Back to Journals » Drug Design, Development and Therapy » Volume 13
Attractor – a new turning point in drug discovery
Authors Hou X ![]() , Li M, Jia C, Zhang X, Wang Y
, Li M, Jia C, Zhang X, Wang Y ![]()
Received 23 May 2019
Accepted for publication 28 July 2019
Published 22 August 2019 Volume 2019:13 Pages 2957—2968
DOI https://doi.org/10.2147/DDDT.S216397
Checked for plagiarism Yes
Review by Single anonymous peer review
Peer reviewer comments 2
Editor who approved publication: Professor Jianbo Sun
Xucan Hou, Meng Li, Congmin Jia, Xianbao Zhang, Yun Wang
Department of Traditional Chinese Medicine Information Fusion and Utilization, Beijing University of Chinese Medicine, Beijing, People’s Republic of China
Correspondence: Yun Wang
Department of Traditional Chinese Medicine Information Fusion and Utilization, Beijing University of Chinese Medicine, Beijing 102488, People’s Republic of China
Tel +86 1 369 305 8206
Fax +86 108 473 8620
Email [email protected]
Abstract: Drug discovery for complex diseases can be viewed as a challenging problem in which the influence of compounds on dynamic features of disease system should be considered, especially the strategies escaping from the disease attractors. Moreover, escaping from the disease-related attractors has been proved to be a cue for the treatment of the complex diseases. The drug discovery methodology based on the attractor theory indicates new solutions for target identification, drug discovery and drug combination design. The methodology is based on the holism level of the organism and the features of system dynamics, so it has advantages for the classification of complex diseases and drug discovery. Currently, research results of this method have increased, which expand the insight scope for drug discovery. This article introduces the major drug discovery methods in the history of pharmacy development and their characteristics, so as to illustrate the reasons and inevitability of the appearance of attractor method, its position in the history of pharmacy development, and its advantages for drug discovery and design, thereby to prove that the attractor method can indeed become the next major drug development method. In addition, it provides a comprehensive description about the concept of attractor, the pipeline of attractor analysis, the common methods of each process and its research progress, so as to provide a macroscopic framework and optional methods and tools for the follow-up researchers.
Keywords: drug discovery, design, attractor, system dynamics, attractor calculation, state transition
Introduction
The concept of attractor
The concept of attractor stems from calculus and systems science theory. Attractor refers to a steady state in the system, and all the imbalance state around it eventually evolves into an attractor state when the system dynamically evolves over time (Figure 1).
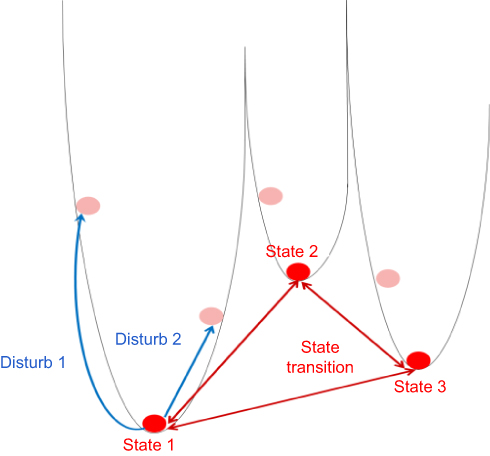 |
Figure 1 Schematic diagram of the conception of attractor. Balls in the figure, respectively, indicate one of the system states, the red balls are in stable states while the pink balls are in unstable states. The figure lists three stable states in a system and uses red double arrows to represent the dynamic process of state transitions between them. The blue arrows indicate that two different disturbances cause two type changes in system state, respectively. Both of the two disturbances make the system from a stable state into an unstable state, but it is temporary, because the system will return to the state 1 after a period of evolution. These changes could be used to indicate that the human body would be temporarily out of the disease attractor state after drug treatment (disturb 1 or disturb 2), but the designed drugs cannot completely cure disease, and after a period of time, the human body will come back to the disease attractor state again, which would cause the recurrence of disease. The other two stable states (state 2 and state 3) can represent the different phases of the disease, such as mild and moderate phases, so state 1 can represent the severe phases. |
Backgrounds and research status
Nowadays, many complex diseases have emerged, which usually involve the interaction between multigene genetics and environmental factors; besides, since the biological system state changes dynamically at all times to maintain the relative equilibrium of organisms and have robustness for a certain range of external disturbance, the drugs developed by existing methods cannot fully overcome complex diseases. In order to find a new way of drug discovery and design from the overall level of organism and the angle of system dynamics, some researchers have introduced the concept of attractor into biomedicine. Follow-up researchers found its prospect and expected great impacts on the development of pharmacy, and they started to work on the study of it in recent years, and obtained the corresponding results.
There have been some paradigms of biomedical research related to attractor. 1) The biological significance represented by attractor: Kauffman has put forward that the attractor in the Boolean network could reflect the types of cells; in other words, the types of cells can be determined by the gene expression pattern. Kauffman and Li et al believed that attractor was a stable state cycle, thereby it had strong biological significance and were usually associated with phenotype.1,2 Huang et al also argued that the state of attractor could correspond to the states of cells, and the attractor represented a stable cell phenotype.3 2) Researches on disease treatment by using attractor theory: Cho et al4 have constructed the Boolean model of human signal network by integrating the typical signaling pathway of cellular process and carried on the analysis of attractor landscape, performing the analysis of attractor landscape. Based on this, the idea of restoring normal cell phenotype by reverse-controlling attractor landscape was proposed. Finally, a genetic algorithm has been used to identify the minimum set of control nodes in order to achieve cell phenotype reversal. The results showed that colorectal cancer was driven by four mutations accumulated sequentially, and the minimum set of control nodes to change the phenotype of cancer was determined. Since it is critical for the changes of cell fate to determine a control strategy of biological networks, such as disease treatment and stem cell reprogramming, Zañudo et al5 developed a network control framework, which used the logical dynamic scheme to predict the control targets and drive any initial state to the attractor state or other desired state with 100% validity. This study provided a new insight into the control strategy based on network dynamics and attractor theory. In addition, taking cancer as an example, some researchers believed that cancer cells entered a high-dimensional attractor state;6,7 if the disturbances are not strong enough, it is hard to return to the normal state. So once normal cells entered the cancer attractor because of certain genetic mutations or long-term abnormal signals, it was difficult to escape from the cancer attractor. Currently, most cancer patients relied on drugs to maintain the temporary balance of body, but cancer cells would continue to develop resistance, and the mutation of cancer cells will make many drugs off-target, thereby causing the body to return to the cancer attractor state, and ultimately manifests as the recurrence of cancer.
There were many paradigms on attractor over the past more than 10 years (following sections of the article also deal with), although only have a few of them been selected for a brief overview now, they show the great potential of attractor theory for the treatment of complex diseases. We look forward to using the concept and method of attractor to provide a new idea for drug discovery and design, and becoming a turning point in the history of pharmacy development. In this review, we will give a comprehensive description about the position of attractor method, the concept of attractor, the whole workflow, the common methods of each process and its research progress, so as to provide a macroscopic framework for the follow-up researchers.
The position of attractor method in the history of drug discovery and design
Drug discovery methods at four phases
The author believes that the emergence of new type diseases has led to the development of new drugs that aim for these diseases, and it is also a way to promote the development of pharmacy., Among them, the continuous updating of drug discovery methods directly promotes the batch discovery of new drugs. Before the approximately 21st century, the history of drug development can be broadly divided into four phases (Figure 2).
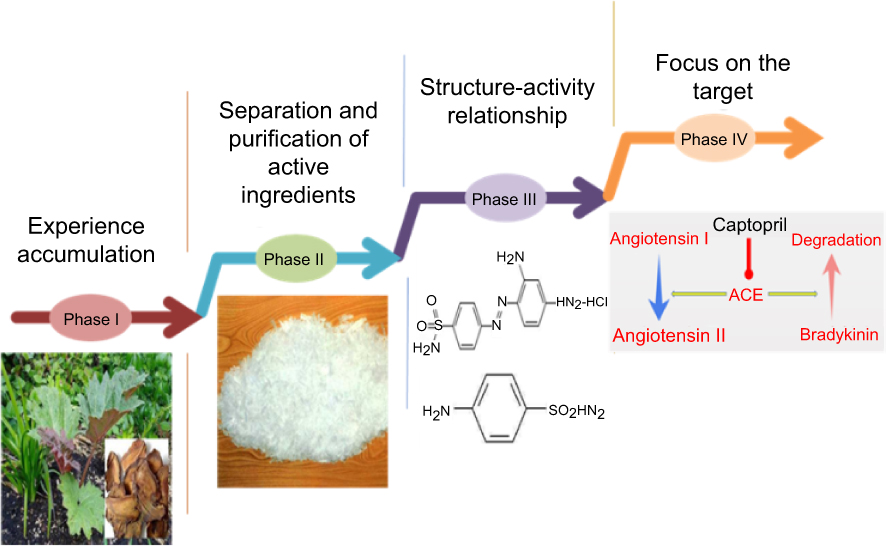 |
Figure 2 Methods of drug discovery at all the phases. Phase I: Experience accumulation. The picture is a rhubarb plant and its slices; according to experience, the ancients learned that rhubarb can treat diseases. Phase II: Separation and purification of active ingredients. The picture is the morphine crystallization; the purification of morphine is a milestone in modern pharmacy. Phase III: Structure–activity relationship. The upper part of the picture is the structure of prontosil, the lower part of the picture is the structural formula of the p-aminobenzene sulfonamide decomposed by prontosil in vivo, and the p-aminobenzene sulfonamide is also the effective group that produces the antibacterial effect. Phase IV: Focus on the target. The picture is a sketch of the action of captopril which is an antihypertensive drug, and captopril is the first type of ACEI (angiotensin-converting enzyme inhibitor) drug. ACE (angiotensin-converting enzyme) catalyzes the conversion of angiotensin I to angiotensin II, degrades bradykinin, and leads to vasodilation, elevated aldosterone, and elevated blood pressure. Captopril controls blood pressure by inhibiting ACE. |
Phase I: Ancient times to 19th century. Drug discovery method at this phase mainly depended on the accumulation of experience, and some natural substances that can be used to treat diseases and injuries were recognized from production and life experience, such as drinking wine to relieve pain, using the rhubarb to catharsis and treating fever with willow bark. This is the initial phase of drug discovery.
Phase II: 19th century to the 1930s. The method of drug discovery at this phase was mainly the separation and purification of plant active ingredients.8 In 1805, a German pharmacist named Serturner had extracted pure morphine crystallization from opium, which became a milestone in modern pharmacy. Since then, a large number of ingredients were extracted and separated from plants, for example, quinine extracted from the bark of the Cinchona was used around the world to treat malaria; atropine, which was isolated from the Atropa belladonna, was still used by ophthalmologists to dilate pupil. In addition, there are ephedrine, salicylic aldehyde, colchicine and so on.9
Phase III: 1930s to 1960s. The structure–activity relationship (SAR) was the main method of drug discovery at this phase. In 1932, the prontosil was synthesized when studied the antibacterial efficacy of azo dyes, and was proved that its effective ingredient was p-aminobenzene sulfonamide. For the next 5 years, based on this basic structure, a large number of low-toxicity and more effective sulfonamide drugs were synthesized. Since then, the method of drug discovery had shifted from the separation and purification of active ingredients to structural modification based on the SAR, and a large number of synthesized chemical drugs were developed. At the same time, the successful development of penicillin has set off the craze for the separation of antibiotics. These achievements have become another leap in the history of drug development, and the phase can be called the golden age of the pharmaceutical industry.
Phase IV: 1970s to approximately 21st century. This phase was mainly a target-centric approach to carry out drug discovery. In 1894, the lock and key model was proposed by Fisher,10 which was originally used to denote the binding pattern of enzyme and substrate, and extended to the field of drug discovery later. In 1948, the difference between α-and β-adrenergic receptors was made, and since then, receptor research began to provide a strong basis for pharmaceutical innovation,11,12 and people began to look forward to designing drugs that bind highly specific to key targets in the process of disease development,13 that is, identifying the ligands (the “key”) that suit for a particular receptor (the “lock”).14 Meanwhile, the completion of the Human Genome Project and the application of new technologies in pharmacology provided numerous new drug targets, and the pharmaceutical industry was also able to quickly screen compounds.15 The main feature of this phase is the principle of “one medicine, one target, one disease”.
Drug discovery methods are changing after approximately 21st century
Since the 1970s, driven by the view of reductionism,16 the “one medicine, one target, one disease” approach had accelerated the pace of drug discovery, and the pharmaceutical industry continued to grow rapidly and steadily; this method also acquired a large number of target selectivity drugs. However, due to the toxicity, inefficiency and/or clinical safety,17 many drugs could not achieve the desired clinical effect, or had serious toxic side effects, or two- and three-phase failure rate of clinical trials is high. For instance, Tolrestat (Figure 2A), which was used to control certain diabetic complications and approved for sale in some countries, was not approved by the Food and Drug Administration (FDA) due to toxicity in the Phase III clinical trials. Then, it was discontinued by Wyeth in 1997 due to the risk of severe hepatotoxicity and death. According to the Drug Bank database, more than 60 drugs have been withdrawn by 2010.18 Despite the constant emergence of new drug targets, the expected number of new drugs available to patients did not increase synchronously,17 which reflected the flaws in the concept of drug design that they followed.
The emergence of systems biology explained that, while the above method was useful for the treatment of single-gene diseases, nowadays, complex diseases are usually involving the interaction between multigene genetics and environmental factors. In addition, because of the compensation mechanism and redundancy function, biological network system had elasticity to single-node disturbance.19 However, the single-target drug discovery method only considered the biological system as a simple sum of its components.20 Therefore, drug development should be adjusted to a multitarget intervention model to cure or mitigate complex diseases, rather than inhibiting or activating a single target.21,22 As a result, some multicomponent drugs based on systems biology had been developed, such as Exforge, which was a fixed combination of Amlodipine and Valsartan. Valsartan was an angiotensin receptor blocker (ARB), while Amlodipine was a calcium channel blocker (CCB); Exforge treated hypertension by simultaneously acting on multiple targets (Figure 3B).13
On the other hand, Hopkins23 introduced the concept of network pharmacology for the first time in 2007 and elaborated on this concept in the journal of Nature Chemical Biology in 2008; he argued that network pharmacology would be the next platform for drug discovery.24 Network pharmacology believed that multitarget drug design can reduce the toxic and side effects on the body, improve the therapeutic effect of drugs, reduce the failure rate of drug clinical trials, and save the cost of drug research and development as well. In the past nearly 20 years, the study of systems biology has revealed a high degree of correlation between molecular regulatory networks and diseases7 and confirmed that in the organisms, the topology of network was closely related to the biological functions it represents.25–29
After the design of new drugs based on the single-target theory hit a plateau, the researchers shifted the goal to multicomponent drugs and network pharmacology, which advocated to design a synergistic attack at multiple nodes in the network to further improve the disturbance efficiency.7 But can this degree of disturbance be enough to reverse the state of complex diseases such as cancer? The answer was no (though some could, but rarely). The reason was the complex diseases such as cancer were a robust physiological system collapse caused by multigene genetics and environmental factors; thereby a robust disease state has been established.30 In addition, the key target recognition method based on topological structure generally employed some quantitative rules to measure the importance of nodes or edges’ positions in a network (Figure 3C). As a result, only when there was a linear causal relationship between targets and their functions of cellular level, can the disease be successfully treated through this method. However, due to the dynamic, redundant and robust characteristic of the disease network, it just is a special case, so the failure rate of drug design is higher now.7 Therefore, consistent with the previous update law of new drug discovery, a new method for drug discovery was urgently needed.
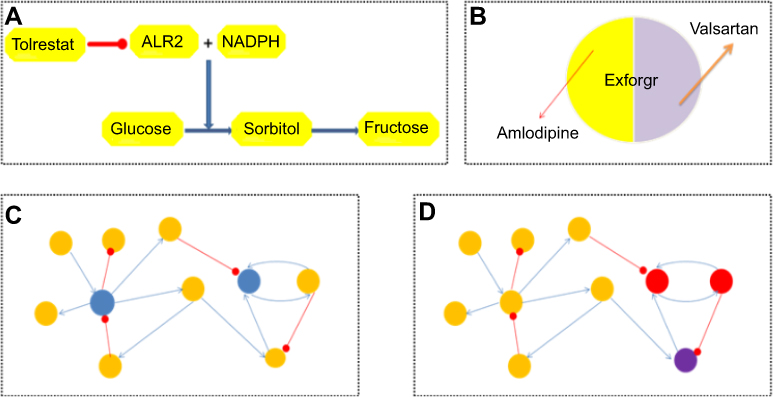 |
Figure 3 (A) The diagram of Tolrestat’s action path. ALR2 (aldose reductase 2) uses NADPH ( nicotinamide adenine dinucleotide phosphate) as a coenzyme to catalyze the reduction of glucose to sorbitol. Under the condition of hyperglycemia, the ALR2 is activated, and the sorbitol is produced in large quantities, causing the damage of cell metabolism and function, and then leads to the organ lesions such as diabetic complications. Tolrestat inhibits ALR2 (the single target) to prevent sorbitol overdose, thereby controlling diabetic complications. (B) Schematic diagram of Exforge pill. Exforge contains two drugs in one pill. Not only can Amlodipine selectively inhibit calcium ion cross-membrane into smooth muscle cells and cardiomyocytes, but also directly act on vascular smooth muscle and reduce peripheral resistance, thus lowering blood pressure. Valsartan inhibits the physiological effects caused by angiotensin II, such as elevated blood pressure and elevated aldosterone, thereby lowering blood pressure. Two drugs can treat high blood pressure in a synergistic way. (C) Schematic diagram of the GRN (gene regulation network) . The blue lines represent the promotion relationship, while the red lines represent the suppression relationship. From the perspective of network pharmacology, we get the two blue nodes above as the key targets in the network, and we will design the drugs’ combination or multicomponent drugs based on them. (D) Schematic diagram of the GRN. The meaning represented by nodes and edges is consistent with Figure 3C. From the view of network dynamic of attractor, we think that the two red nodes are the key targets (adding to the purple nodes if necessary), the drugs’ combination or multicomponent drug design based on these targets can make the system exit this attractor state. |
Attractor method – the next trend for drug discovery and design
Attractor method (Figure 3D) is a new way of drug discovery and design from the overall level of organism and the angle of system dynamics, and it could provide new solutions for target identification, drug discovery and drug combination design, especially for the conquering of complex diseases. Attractor method has a unique advantage and will become the next turning point after multicomponent drugs and network pharmacology methods. In order to clearly show the advantages of attractor method, we compared it with other methods and listed in Table 1.
 |
Table 1 Comparison of major drug discovery methods in different phases |
The pipeline of attractor analysis and the common methods of each process
Constructing the gene regulatory network
In the 1990s, some scholars began to study the network among genes.31,32 The development of DNA chip technology provided a large database of gene expression and laid a good foundation for the research of gene-gene networks.33 Until 2003, the “Human Genome Project” had been completed and the study of life sciences had entered the post-genome era, so a large number of omics data emerged, and people began to shift from static base sequencing problem to explore the nonstatic gene function annotation and the relationship between genes and diseases.34 By annotating the function of genes, we can better understand the relationship between genes and genes as well as genes and diseases, and then appropriate disturbance strategies35–38 can be designed to influence and change the system state.
The gene regulatory network (GRN) is a network that includes biological molecules involved in gene regulation in the cell, such as DNA, RNA, proteins, metabolic intermediates and their interaction relationship.34 In order to build a GRN, for the target biological system,we need to obtain these biological molecules mentioned above and the mutual regulatory relationships between them, thereby reflecting the relationship between biological molecules and biological system, and designing appropriate disturbance strategies. GRN research is a very important field of biological research in the 21st century, which is also a hot issue in the study of systems biology, and many types GRN had been constructed in the past few years. For example, Madhamshettiwar et al39 found the best methods (the monitoring method of SIRENE) to infer the GRN of normal human body and ovarian cancer patients by comparing nine of the most advanced GRN inference methods. And then, they used the Cancer Resource40 and PharmGKB41 network tools and database to predict and assess the drug ability of proteins that were encoded by target genes. Besides, the authors put forward functional models of two potential novel interactions: the signal transduction of E2F1 and DKK1 through WNT signaling pathway; E2F1 and HSD17B2 via estrogen synthesis. Not only could the potential drug targets be obtained based on the method proposed above, but the drug attrition rates were decreased before the experiment.
Based on the GRN, we were better able to understand the interaction relationship between biological molecules and diseases, and then further analysis could be implemented and new drugs and effective therapies for diseases could be designed.
Calculating attractor and calculation tools
Attractor can be calculated by the built GRN, and this article introduces the method of attractor calculation based on Boolean network. Because the Boolean model is a mature technique that can abstract the dynamical regulatory relationship between biomolecules in cells.42 Although the Boolean model is a mathematical model with low complexity, it is able to capture the basic characteristics of GRNs and has been widely used as an appropriate method to perform the system-level results of biomolecular networks.43–45 Biological molecules and the regulatory relationship between them have been obtained when building GRN. In order to construct a Boolean network, we also need to obtain the expression of these biological molecules in the target network system, such as disease system and normal system. After obtaining expression data, no expression is marked as “0”, and expression is marked as “1”, then the calculation of the attractor could be performed. The calculated attractor is a stable state that was based on the overall level and system dynamic level of the organism, so drug discovery and design based on it can theoretically reduce the off-target effect and drug attrition rates, as well as disease recurrence.
A variety of algorithms have been performed to calculate the attractor state; in this section, a brief introduction will be narrated for these common methods.
BoolNet;46 provides the methods of a Boolean network of synchronous, asynchronous, and probabilistic; it also includes the function of attractor searching, robustness analysis and binarization. BoolNet is well integrated with existing modeling tools such as Bio Tapestry47 and Pajek,48 and supports exhaustive searches for all 2n states to identify synchronous attractor (for n genes), or heuristic searches that begin with many predefined or randomly selected states; it also provides a new random walk algorithm for identifying complex asynchronous attractor. Besides, for synchronous and probabilistic networks, Markov chain simulation can be used to calculate the potential attractor state and the probability of reaching certain states.49 BoolNet can identify single attractor and small attractor rings for small-scale networks.
GINsim is a qualitative modeling method for biological regulatory networks. This method used the multilevel asynchronous logic method proposed by Thomas50 in 1991, which had been successfully applied to biological regulatory networks’ modeling in many types.51,52 GINsim can define the regulatory network and its parameterization, with the plug-ins such as core logic simulator, node layout algorithm, network analysis algorithm and others. It utilized a standard Java library and could identify small attractor rings for small-scale networks and single attractor for normal networks.53
ADAM can be used to analyze discrete models of different types,54 mainly used to analyze the dynamic properties of models, such as detecting attractor. It can detect the single attractor and the attractor ring in a limited size, if given the network and the parameter m, ADAM can calculate the single attractor and the attractor ring less than m, while the above two methods cannot calculate the attractor ring that larger than 32 nodes; so compared with them, ADAM has better performance.
In addition, Osama42 et al proposed ATLANTIS toolbox which provided a very advanced method of calculating the attractor states. ATLANTIS toolbox is developed by using the MATLAB (R2016a) which is a popular scientific computing platform, and it has the characteristics of completed function, strong performance, low cost of use and high efficiency when compared with other common methods. The comparative criteria include network state-space modeling, analysis types, disturbance types, attractor landscape analysis, cell fate determination and others. To make it more intuitive and easier to choose from, Table 2 makes a simple comparison of the four methods.
 |
Table 2 Comparison of four calculation methods |
There are many ways for calculating attractor, and here is a small part. These algorithms are constantly updated and perfected, which provide an elite weapon for the study of attractor, and greatly promoting the progress of the attractor theory and its application in biomedicine and drug discovery.
Constructing and analyzing the attractor landscape
The concept of attractor landscape originated from the theory of epigenetics topographic map that was proposed by Waddington55 in 1957. The theory held that cell development was like a ball rolled down from a sloping hilltop, and the ball would reach the mountain foot along a certain trajectory, which could correspond to the initial differentiation of stem cells. Besides, the different cell types differentiation were maintained by epigenetic obstacles, but these obstacles could be overcome under sufficient disturbance.
The network updating logic based on biological action mechanism was constructed by Kim et al,56 in order to analyze the attractor landscape, through the trial of synchronous and asynchronous updating rules; the point attractor and its basin which were conservative in two updating rules were obtained, respectively. Then, the scoring system of attractor landscape was introduced to quantitatively evaluate to quantify the malignant degree of cancer. In addition, a toolbox-ATLANTIS based on Boolean networks was proposed by Osama et al,42 which can be used to perform deterministic analysis (DA) and probability analysis (PA) to determine attractor and/or attractor rings. It could further predict cell fate by linking the state of biological related networks to the emergency fate of cells and reprogram the fate of these cells by systematically disrupting the potential biomolecule network. The ATLANTIS had been used to reconstruct the attractor landscape of several published cases; as a result, it was found that not only was this was a low-cost and high-efficiency method, but the analysis results were consistent with the literature report.
Attractor landscape converts complex network behavior into an intuitive network state landscape, and provides an intuitive explanation for the evolutionary relationship between the state of attractor and its surrounding states. Generally speaking, some unstable states will evolve into the same one stable state around them, and this stable state (that is, the attractor state) and its surrounding unstable states would form an attractor region (also known as an attractor basin). Attractor region might correspond to the emergency cell fate or cell phenotype, providing the basis for disease staging and individualized treatment of different stages.
Achieving the state transitions
A biology network consists of many nodes, while a biological organism consists of a variety of networks, such as regular, random and complex network. If an organism is subject to external disturbance beyond its own regulatory capacity, the “disease” or “symptom” state would occur based on network changes.33 The same as the theory of epigenetic obstacles between different cell types can be overcome with sufficient disturbance, when the network evolves into the disease state, we can disturb one or more key nodes in this network, thus achieving a transition from a disease state to the desired state.
Disturbance methods are generally divided into three types: gene intervention, external intervention and structural intervention.
Gene intervention refers to the use of specific methods to inhibit the expression of a gene, or destroying its structure to make it cannot express. The common methods are RNAi, CRISPR-Cas and others. The target genes are always over-expressed oncogenes or viral genes; however, this method has limitations for some complex diseases such as cancer, due to the interaction of multi-gene genetics and environmental factors. Gene intervention is only a transient intervention and cannot change the long-term dynamic behavior of the network. Because this method is not suitable for the attractor research based on systems biology, it is not discussed in details here.
External intervention refers to changing the state of control gene at the current moment, and changing the state of the network to a desired attractor state through a series of evolutions without altering the network structure. In many instances, activation or suppression of specific genes can reverse a selected state (or phenotype) to a specific state (or phenotype). For example, cancer occurs when the p53 gene is knocked out in mouse embryonic stem cells, but it causes growth inhibition or apoptosis when the p53 was reintroduced into the knockout cells.57 At present, there are many studies on external intervention algorithms, such as the mean-first-passage-time (MFPT) algorithm,58,59 the steady-state distribution (SSD) and conservative steady-state distribution (CSSD) algorithm, the basin of attraction (BOA) algorithm based on the attractor,59 the unconstrained (UC) algorithm and the phenotypically constrained (PC) algorithm.60 In previous studies, external intervention accounted for a large proportion.34
Structural intervention refers to minimizing an unexpected attractor region53 or converting a steady-state distribution of a dynamic system into the desired steady-state distribution by reversing the specific input and output of a Boolean function or eliminating the regulatory relationship between specific nodes. It is a persistent intervention that can change the network structure permanently, thereby the network runs in a desired state for a long time finally. After intervention, the initial attractor may no longer be an attractor, but new attractors may emerge, for example, in some countries, women usually use estrogen ketone after menopause to slow aging, but overdoses of estrogen ketone may cause the breast or ovarian cancer (new attractor).34 At present, the simple and common strategy is one-bit Boolean function intervention, that is, the state of a designated node in the Boolean function table is reversed.
Using these disturbance methods for drug discovery and design is a key step for the application of attractor theory into pharmaceutical development and disease treatment. It provides a theoretical explanation for disease treatment from the perspective of attractor and elucidates the potential mechanism of drug action. For the convenience of selection and comparison, we briefly summarized and compared the three methods and listed them in Table 3.
 |
Table 3 Comparison of three disturbance methods |
Achieving drug discovery and design
After discovering potential targets that can be intervened and intervention methods, drug discovery and design for these targets are required. Because of the robustness of the network and the complexity of diseases, it is necessary to target multiple targets at the same time to achieve the reversal of disease state, which also required us to design the drug combination according to the dynamic characteristics of network, the characteristics of drugs and the interaction between the drugs.
Aimed at the previous studies of cancer treatment that most focused on the static analysis of genome-wide changes, a method based on network dynamics was proposed by Choi et al.61 This method combined cancer genomics with biological network dynamics for drug response prediction, cancer subtype classification and drug combination design. Using the p53 network as an example, they performed attractor landscape analysis to obtain the dynamic changes of cancer-specific state transition under different anticancer drugs. As a result, highly specific small molecular inhibitor drugs that targeted at one link and four nodes were, respectively, selected, and these five targeted drugs through either alone or in pairs, with or without the DNA-damaging drug, etoposide, were applied; finally, they analyzed the attractor landscape caused by inhibitory intervention. The results showed that AKT inhibition was effective for cancer treatment, but it was difficult to completely inhibit cancer, so the drug combination was needed. Three effective combinations were found, and the final synergism analysis found that two of them showed the strongest synergistic effect in activating cell death, regardless of network subtypes. This method of attractor analysis based on network dynamics not only enables to stratify cancer cells in terms of kinetics, but also could predict cell-specific drug reactions and carry out effective drug combination design.
Drug discovery and design was the final step in the process of attractor analysis. This method based on the overall level of organism and the angle of system dynamics could theoretically significantly reduce the off-target effect and drug attrition rates, as well as the recurrence of disease, thus providing effective drugs or drug combination for disease control and reversal.
Conclusion
In 2017, Fotis et al62 wrote in a review that the pathway analysis tools based on topology structure could improve the hit rate in the early stages of drug discovery and reduce the drug attrition rates and the huge losses caused by some drugs that had to be discontinued development due to efficacy problems and clinical safety issues. However, there are still some problems with the topology structure approach. For example, some scholars will be skeptical about the quality of data in the network topology database, and there are many contradictory reports indeed. It is difficult to gain new results because the information extracted from the knowledge database might be more biased to the further study of the existing conclusions. Overall data quality could be affected by many factors, such as the difference and rapid updating of experimental instruments, techniques and design methods, and the lack of standardization of data format and experimental design. Moreover, most calculations ignore the dynamic behaviors of biological systems, which ultimately limit the ability to simulate disease or drug intervention accurately.
In summary, attractor theory is employed for drug discovery and design based on the overall level of organisms and the dynamics of system, as well as the dynamic structure of network rather than topology. It focuses on the regulatory relationship between biological molecules, which would not be affected by the data quality of topological databases, and the designed drugs rarely have the problem of off-target and disease recurrence in theory. In addition, the method of attractor state calculation adopts the qualitative method based on Boolean network, which solves the problem that lack of quantitative data and data irregularity in biology. Finally, it is a brand new method and will appear new results. Drug discovery and design with this method can perfectly solve the four-point problems mentioned by Chris et al. Attractor analysis provides a new direction for the conquer of complex diseases, which can be used to analyze network systems of complex diseases and find the key targets that were ebased on network dynamics. And then appropriate strategies were formulated to enable organisms to escape the disease attractor state, thereby overcoming complex diseases. Of course, the attractor method also has some limitations. Due to the limitation of existing algorithms and tools, and the complexity of disease network, even with the binary method of Boolean network, in the case of many nodes, there will still be a combined explosion, which will exceed the computing power of the tools. Further research on attractor and the updating of related technologies are helpful to bridge the gap between computer validation and experimental validation, and will also greatly improve the applicability of attractor method. It is believed that the attractor theory and its method will become a new turning point in drug discovery.
Acknowledgment
This project was funded by the National Natural Science Foundation of China, Award Number 81673697.
Disclosure
The authors report no conflicts of interest in this work.
References
1. Kauffman SA. The Origins of Order: Self-Organization and Selection in Evolution. New York: New York Oxford University Press; 1993.
2. Li F, Long T, Lu Y, Ouyang Q, Tang C. The yeast cell-cycle network is robustly designed. Proc Natl Acad Sci USA. 2004;101(14):4781–4786. doi:10.1073/pnas.0305937101
3. Huang S. Cell fates as attractors: stability and flexibility of cellular phenotypes. In: Aird WC, editor. Endothelial Biomedicine. Cambridge: Cambridge University Press; 2007;1767–1779.
4. Cho SH, Park SM, Lee HS, Lee HY, Cho KH. Attractor landscape analysis of colorectal tumorigenesis and its reversion. BMC Syst Biol. 2016;10(1):96. doi:10.1186/s12918-016-0304-1
5. Zañudo JG, Albert R. Cell fate reprogramming by control of intracellular network dynamics. PLoS Comput Biol. 2015;11(4):e1004193. doi:10.1371/journal.pcbi.1004193
6. Huang S, Ernberg I, Kauffman S. Cancer attractors: a systems view of tumors from a gene network dynamics and developmental perspective. Semin Cell Dev Biol. 2009;20(7):869–876. doi:10.1016/j.semcdb.2009.07.003
7. Huang S, Kauffman S. How to escape the cancer attractor: rationale and limitations of multi-target drugs. Semin Cancer Biol. 2013;23(4):270–278. doi:10.1016/j.semcancer.2013.06.003
8. Zhang DZ. Introduction to Pharmacy.
9. Nie SF, Li JW, Wang XD. Drug Discovery and Invention History.
10. Fischer E. Einflus der Configuration auf die Wirkung der Enzyme [Influence of the configuration on the action of the enzymes]. Eur J Inorg Chem. 2010;27(3):2985–2993. German.
11. Maehle AH, Prüll CR, Halliwell RF. The emergence of the drug receptor theory. Nat Rev Drug Discov. 2002;1(8):637–641. doi:10.1038/nrd875
12. Ahlquist RP. A study of the adrenotropic receptors. Am J Physiol. 1948;153(3):586–600. doi:10.1152/ajplegacy.1948.153.3.586
13. Zhao J. Advances in multi-target and multi-component drug research based on systems biology. Beijing Chin Pharm J. 2010;45(15):1121–1126. Chinese.
14. Medina-Franco JL, Giulianotti MA, Welmaker GS, Houghten RA. Shifting from the single to the multitarget paradigm in drug discovery. Drug Discov Today. 2013;18(9–10):495–501. doi:10.1016/j.drudis.2013.01.008
15. Collis MC. Integrative pharmacology and drug discovery-is the tide finally turning?. Nat Rev Drug Discov. 2006;5(5):377–379. doi:10.1038/nrd2036
16. Maggiora GM. The reductionist paradox: are the laws of chemistry and physics sufficient for the discovery of new drugs? J Comput Aided Mol Des. 2011;25(8):699–708. doi:10.1007/s10822-011-9447-8
17. Kola I, Landis J. Can the pharmaceutical industry reduce attrition rates? Nat Rev Drug Discov. 2004;3(8):711–715. doi:10.1038/nrd1470
18. Wishart DS, Knox C, Guo AC, et al. DrugBank: a comprehensive resource for drug discovery and exploration. Nucleic Acids Res. 2006;34(Database issue):D668–D672. doi:10.1093/nar/gkj067
19. Talevi A. Multi-target pharmacology: possibilities and limitations of the “skeleton key approach” from a medicinal chemist perspective. Front Pharmacol. 2015;6:205. doi:10.3389/fphar.2015.00205
20. Van Regenmortel MH. Reductionism and complexity in molecular biology. Scientists now have the tools to unravel biological and overcome the limitations of reductionism. EMBO Rep. 2004;5(11):1016–1020. doi:10.1038/sj.embor.7400284
21. Petrelli A. Polypharmacological kinase inhibitors: new hopes for cancer therapy. In: Peters J-U, editor. Polypharmacology in Drug Discovery. New Jersey: John Wiley & Sons, Inc.; 2012;149–165.
22. Azmi AS. Network pharmacology for cancer drug discovery: are we there yet? Future Med Chem. 2012;4(8):939–941. doi:10.4155/fmc.12.44
23. Hopkins AL. Network pharmacology. Nat Biotechnol. 2007;25(10):1110–1111. doi:10.1038/nbt1007-1110
24. Hopkins AL. Network pharmacology: the next paradigm in drug discovery. Nat Chem Biol. 2008;4(11):682–690. doi:10.1038/nchembio.118
25. Kitano H. Biological robustness. Nat Rev Genet. 2004;5(11):826–837. doi:10.1038/nrg1471
26. Zhao J, Yu H, Luo JH, Cao ZW, Li YX. Hierarchical modularity of nested bow-ties in metabolic networks. BMC Bioinformatics. 2006;7:386. doi:10.1186/1471-2105-7-386
27. Zhao J, Tao L, Yu H, Luo JH, Cao ZW, Li YX. Bow-tie topological features of metabolic networks and the functional significance. Beijing Chin Sci Bull. 2007;52(8):1036–1045.
28. Jeong H, Mason SP, Barabási AL, Oltvai ZN. Lethality and centrality in protein networks. Nature. 2001;411(6833):41–42. doi:10.1038/35075138
29. Zhao J, Geng C, Tao L, et al. Reconstruction and analysis of human liver-specific metabolic network based on CNHLPP data. J Proteome Res. 2010;9(4):1648–1658. doi:10.1021/pr9006188
30. Yildirim MA, Goh KI, Cusick ME, Barabási AL, Vidal M. Drug-target network. Nat Biotechnol. 2007;25(10):1119–1126. doi:10.1038/nbt1338
31. Thieffry D, Thomas R. Dynamical behaviour of biological regulatory networks–II. Immunity control in bacteriophagelambda. Bull Math Biol. 1995;57(2):277–297. doi:10.1016/0092-8240(94)00037-D
32. Somogyi R, Sniegoski CA. Modeling the complexity of genetic networks: understanding multigenic and pleiotropic regulation. Complexity. 1996;1(6):45–63. doi:10.1002/cplx.v1.6
33. Liu LL. Research on dynamic behavior of boolean networks [dissertation]. Zhejiang: University of Wen Zhou; 2012. Chinese.
34. Hu MX. Research on optimal bit intervention algorithm based on boolean network attraction domain [dissertation]. Zhjiang: University of Wen Zhou; 2016. Chinese.
35. Lähdesmäki H, Shmulevich I, Yli-Harja O. On learning gene regulatory networks under the boolean network model. Mach Learn. 2003;52(1–2):147–167. doi:10.1023/A:1023905711304
36. Dougherty J, Tabus I, Astola J. Inference of gene regulatory networks based on a universal minimum description length. EURASIP J Bioinform Syst Biol. 2008;(1):1–11.
37. Liu W, Lähdesmäki H, Dougherty ER, Shmulevich I. Inference of boolean networks using sensitivity regularization. EURASIP J Bioinform Syst Biol. 2008;(1):780541.
38. Fang J, Ouyang H, Shen L, Dougherty ER, Liu W. Using the minimum description length principle to reduce the rate of false positives of best-fit algorithms. EURASIP J Bioinform Syst Biol. 2014;1:1–8.
39. Madhamshettiwar PB, Maetschke SR, Davis MJ, Reverter A, Ragan MA. Gene regulatory network inference: evaluation and application to ovarian cancer allows the prioritization of drug targets. Genome Med. 2012;4(5):41. doi:10.1186/gm340
40. Ahmed J, Meinel T, Dunkel M, et al. CancerResource: a comprehensive database of cancer-relevant proteins and compound interactions supported by experimental knowledge. Nucleic Acids Res. 2011;39(Database issue):D960–7. doi:10.1093/nar/gkq910
41. Barbarino JM, Whirl-Carrillo M, Altman RB, Klein TE. PharmGKB: a worldwide resource for pharmacogenomic information. Wiley Interdiscip Rev Syst Biol Med. 2018;10(4):e1417. doi:10.1002/wsbm.1417
42. Shah OS, Chaudhary MFA, Awan HA, et al. ATLANTIS - attractor landscape analysis toolbox for cell fate discovery and reprogramming. Sci Rep. 2018;8(1):3554. doi:10.1038/s41598-018-22031-3
43. Glass L, Kauffman SA. The logical analysis of continuous, non-linear biochemical control networks. J Theor Biol. 1973;39(1):103–129. doi:10.1016/0022-5193(73)90208-7
44. Helikar T, Kochi N, Kowal B, et al. A comprehensive, multi-scale dynamical model of ErbB receptor signal transduction in human mammary epithelial cells. PLoS One. 2013;8(4):e61757. doi:10.1371/journal.pone.0061757
45. Choi M, Shi J, Jung SH, Chen X, Cho KH. Attractor landscape analysis reveals feedback loops in the p53 network that control the cellular response to DNA damage. Sci Signal. 2012;5(251):ra83. doi:10.1126/scisignal.2003289
46. Müssel C, Hopfensitz M, Kestler HA. BoolNet–an R package for generation, reconstruction and analysis of boolean networks. Bioinformatics. 2010;26(10):1378–1380. doi:10.1093/bioinformatics/btq124
47. Longabaugh WJ, Davidson EH, Bolouri H. Computational representation of developmental genetic regulatory networks. Dev Biol. 2005;283(1):1–16. doi:10.1016/j.ydbio.2005.04.023
48. Batagelij V, Mrvar A. Pajek- program for large network analysis. Connections. 1998;21(2):47–57.
49. Shmulevich I, Dougherty ER, Kim S, Zhang W. Probabilistic boolean networks: a rule-based uncertainty model for gene-regulatory networks. Bioinformatics. 2002;18(2):261–274. doi:10.1093/bioinformatics/18.2.261
50. Thomas R. Regulatory networks seen as asynchronous automata: a logical description. J Theor Biol. 1991;153(1):1–23. doi:10.1016/S0022-5193(05)80350-9
51. Sánchez L, Thieffry D. A logical analysis of the drosophila gap-gene system. J Theor Biol. 2001;211(2):115–141. doi:10.1006/jtbi.2001.2335
52. Sánchez L, Thieffry D. Segmenting the fly embryo: a logical analysis of the pair-rule cross-regulatory module. J Theor Biol. 2003;224(4):517–537. doi:10.1016/s0022-5193(03)00201-7
53. Zheng QB. Research on boolean network attractor determination algorithm [dissertation]. Zhejiang: University of Wen Zhou; 2015. Chinese.
54. Hinkelmann F, Brandon M, Guang B, et al. ADAM: analysis of discrete models of biological systems using computer algebra. BMC Bioinformatics. 2011;12:295. doi:10.1186/1471-2105-12-295
55. Waddington CH. The Strategy of Genes. London: Routledge; 1957.
56. Kim Y, Choi S, Shin D, Cho KH. Quantitative evaluation and reversion analysis of the attractor landscapes of an intracellular regulatory network for colorectal cancer. BMC Syst Biol. 2017;11(1):45. doi:10.1186/s12918-017-0424-2
57. Tabus I, Astola J. On the use of MDL principle in gene expression prediction. EURASIP J Appl Signal Process. 2001;2001(4):297–303. doi:10.1155/S1110865701000270
58. Vahedi G, Faryabi B, Chamberland JF, Datta A, Dougherty ER. Intervention in gene regulatory networks via a stationary mean-first-passage-time control policy. IEEE Trans Biomed Eng. 2008;55(10):2319–2331. doi:10.1109/TBME.2008.925677
59. Qian X, Ivanov I, Ghaffari N, Dougherty ER. Intervention in gene regulatory networks via greedy control policies based on long-run behavior. BMC Syst Biol. 2009;3:61. doi:10.1186/1752-0509-3-43
60. Yousefi MR, Dougherty ER. Intervention in gene regulatory networks with maximal phenotype alteration. Bioinformatics. 2013;29(14):1758–1767. doi:10.1093/bioinformatics/btt242
61. Choi M, Shi J, Zhu Y, Yang R, Cho KH. Network dynamics-based cancer panel stratification for systemic prediction of anticancer drug response. Nat Commun. 2017;8(1):1940. doi:10.1038/s41467-017-02160-5
62. Fotis C, Antoranz A, Hatziavramidis D, Sakellaropoulos T, Alexopoulos LG. Pathway-based technologies for early drug discovery. Drug Discov Today. 2018;23(3):626–635. doi:10.1016/j.drudis.2017.12.001
 © 2019 The Author(s). This work is published and licensed by Dove Medical Press Limited. The
full terms of this license are available at https://www.dovepress.com/terms
and incorporate the Creative Commons Attribution
- Non Commercial (unported, 3.0) License.
By accessing the work you hereby accept the Terms. Non-commercial uses of the work are permitted
without any further permission from Dove Medical Press Limited, provided the work is properly
attributed. For permission for commercial use of this work, please see paragraphs 4.2 and 5 of our Terms.
© 2019 The Author(s). This work is published and licensed by Dove Medical Press Limited. The
full terms of this license are available at https://www.dovepress.com/terms
and incorporate the Creative Commons Attribution
- Non Commercial (unported, 3.0) License.
By accessing the work you hereby accept the Terms. Non-commercial uses of the work are permitted
without any further permission from Dove Medical Press Limited, provided the work is properly
attributed. For permission for commercial use of this work, please see paragraphs 4.2 and 5 of our Terms.