rate short sentences in terms of valence (ie, their un/pleasantness) and arousal (ie, the level of activation produced). Those ratings were then compared to affect-related acoustic features (eg, the fundamental frequency, intensity) measured in the vocal stimuli. The results indicated that the OHI listeners, when listening through their HAs (but not when listening unaided), relied on acoustic cues similar to those used by young-adult normal-hearing (YNH) listeners, leading the authors to conclude that HAs help to restore the perception of vocal emotions.
Picou24 also assessed the perception of emotional valence and arousal in OHI listeners (N=13), but this time for nonspeech stimuli such as non-verbal human vocalizations (eg, laughter), animal vocalizations (eg, dog barking), and machine sounds (eg, dentist drill). In contrast to the findings of Schmidt et al,23 the ratings given by the OHI listeners were significantly different from those of the YNH listeners, even when the OHI listeners were fitted with hearing instruments used for research purposes. The signal processing provided by the HAs neither improved nor impaired the perception of emotions in the OHI listeners.
Finally, Goy et al25 studied the perception of vocal emotions in speech in OHI listeners (N=14) who had to identify speech stimuli portraying one of several possible emotional states (eg, happiness, sadness, fear). The linguistic material was taken from the emotional speech corpus developed by Dupuis and Pichora-Fuller.26 This corpus consists of short sentences each composed of the carrier phrase “Say the word … ” followed by a monosyllabic word (eg, “bean”, “bath”). Goy et al25 observed that emotion identification did not significantly improve when the OHI listeners wore their own HAs, and the OHI listeners’ performance (averaged across the unaided and aided conditions) was significantly worse than that of unaided YNH listeners.
The apparent discrepancy in results across studies might be due to the difference in tasks (valence and arousal ratings vs emotion identification), stimuli (speech vs nonspeech), and/or the OHI listeners’ familiarity with the HAs (personal HAs vs research HAs). Also, due to relatively small sample sizes used in these studies, there might have been a lack of statistical power.
Given the potentially important clinical implications, further studies are warranted to establish the effects of ARHL and HA use on the perception of emotions carried by speech signals. In the present study, the unaided and aided ability to identify emotions portrayed over a longer segment of continuous speech was evaluated in a larger group of OHI listeners. The choice of a multi-sentence passage was motivated by the assumption that it is more representative of everyday speech communication and affords repeated sampling of (potentially more diverse) acoustic cues associated with a given emotion, thus resulting in more robust and better emotion perception in OHI listeners than with shorter linguistic material (such as sentences). All OHI listeners were experienced HA users and were tested with their own HAs to ensure that perceptual acclimatization to HA processing had already occurred.27 To mimic everyday listening preferences and behavior of HA users in terms of volume control,28,29 listeners were allowed to adjust the presentation level of the stimuli to a comfortable listening level.
Materials and Methods
Listeners
Twenty-nine (13 females, 16 males) older (age range: 58–86 years, mean: 71.7, standard deviation, SD: 8.7) native-French-speaking adults with bilateral sensorineural hearing loss, recruited from the patient pools of several HA dispensing centers located in the South-West of France, took part in the study. All had been fitted in both ears for at least 6 months prior to the study (the average duration was 6 years) with middle- or top-of-the-range behind-the-ear HAs from a variety of manufacturers: Siemens (N=11), Beltone (N=6), Widex (N=5), Phonak (N=4), Rexton (N=2), and Oticon (N=1).
Audiometric thresholds were measured with an Otometrics Aurical Aud audiometer (Natus Medical Denmark ApS, Taastrup, Denmark) and Telephonics TDH-39 headphones (Telephonics, Farmingdale, USA). Full audiograms for the ear with the better pure-tone average between 0.5 and 4 kHz (PTA) are shown for each of the OHI listeners in Figure 1. Despite some variability in the shape of the individual audiograms, on average, audiometric thresholds declined monotonically with increasing frequency, as typically found in ARHL. Better-ear PTAs ranged from 25 to 64 dB HL, corresponding to mild to moderately severe hearing impairment.30
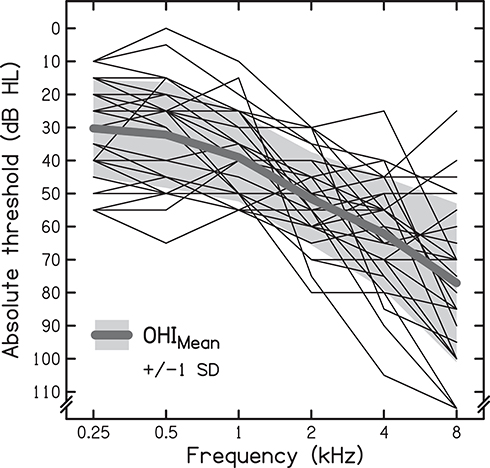 |
Figure 1 Individual (thin lines) and mean (thick line) audiograms for the better ear of the 29 older-adult hearing-impaired (OHI) listeners. The grey-shaded area represents ±1 standard deviation (SD). |
Seventeen (7 females, 10 males) younger (age range: 21–31 years, mean: 23.6, SD: 3.1) native-French-speaking adult listeners with audiometrically normal hearing sensitivity (ie, ≤ 20 dB HL at all audiometric frequencies between 0.25 and 8 kHz) were also tested as controls.
The study complied with the Declaration of Helsinki and was approved by the Toulouse University Hospital review board (CER-072012), and listeners provided informed written consent prior to study participation.
Stimuli
The linguistic material was created from the transcript of an explanation given by a French glaciologist during a radio interview on the topic of climate. The selected 20-sentence passage mainly used narrative and informative discourse modes and the lexicon was characterized by a neutral polarity.
A male native-French-speaking professional actor read the transcript out loud several times, portraying each time one of the five possible emotional states (ie, “happiness”, “pleasant surprise”, “sadness”, “anger”, “fear”), as well as a neutral emotion. Recordings, using a 44.1-kHz sampling rate and 16-bit quantization, were made in a professional sound recording studio with a Schoeps MK5 omnidirectional microphone (Schoeps GmbH, Karlsruhe, Germany), situated at 1 m from the actor, and a Fostex FR-2 digital recorder (Foster Electric Company, Tokyo, Japan). Depending on the emotional state enacted, the duration of the recording varied from 84 to 167 s (mean: 118, SD: 31).
Procedure
Testing was performed in the audiometric booths of the HA dispensing centers from which the listeners were recruited. The booths complied with the French public health code,31 requiring the ambient noise level (measured over a 1-h period) not to exceed 40 dB(A) and the reverberation time for a 0.5-kHz tone to be shorter than 500 ms.
Listeners were seated in front of a Yamaha MSP5 amplified speaker (Yamaha Corporation, Hamamatsu, Japan), placed at 0° azimuth and at the same height as the listener’s head. The distance between the loudspeaker and the center of the listener’s head was 0.5 m.
A DELL Inspiron 5570 laptop (DELL Inc., Round Rock, USA) was used to display a graphical user interface (GUI) and to present the auditory stimuli. The GUI consisted of six virtual boxes, each showing the orthographical label corresponding to one of the five emotional states and the neutral voice. For each listening condition, each of the six versions of the passage was displayed as an unlabeled file icon on the GUI. Two additional file icons, each corresponding to a copy of one of the six audio files representing the emotions selected at random, were also presented on the GUI. The duplicates were used to prevent listeners from associating the last file icon still to be classified with the last unused emotion label. The listeners could listen to each file (by double-clicking on it with the computer mouse) as many times as desired before providing a response by dragging the file icon onto one of the virtual boxes.
Prior to testing in each condition, listeners were asked to adjust the presentation level of a short excerpt from the recording using a neutral voice until it was judged comfortable.
All listeners completed the task unaided. The OHI listeners also completed the task when wearing their own bilateral HAs; the order of the listening conditions (unaided and aided) was randomized. No feedback was provided. The completion of the task in each listening condition took approximately 15 min.
Scoring and Statistical Analyses
Due to the use of stimulus duplicates in the emotion-identification task, responses for emotions presented more than once in each listening condition were averaged prior to statistical analysis. All variables were normally distributed (according to Kolmogorov–Smirnov tests), except for the overall emotion identification by YNH listeners and the identification of individual emotions by OHI listeners in both listening conditions. Hence, the difference between age groups and the difference between listening conditions for individual emotions were assessed using the appropriate nonparametric two-tailed tests. The within-subject effect of HA use in the OHI group was assessed using a two-tailed t-test. Bivariate and partial Pearson’s correlation coefficients, followed by multiple linear regressions, were computed to analyze the association between emotion perception and several listener-related factors. For all tests, the criterion used for statistical significance was P<0.05. Statistical analysis was performed using SPSS software (version 24; IBM Corporation, Armonk, NY, USA).
Results
The average self-adjusted presentation level was 58.6 dB SPL (range: 54–63, SD: 2.9) for the YHN listeners, and 65.7 dB SPL (range: 58–74, SD: 3.9) and 61.4 dB SPL (range: 56–66, SD: 2.5) for the OHI listeners in the aided and unaided listening condition, respectively. For the OHI listeners, the PTA correlated significantly with the self-adjusted presentation level in the unaided listening condition (r=0.76; P<0.001) but not in the aided listening condition (r=0.31; P=0.101).
Figure 2 shows the percentage of listeners who correctly identified each of the six emotions for the YNH listeners and the OHI listeners in the two listening conditions.
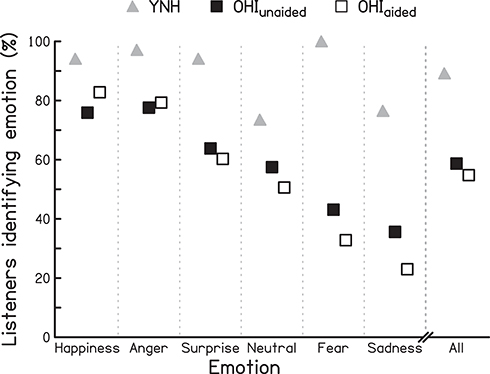 |
Figure 2 Percentage of listeners correctly identifying each of the six emotional states, and percentage of correct identification across all emotional states (All) for the YNH listeners, and the OHI listeners when unaided (OHIunaided) and when aided through their own bilateral HAs (OHIaided). The emotional states are presented, from left to right, in order of the size of the impact of the HAs on emotion perception in the OHI listeners. |
Emotion Identification by Unaided YNH and OHI Listeners
Most YNH listeners were able to correctly identify verbally transmitted emotions (89.2%), even though ~25% failed to recognize the neutral voice and sadness. In contrast, only just over half of the unaided OHI listeners (58.7%) correctly recognized vocal emotions, struggling particularly with sadness and fear which were identified correctly by less than 45% of the OHI listeners. According to a Mann–Whitney test, the observed group difference was significant (U=48.5; P<0.001).
Emotion Identification by OHI Listeners without and with Their Hearing Aids
The proportion of OHI listeners who were able to recognize verbal emotions when wearing their HAs (54.8%) was marginally lower than the proportion of unaided OHI listeners correctly identifying emotions (58.7%). However, the difference between the two listening conditions was not significant (t[28]=1.083, P=0.288). Analyzing the identification of individual emotions, both small increases and small decreases were observed in the aided listening condition: happiness and anger were identified by more OHI listeners (an increase of 6.9 and 1.7 percentage points, respectively), while fewer recognized the pleasant surprise, neutral emotion, fear, and sadness (a decrease by 3.5, 6.9, 10.3, and 12.6 percentage points, respectively). According to Wilcoxon signed-rank tests, none of these changes in emotion identification was significant (all P≥0.237).
As the duration of the speech passage varied for the different emotions, Pearson correlation coefficients were computed to test for an association between passage length and the proportion of OHI listeners correctly identifying the verbal emotion. No significant correlation was found in either of the two listening conditions (both P≥0.587).
Contribution of Listener-Related Factors to Emotion Identification in OHI Listeners
The relationship between overall emotion identification and each of the individual factors of the OHI listeners of age, PTA, and self-adjusted presentation level was assessed using bivariate Pearson correlations, followed by partial correlations controlling for the effect of the other two factors (eg, PTA and presentation level when studying the association between emotion identification and age). The results for both listening conditions are shown in Table 1.
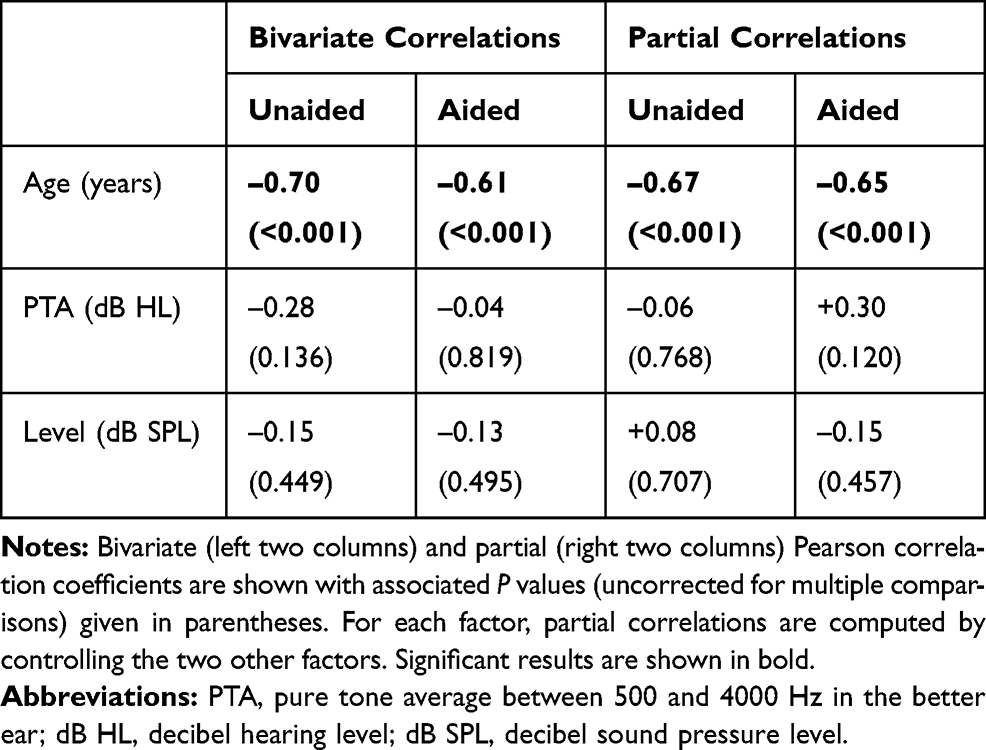 |
Table 1 Correlations Between Each of the Listener-Related Factors of Age, PTA, and Self-Adjusted Presentation Level and Verbal-Emotion-Perception Performance in the Unaided and Aided Listening Conditions |
The strongest and only significant correlation was that between emotion perception and age. With increasing age, the ability to identify verbal emotions in OHI listeners diminished both in the unaided (r = –0.70; P<0.001) and the aided condition (r = –0.61; P<0.001). This moderately strong association changed only marginally and remained highly significant when the potentially confounding factors (PTA and presentation level) were partialled out. Somewhat surprisingly, hearing loss as measured by the PTA did not correlate with emotion identification even in the unaided condition.
To explore further the relative contribution of these factors to the variance in emotion identification and to determine their combined explanatory power, multiple regression analyses were carried out separately for the two listening conditions, using age, PTA, and presentation level as possible predictor variables.
When entering all three predictor variables, the model was significant (both P≤0.002) and explained 49% and 44% of the variance in emotion identification in the unaided and aided listening condition, respectively. In both cases, age was the only significant contributor (unaided: standardized β = –0.695, t = –4.463, P<0.001; aided: standardized β = –0.705, t = –4.303, P<0.001). Tests to verify that the data met the assumption of collinearity indicated that multicollinearity was not a concern when predicting emotion identification performance in the unaided condition (Age: Tolerance = 0.84, variance inflation factor, VIF = 1.2; PTA: Tolerance = 0.38, VIF = 2.6; Presentation level: Tolerance = 0.43, VIF = 2.3) and in the aided condition (Age: Tolerance = 0.84, VIF = 1.2; PTA: Tolerance = 0.77, VIF = 1.3; Presentation level: Tolerance = 0.90, VIF = 1.1).
Discussion
In line with substantial evidence from previous studies using convenience or clinical samples of older listeners with varying degrees of ARHL (either reported by the authors or assumed based on the age of the listeners),6–8,12,32–34 our results showed that, compared to YNH controls, unaided OHI listeners have a lower ability to identify emotional states of a speaker based the on the acoustic information contained in speech. This group difference was observed even though a longer speech passage was used, and the presentation level was higher (on average by 7 dB) for the OHI group.
In contrast to previous findings,10,32 PTA was not significantly related to the recognition of verbal expressions of emotions, and this, despite the relatively wide range of hearing impairments (varying from mild to moderately severe) included in the study. This observation did not change when focusing on hearing sensitivity in the low-frequency (ie, 250–1000 Hz) range (all P≥0.246), as was done in some earlier work.32
Most importantly, our study failed to find evidence that, compared to unaided listening, the use of HAs by the OHI listeners improves the perception of voice emotions contained in speech and restores young-adult-like verbal emotion identification.11,25,35,36
In both (ie, unaided and aided) listening conditions, age, but not audibility-related factors (ie, PTA and presentation level), was related to emotion perception in our OHI listeners aged 58 to 85 years. This confirms previously reported age effects observed across the wider adult lifespan, including young adults (eg, Christensen et al tested listeners as young as 22 years and as old as 74 years),11 and suggests that verbal-emotion identification continues to decrease from young-old to old-old adulthood, as part of an aging process unrelated to ARHL.
The study used a single long test item (ie, the same multi-sentence passage spoken by the same talker) to assess verbal-emotion identification. This contrasts with previous investigations using many shorter test items (eg, words or sentences), sometimes uttered by different speakers (varying in gender and age).11,26 While our approach is prone to biases linked to the choice of the speech token and the talker, it is compatible with the time constraints of a clinical assessment, and mimics the brevity of other tests of emotion perception (eg, the Emotional Perception Test37).
Several hypotheses – some related to the device itself or its interaction with the listener, others related to the nature of the underlying deficit – can be advanced to explain why HA use did not affect emotion perception.
The most obvious HA-related hypothesis is probably that HA amplification was insufficient or inappropriate in the present study. Indeed, the actual gain delivered by the HAs was not verified at the time of testing (eg, by measuring real-ear insertion gains). However, all HAs had been professionally fitted by the listeners’ HA audiologists according to established gain prescription rules (eg, DSL,38 NAL-NL239). Hence, gross misfitting or malfunctioning of the HAs is unlikely. However, it cannot be excluded that there was a mismatch between prescribed target gains and actual gains as implemented in the HAs. Indeed, HA audiologists modify the prescribed HA gains to accommodate the HA user’s listening preferences.25,40 Hence, underfitting of the HAs is a common phenomenon, lending some ecological validity to the current experimental design.41
Another possible limitation of the present study, which is also a strength, is the inclusion of a range of HAs using the listeners’ personal settings. Opting against the use of the same research HA for all OHI listeners most likely introduced additional variability in the results due to non-identical signal processing implemented in the different HAs. On the other hand, this choice ensured a high degree of perceptual acclimatization to speech processed through the HAs. Importantly, it also meant that the study findings can be generalized to a larger, more heterogenous population of HA users.11 Nevertheless, it would be of interest to study in future investigations which specific HA signal-processing schemes improve or hinder verbal emotion identification.
It is also conceivable that allowing listeners to adjust the presentation level (resulting, on average, in a lower presentation level in the aided than in the unaided listening condition) reduced any potential benefit of the HAs. Against this explanation argues the finding reported by Goy et al that, even when the presentation level was kept the same in the unaided and aided listening condition, no HA benefits were observed.25 Furthermore, a reanalysis of our results, limited to the eight OHI listeners who chose the same presentation level in the unaided and aided listening condition, revealed that only one of them identified more verbal emotions with HAs than without them; six of them showed a reduction in the ability to identify emotions.
Lastly, the lack of improvement in emotion perception might be explained by the deleterious effect of signal distortions produced by HA processing (eg, dynamic range compression), off-setting benefits due to increased audibility.42 This hypothesis could be tested in future studies by comparing the effect of amplification with dynamic range compression to that of linear amplification, which does not distort the temporal envelope of acoustic signals.
Alternatively, the inefficacy of HAs in terms of restoring identification of verbally expressed emotions might have little to do with the devices themselves, if impairment observed in OHI listeners were not (or only to a limited degree) due to ARHL. Other audibility-unrelated factors associated with the aging process, such as changes in cognitive functioning12 (that have already been shown to be associated with speech-identification difficulties),43–45 and in the neural circuitry involved in emotion processing,5,8,46 might affect the ability to recognize emotions. Our observation of a moderately strong negative correlation between age and emotion identification in the OHI group for unaided and aided listening even when controlling for PTA and presentation level is consistent with this hypothesis. However, studies of verbal-emotion perception in OHI listeners, in which cognitive functioning was also assessed, generally failed to find evidence in favor of the existence of a (strong) link between emotion perception and different cognitive abilities, such as working memory, verbal intelligence, and sustained attention.7,8,25,47 The reduction in verbal-emotion identification also does not seem to be due to difficulties with the identification task per se (requiring cognitive processes for the labelling of emotions), as the discrimination of verbal emotions is also affected in this population.48
As a final explanation, age-related changes in suprathreshold auditory processing abilities (such as changes in the sensitivity to temporal-envelope and temporal-fine-structure information) that occur in association with49,50 or independently of audiometric loss44,51 might also affect the perception of emotions carried in speech. These processing abilities are generally not assessed in investigations of verbal-emotion perception. Consequently, it is difficult to establish an association, let alone a causal relationship, between the sensory and emotional processing abilities. It is noteworthy that some of the suprathreshold auditory processing abilities deteriorate progressively from early mid-life onwards,51–53 and continue to do so throughout old age,54,55 thus matching the adult-lifespan trajectory for verbal-emotion perception.6,33 Crucially, apart from restoring audibility, current HAs provide only limited compensation of the age-related changes in suprathreshold auditory processing (eg, by mimicking the compressive input-output function of the healthy inner ear), leaving many of the listeners perceptual problems unmitigated (eg, loss of frequency resolution, reduction in temporal-fine-structure sensitivity).
Conclusion
The reported results corroborate the existence of age differences in emotion processing across adulthood. Compared to young adults with normal hearing, older listeners with age-typical hearing losses showed a reduced ability to identify verbal emotions. This deficit was not linked to the listeners’ hearing sensitivity as measured by the audiogram. In addition, the use of HAs, the standard clinical intervention for ARHL, did not compensate for the dysfunction in verbal-emotion processing.
Acknowledgments
The authors thank Mr. Olivier Jeannelle and Mr. Paul Lacoste for their help with recording the stimuli, the Head of the École d’Audioprothèse de Cahors Prof. Mathieu Marx for his continuing support throughout the project, and Dr. Saïd Jmel for his help with statistical analyses. The authors are also indebted to Dr. Tom Baer for helpful comments on an earlier draft of this manuscript.
Disclosure
The authors report no conflicts of interest in this work.
References
1. Darwin CJ. The Expression of the Emotions in Man and Animals. London, UK: John Murray; 1872.
2. Murray IR, Arnott JL. Toward the simulation of emotion in synthetic speech: a review of the literature on human vocal emotion. J Acoust Soc Am. 1993;93(2):1097–1108. doi:10.1121/1.405558
3. Scherer KR. Vocal communication of emotion: a review of research paradigms. Speech Comm. 2003;40(1–2):227–256. doi:10.1016/S0167-6393(02)00084-5
4. Majid A. Current emotion research in the language sciences. Emot Rev. 2012;4(4):432–443. doi:10.1177/1754073912445827
5. Ruffman T, Henry JD, Livingstone V, Phillips LH. A meta-analytic review of emotion recognition and aging: implications for neuropsychological models of aging. Neurosci Biobehav Rev. 2008;32(4):863–881. doi:10.1016/j.neubiorev.2008.01.001
6. Mill A, Allik J, Realo A, Valk R. Age-related differences in emotion recognition ability: a cross-sectional study. Emotion. 2009;9(5):619. doi:10.1037/a0016562
7. Mitchell RL. Age-related decline in the ability to decode emotional prosody: primary or secondary phenomenon? Cogn Emot. 2007;21(7):1435–1454. doi:10.1080/02699930601133994
8. Orbelo DM, Grim MA, Talbott RE, Ross ED. Impaired comprehension of affective prosody in elderly subjects is not predicted by age-related hearing loss or age-related cognitive decline. J Geriatr Psychiatry Neurol. 2005;18(1):25–32. doi:10.1177/0891988704272214
9. Demenescu LR, Kato Y, Mathiak K. Neural processing of emotional prosody across the adult lifespan. Biomed Res Int. 2015;2015:590216. doi:10.1155/2015/590216
10. Singh G, Liskovoi L, Launer S, Russo F. The emotional communication in hearing questionnaire (EMO-CHeQ): development and evaluation. Ear Hear. 2019;40(2):260. doi:10.1097/AUD.0000000000000611
11. Christensen JA, Sis J, Kulkarni AM, Chatterjee M. Effects of age and hearing loss on the recognition of emotions in speech. Ear Hear. 2019;40(5):1069–1083. doi:10.1097/AUD.0000000000000694
12. Sen A, Isaacowitz D, Schirmer A. Age differences in vocal emotion perception: on the role of speaker age and listener sex. Cogn Emot. 2018;32(6):1189–1204. doi:10.1080/02699931.2017.1393399
13. Carton JS, Kessler EA, Pape CL. Nonverbal decoding skills and relationship well-being in adults. J Nonverbal Behav. 1999;23(1):91–100. doi:10.1023/A:1021339410262
14. Nordvik Ø, Heggdal POL, Brännström J, Vassbotn F, Aarstad AK, Aarstad HJ. Generic quality of life in persons with hearing loss: a systematic literature review. BMC Ear Nose Throat Dis. 2018;18(1):1–13. doi:10.1186/s12901-018-0051-6
15. Bunch CC. Age variations in auditory acuity. Arch Otolaryngol. 1929;9(6):625–636. doi:10.1001/archotol.1929.00620030657005
16. Cruickshanks KJ, Wiley TL, Tweed TS, et al. Prevalence of hearing loss in older adults in Beaver Dam, Wisconsin. The epidemiology of hearing loss study. Am J Epidemiol. 1998;148(9):879–886. doi:10.1093/oxfordjournals.aje.a009713
17. World Health Organization. Deafness and hearing loss; 2019. Available from: https://www.who.int/news-room/fact-sheets/detail/deafness-and-hearing-loss.
18. Cox RM, Alexander GC. Hearing aid benefit in everyday environments. Ear Hear. 1991;12(2):127–139. doi:10.1097/00003446-199104000-00009
19. Mok M, Holt CM, Lee K, Dowell RC, Vogel AP. Cantonese tone perception for children who use a hearing aid and a cochlear implant in opposite ears. Ear Hear. 2017;38(6). doi:10.1097/AUD.0000000000000453.
20. Füllgrabe C, Stone MA, Moore BCJ. Contribution of very low amplitude-modulation rates to intelligibility in a competing-speech task. J Acoust Soc Am. 2009;125:1277–1280. doi:10.1121/1.3075591
21. Stone MA, Moore BCJ, Füllgrabe C, Hinton AC. Multi-channel fast-acting dynamic-range compression hinders performance by young, normal-hearing listeners in a two-talker separation task. J Audio Eng Soc. 2009;57:532–546.
22. Picou EM, Singh G, Goy H, et al. Hearing, emotion, amplification, research, and training workshop: current understanding of hearing loss and emotion perception and priorities for future research. Trends Hear. 2018;22:2331216518803215.
23. Schmidt J, Herzog D, Scharenborg O, Janse E. Do hearing aids improve affect perception? Adv Exp Med Biol. 2016;894:47–55.
24. Picou EM. Acoustic factors related to emotional responses to sound. Can Acoust. 2016;44:126–127.
25. Goy H, Pichora-Fuller MK, Singh G, Russo FA. Hearing aids benefit recognition of words in emotional speech but not emotion identification. Trends Hear. 2018;22:2331216518801736.
26. Dupuis K, Pichora-Fuller MK. Recognition of emotional speech for younger and older talkers: behavioural findings from the Toronto emotional speech set. Can Acoust. 2011;39(3):182–183.
27. Gatehouse S. The time course and magnitude of perceptual acclimatization to frequency responses: evidence from monaural fitting of hearing aids. J Acoust Soc Am. 1992;92(3):1258–1268. doi:10.1121/1.403921
28. Surr RK, Cord MT, Walden BE. Response of hearing aid wearers to the absence of a user-operated volume control. Hear J. 2001;54(4):32–34. doi:10.1097/01.HJ.0000294514.53700.b0
29. Perry TT, Nelson PB, Van Tasell DJ. Listener factors explain little variability in self-adjusted hearing aid gain. Trends Hear. 2019;23:2331216519837124.
30. Stevens G, Flaxman S, Brunskill E, Mascarenhas M, Mathers CD, Finucane M. Global and regional hearing impairment prevalence: an analysis of 42 studies in 29 countries. Eur J Public Health. 2013;23(1):146–152. doi:10.1093/eurpub/ckr176
31. République Française. Code de la santé publique. Audioprothésiste — local réservé à l’activité professionnelle. [Public Health Code. Hearing-aid dispenser — Professional premises]. 2017.
32. Rigo TG, Lieberman DA. Nonverbal sensitivity of normal-hearing and hearing-impaired older adults. Ear Hear. 1989;10(3):184–189. doi:10.1097/00003446-198906000-00008
33. Brosgole L, Weisman J. Mood recognition across the ages. Int J Neurosci. 1995;82(3–4):169–189. doi:10.3109/00207459508999800
34. Kiss I, Ennis T. Age-related decline in perception of prosodic affect. Appl Neuropsychol. 2001;8(4):251–254. doi:10.1207/S15324826AN0804_9
35. Waaramaa T, Kukkonen T, Stoltz M, Geneid A. Hearing impairment and emotion identification from auditory and visual stimuli. Int J List. 2018;32(3):150–162. doi:10.1080/10904018.2016.1250633
36. Öster A, Risberg A. The identification of the mood of a speaker by hearing impaired listeners. SLT. 1986;4:79–90.
37. Green PW, Allen LM. The Emotional Perception Test. Durham, NC: CogniSyst Inc; 1997.
38. Scollie S, Seewald R, Cornelisse L, et al. The desired sensation level multistage input/output algorithm. Trends Amplif. 2005;9(4):159–197. doi:10.1177/108471380500900403
39. Keidser G, Dillon H, Flax M, Ching T, Brewer S. The NAL-NL2 prescription procedure. Audio Res. 2011;e24(1):88–90.
40. Wong LL. Evidence on self-fitting hearing aids. Trends Amplif. 2011;15(4):215–225. doi:10.1177/1084713812444009
41. Polonenko MJ, Scollie SD, Moodie S, et al. Fit to targets, preferred listening levels, and self-reported outcomes for the DSL v5.0a hearing aid prescription for adults. Int J Audiol. 2010;49(8):550–560. doi:10.3109/14992021003713122
42. Arefi HN, Sameni SJ, Jalilvand H, Kamali M. Effect of hearing aid amplitude compression on emotional speech recognition. Aud Vest Res. 2017;26(4):223–230.
43. Sommers MS. Speech perception in older adults: the importance of speech-specific cognitive abilities. J Am Geriatr Soc. 1997;45(5):633–637. doi:10.1111/j.1532-5415.1997.tb03101.x
44. Füllgrabe C, Moore BCJ, Stone MA. Age-group differences in speech identification despite matched audiometrically normal hearing: contributions from auditory temporal processing and cognition. Front Aging Neurosci. 2015;6:347. doi:10.3389/fnagi.2014.00347
45. Füllgrabe C, Rosen S. Investigating the role of working memory in speech-in-noise identification for listeners with normal hearing. Adv Exp Med Biol. 2016;894:29–36. doi:10.1007/978-3-319-25474-6_4
46. Salat DH, Buckner RL, Snyder AZ, et al. Thinning of the cerebral cortex in aging. Cereb Cortex. 2004;14(7):721–730. doi:10.1093/cercor/bhh032
47. Lambrecht L, Kreifelts B, Wildgruber D. Age-related decrease in recognition of emotional facial and prosodic expressions. Emotion. 2012;12(3):529. doi:10.1037/a0026827
48. Mitchell RL, Kingston RA. Is age-related decline in vocal emotion identification an artefact of labelling cognitions? Int J Psychol Stud. 2011;3(2):156. doi:10.5539/ijps.v3n2p156
49. Füllgrabe C, Meyer B, Lorenzi C. Effect of cochlear damage on the detection of complex temporal envelopes. Hear Res. 2003;178(1–2):35–43. doi:10.1016/S0378-5955(03)00027-3
50. Füllgrabe C, Moore BCJ. Evaluation of a method for determining binaural sensitivity to temporal fine structure (TFS-AF test) for older listeners with normal and impaired low-frequency hearing. Trends Hear. 2017;21. doi:10.1177/2331216517737230
51. Füllgrabe C. Age-dependent changes in temporal-fine-structure processing in the absence of peripheral hearing loss. Am J Audiol. 2013;22(2):313–315. doi:10.1044/1059-0889(2013/12-0070)
52. Grose JH, Mamo SK. Processing of temporal fine structure as a function of age. Ear Hear. 2010;31(6):755–760. doi:10.1097/AUD.0b013e3181e627e7
53. Humes LE, Kewley-Port D, Fogerty D, Kinney D. Measures of hearing threshold and temporal processing across the adult lifespan. Hear Res. 2010;264(1–2):30–40. doi:10.1016/j.heares.2009.09.010
54. Füllgrabe C, Moore BCJ. The association between the processing of binaural temporal-fine-structure information and audiometric threshold and age: a meta-analysis. Trends Hear. 2018;22. doi:10.1177/2331216518797259
55. Füllgrabe C, Sęk AP, Moore BCJ. Senescent changes in sensitivity to binaural temporal fine structure. Trends Hear. 2018;22. doi:10.1177/2331216518788224
 © 2020 The Author(s). This work is published and licensed by Dove Medical Press Limited. The
full terms of this license are available at https://www.dovepress.com/terms
and incorporate the Creative Commons Attribution
- Non Commercial (unported, 3.0) License.
By accessing the work you hereby accept the Terms. Non-commercial uses of the work are permitted
without any further permission from Dove Medical Press Limited, provided the work is properly
attributed. For permission for commercial use of this work, please see paragraphs 4.2 and 5 of our Terms.
© 2020 The Author(s). This work is published and licensed by Dove Medical Press Limited. The
full terms of this license are available at https://www.dovepress.com/terms
and incorporate the Creative Commons Attribution
- Non Commercial (unported, 3.0) License.
By accessing the work you hereby accept the Terms. Non-commercial uses of the work are permitted
without any further permission from Dove Medical Press Limited, provided the work is properly
attributed. For permission for commercial use of this work, please see paragraphs 4.2 and 5 of our Terms.