Back to Journals » Journal of Healthcare Leadership » Volume 17
Artificial Intelligence in Cancer Oncology Through Comprehensive Bibliometric Mapping of Global Trends Impact and Conceptual Structures
Authors Caraka RE, Supardi K, Gondhowiardjo SA ![]() , Isnaniawardhani V, Gio PU, Chen RC, Pardamean B
, Isnaniawardhani V, Gio PU, Chen RC, Pardamean B ![]()
Received 2 July 2025
Accepted for publication 3 October 2025
Published 29 October 2025 Volume 2025:17 Pages 591—621
DOI https://doi.org/10.2147/JHL.S550933
Checked for plagiarism Yes
Review by Single anonymous peer review
Peer reviewer comments 2
Editor who approved publication: Dr Pavani Rangachari
Rezzy Eko Caraka,1– 4 Khairunnisa Supardi,5 Soehartati A Gondhowiardjo,5 Vijaya Isnaniawardhani,1 Prana Ugiana Gio,6 Rung Ching Chen,4 Bens Pardamean7,8
1Engineers Profession Program, Graduate School, Universitas Padjadjaran, Bandung, West Java, 45363, Indonesia; 2School of Economics and Business Telkom University, Bandung, 40257, Indonesia; 3Research Center for Data and Information Sciences, Research Organization for Electronics and Informatics, National Research and Innovation Agency (BRIN), Bandung, 40135, Indonesia; 4Department of Information Management, Chaoyang University of Technology, Taichung, 41349, Taiwan; 5Department of Radiation Oncology, Faculty of Medicine Universitas Indonesia - Dr Cipto Mangunkusumo National General Hospital, Jakarta, 10430, Indonesia; 6Department of Mathematics, Universitas Sumatera Utara, Medan, Indonesia; 7Bioinformatics and Data Science Research Center, Bina Nusantara University, Jakarta, 11480, Indonesia; 8Computer Science Department, BINUS Graduate Program – Master of Computer Science Program, Bina Nusantara University, Jakarta, 11480, Indonesia
Correspondence: Rezzy Eko Caraka, Email [email protected] Rung Ching Chen, Email [email protected]
Abstract: The integration of artificial intelligence, particularly deep learning, has transformed cancer oncology through more precise diagnostics, personalized therapies, and improved clinical decision-making. This study conducts a bibliometric mapping to capture global research trends, intellectual influence, and conceptual structures in cancer oncology and deep learning. A total of 19,627 peer-reviewed articles published between 2022 and 2025 were analyzed, retrieved from an initial dataset of 34,218 documents. Using Correspondence Analysis (CA) and Multiple Correspondence Analysis (MCA) in RStudio, we evaluated both Author Keywords and Keyword Plus. The results highlight dominant themes, including multimodal learning and radiogenomics, while also uncovering emerging directions such as transformer-based models, federated learning for cross-institutional data, and the ethical dimensions of explainable AI in clinical workflows. MCA on Keyword Plus provided stronger explanatory power (80.01% and 8.76% for the first two dimensions) compared to CA on Author Keywords (5.27% and 3.73%). This mapping reveals critical gaps—such as limited participation from low- and middle-income countries, lack of standardized datasets, and insufficient multidisciplinary collaboration. By identifying these challenges and opportunities, the study provides actionable insights for researchers, policymakers, and clinicians to advance inclusive and ethically responsible AI-driven cancer research.
Keywords: cancer oncology, deep learning, artificial intelligence, bibliometric analysis, machine learning in cancer
Introduction
Cancer remains a significant health challenge in Indonesia, with an increasing number of new cases and deaths each year. The data from The Global Cancer Observatory (GCO) in 2022 provides a detailed picture of the cancer burden in the country, which saw a total of 408,661 new cancer cases. The number of deaths attributed to cancer in Indonesia reached 242,988, while 1,018,110 individuals were living with cancer as prevalent cases over the previous 5 years. These statistics underscore the urgent need for comprehensive cancer prevention, early detection, and treatment strategies to reduce the burden of this disease on individuals and the healthcare system.1–3
The Indonesian population in 2022 was approximately 279 million, with nearly equal distribution between males and females. Among the total number of new cancer cases, males accounted for 188,395, while females represented 220,266. The age-standardized incidence rate for cancer was relatively high, with males at 135.5 per 100,000 and females at 141.6 per 100,000. This indicates that cancer is a widespread health issue, affecting both genders with significant frequency. Additionally, the risk of developing cancer before the age of 75 is substantial, with a cumulative risk of 14.1% for males and 14.0% for females, reflecting the significant likelihood of a person developing cancer in their lifetime.
Among males, lung cancer emerged as the most prevalent type, accounting for over 15% of all new cancer cases. Colorectal cancer followed closely behind, with a notable number of new cases, while liver cancer ranked third. Other common cancers in males included nasopharyngeal cancer and prostate cancer.4–6 Together, these five types of cancer dominated the landscape of cancer diagnoses in Indonesian men. Lung cancer, in particular, poses a substantial health risk due to its high incidence and the significant mortality associated with it. Despite the prominence of these five cancers, a large portion of new cases in males—nearly half—are attributed to other types of cancer, highlighting the diverse nature of cancer in the population.
For females, breast cancer was by far the most common, with a substantial proportion of new cases diagnosed in 2022. Cervical cancer ranked second, followed by ovarian cancer, which also contributed to a significant number of cancer cases among women.7–9 Colorectal cancer and lung cancer rounded out the top five most common cancers in females. The prevalence of breast cancer, in particular, stands out due to its high incidence, accounting for more than 30% of new cancer cases in women. Similar to males, a large percentage of cancer cases in females—more than a third—were attributed to other types of cancer, illustrating the variety and complexity of the cancer burden in Indonesian women.
When considering both sexes combined, the top five most frequent cancers are largely similar to those observed in each gender individually. Breast cancer remains the most common, followed by lung cancer, cervical cancer, colorectal cancer, and liver cancer. These cancers account for the majority of new cancer cases in the country, with breast cancer emerging as the most prevalent overall. However, the data also reveals that over half of the new cancer cases in Indonesia are attributed to other cancers, further emphasizing the wide range of cancer types affecting the population. This diverse cancer landscape highlights the need for a multifaceted approach to cancer prevention and treatment, as well as more targeted efforts in addressing the most common cancers affecting the Indonesian population.
As the burden of cancer increases, the need for more effective methods of diagnosis and treatment becomes increasingly urgent. In recent decades, advances in information technology and computing have opened up new opportunities in medicine,10,11 particularly through the application of artificial intelligence (AI). One branch of AI that shows great potential in the field of oncology is deep learning (DL). This technology has changed the way we approach cancer detection and treatment, offering new ways to identify and deal with the disease faster, more accurately, and more efficiently.
Deep learning, as part of machine learning, has the ability to learn complex data representations through multi-layered artificial neural networks.12,13 This capability allows the DL to identify hidden patterns in large and complex medical data, such as medical images, genomic data, and electronic medical records. In the context of cancer, deep learning has been applied for a variety of purposes, including early detection, classification of cancer types, prediction of responses to therapy, and analysis of prognosis.14–17 The main advantage of DL lies in its ability to process large amounts of data and find correlations that may not be detected by conventional methods.18–21
For example, a recent study developed an AI tool called FaceAge that analyzes facial features of cancer patients to estimate biological age and predict survival outcomes. It uses DL algorithms trained on nearly 59,000 healthy individual photos and tested on more than 6000 cancer patients.22,23 The results showed that patients who looked older than their chronological age tended to have lower survival rates, regardless of other factors such as cancer type or gender. This indicates that DL can not only be used to identify health-related physical characteristics, but can also provide new insights into the prognosis of more personalized cancer patients.24–28
Notwithstanding the expanding corpus of research in this field, there has yet to be a thorough bibliometric analysis evaluating research trends, institutional collaboration, and principal topic areas in the application of deep learning to oncology. Performing this analysis is essential, as bibliometric mapping offers significant insights into research progression, the identification of emergent themes, and the depiction of scientific collaborative networks. In the context of cancer research, bibliometric analysis can identify underexplored domains that require additional inquiry and evaluate the degree of integration of deep learning into cancer diagnosis and treatment. This approach not only elucidates the existing state of knowledge but also guides strategic directions for future research by pinpointing gaps and promising avenues for multidisciplinary collaboration. Moreover, comprehending the global framework of deep learning applications in oncology can assist politicians, funding organizations, and healthcare institutions in optimizing resource allocation, ensuring that innovation corresponds with the most urgent requirements in cancer treatment. This paper performs a thorough bibliometric analysis of deep learning applications in cancer research to solve this gap. This study offers a comprehensive picture of the area by methodically analyzing publication patterns, principal authors, collaboration networks, and theme clusters. The results are anticipated to enhance comprehension of the influence of deep learning on cancer research, while providing essential assistance for academics, practitioners, and policymakers in recognizing emerging frontiers and refining future research trajectories.
Methods
In this section, we describe in depth the methodology used in this study, focusing on the bibliometric approach applied to analyze publications on the application of deep learning to cancer. This approach involves the use of bibliometric analysis software to explore publication trends, collaboration between institutions, and keyword analysis in literature.
Biblioshiny
Biblioshiny is a web-based graphical user interface that allows easy exploration and visualization of bibliometric data. The device is used in conjunction with the Bibliometrix package at R, which allows comprehensive bibliometric analysis of publication data.29–32 Biblioshiny helps in producing interactive graphs that illustrate trends in publications, collaboration between authors and institutions, and frequency analysis of keywords. In this study, the first step was to import the cleared data into the Biblioshiny for early exploration. This process involves removing duplicates and irrelevant articles, such as language articles other than English and types of documents other than journal articles, conferences, or systematic reviews.33–35
Biblioshiny is used to visualize the distribution of annual publications, as well as identify the latest trends that develop in the application of deep learning to cancer. Biblioshiny enabled the analysis of the most productive network of authors and journals as well as the involvement of institutions and states in this study.29,30,33,36,37 Overall, Biblioshiny use provides a clear and interactive picture of DL’s research landscape in cancer, allowing researchers to easily explore a wide range of insights through web-based visualizations. To explore the relationships between variables in bibliometric data, more complex mathematical models and descriptive statistical calculations were performed. Among the techniques used were temporal analysis and keyword mapping, which involved calculations based on derived formulas to understand the dynamics of the study.31,38,39
One of the basic formulas in this bibliometric analysis involves the calculation of Index H used to measure the author’s productivity and scientific impact. The H index is calculated using equation 1.

With 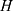 the number of publications having more than hits. In addition, for temporal analysis, the calculation of the annual growth index is used to identify the growth rate of publications each year. The index is calculated by equation 2.
the number of publications having more than hits. In addition, for temporal analysis, the calculation of the annual growth index is used to identify the growth rate of publications each year. The index is calculated by equation 2.
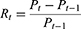
where 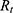 is the annual growth rate in the t-year, and
is the annual growth rate in the t-year, and 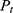 is the number of publications that year. This formula is helpful in looking at the growth trends of publications over time and identifying significant change points.32,34,40–42 In addition, the analysis of co-citation and co-authorization used in this study involved calculating the strength of relationships between authors or articles. This can be calculated by the Jaccard Index or similarity index formula used to measure how similar two articles or authors are based on their shared citations which are shown in equation 3.
is the number of publications that year. This formula is helpful in looking at the growth trends of publications over time and identifying significant change points.32,34,40–42 In addition, the analysis of co-citation and co-authorization used in this study involved calculating the strength of relationships between authors or articles. This can be calculated by the Jaccard Index or similarity index formula used to measure how similar two articles or authors are based on their shared citations which are shown in equation 3.

where A and B are two articles or authors, and  and
and  are slice and merge operations.
are slice and merge operations.
Co-Occurrences
Co-occurrence analysis is one of the main techniques in bibliometrics used to identify the relationship between keywords that often appear together in the same publication. This analysis is important to reveal the thematic patterns and trends in the literature, as well as to see how specific topics develop in research.43–45
In this study, keyword co-occurrence analysis was conducted using R software to visualize a network of keywords that often appear together. This analysis process involves the following steps. First, it is constructed by calculating the frequency of occurrences of keyword pairs appearing together in the same publication. This matrix is then used to identify keywords that have strong relationships. Then is the Determination of the Weight and Distance Between Keywords. After the matrix is formed, each keyword is weighted according to the frequency of its appearance in the publication. Keywords that appear together more often in the same article will have higher weight. Next, the distance between keywords is calculated based on the strength of the relationship between them. R is also used to build network visualizations that describe the relationships between keywords. Keywords that often appear together will be grouped within a given cluster, which allows the identification of key themes in deep learning research for cancer. Bibliometric analysis uses a frequency and relationship approach between bibliographic elements. In general, if given a set of documents D,46 then the total frequency of occurrence of keywords in all documents can be expressed in equation 4.
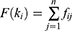
where 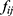 is the frequency of the keyword
is the frequency of the keyword 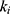 in the
in the  -th document, and
-th document, and  is the total number of documents. To construct a co-occurrence network between keywords, the symmetry matrix M with the element
is the total number of documents. To construct a co-occurrence network between keywords, the symmetry matrix M with the element 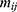 specifies the number of occurrences together between keywords and is used to construct a co-occurrence network between keywords in equation 5.
specifies the number of occurrences together between keywords and is used to construct a co-occurrence network between keywords in equation 5.

where K is a binary matrix of dimension 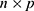 , where
, where  is the number of unique keywords, and every element
is the number of unique keywords, and every element 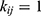 if the keyword appears in the document, and 0 if not. Visual mapping of the analysis results is done through the conceptualStructure() to detect major research themes, thematicMap() to map the power and centrality of the topic, and histNetwork() to view temporal evolution. With this approach, all analyses can represent the intellectual structure and knowledge development in the DL field for cancer in a systematic and data-based manner.
if the keyword appears in the document, and 0 if not. Visual mapping of the analysis results is done through the conceptualStructure() to detect major research themes, thematicMap() to map the power and centrality of the topic, and histNetwork() to view temporal evolution. With this approach, all analyses can represent the intellectual structure and knowledge development in the DL field for cancer in a systematic and data-based manner.
Through a combination of rigorous analytical approaches, comprehensive databases, and informative visualizations, the methods in this study produce knowledge maps that can be used by researchers, research institutions, and researchers, and policymakers to understand and direct the development of DL’s cancer research in a more strategic and influential direction.
Correspondence Analysis
Correspondence Analysis (CA) is a multivariate statistical technique used to explore relationships in categorical data.47,48 In bibliometric studies, CA helps visualize associations between different categorical variables such as keywords, authors, institutions, or journals, often derived from co-occurrence matrices. Let 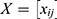 be a contingency table of size
be a contingency table of size 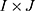 , where
, where 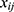 represents the frequency with which keyword
represents the frequency with which keyword 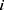 co-occurs with document
co-occurs with document 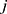 ,
, 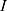 is the number of rows (eg, keywords), and
is the number of rows (eg, keywords), and 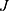 is the number of columns (eg, documents). Here, we define the grand total in Equation 6, The relative frequency matrix in equation 7, The row and column marginal proportions in Equation 8, and The standardized residual matrix in equation 9.
is the number of columns (eg, documents). Here, we define the grand total in Equation 6, The relative frequency matrix in equation 7, The row and column marginal proportions in Equation 8, and The standardized residual matrix in equation 9.




where 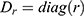 and
and 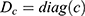 . CA performs a singular value decomposition (SVD) on
. CA performs a singular value decomposition (SVD) on  in equation 10.
in equation 10.
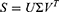
The principal coordinates of rows in Equation 11 and columns in equation 12 reduced space.
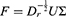

In the context of Bibliometrix, CA is typically used on co-occurrence matrices (eg, keyword–keyword or author–document matrices). It provides a low-dimensional spatial representation of the relationships among entities.
M <- biblioNetwork(biblio_data, analysis = “co-occurrences”, network = “keywords”, sep = “;”) conceptualStructure(M, method=“CA”, field=“ID”, minDegree=5, k.max=5)
The output consists of a two-dimensional plot that visually maps the proximity of keywords or documents based on their co-occurrence patterns. This spatial representation reveals clusters of terms that indicate topical similarity, allowing for the identification of coherent research themes and conceptual relationships within the analyzed literature.
Multiple Correspondence Analysis (MCA)
Multiple Correspondence Analysis (MCA) generalizes CA to handle more than two categorical variables. It is ideal for analyzing complex relationships in bibliometric data where multiple categorical features (eg, author keywords, journal, country) are observed simultaneously.49,50 Assume we have a data matrix 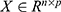 , where
, where  is the number of documents (individuals),
is the number of documents (individuals), 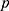 is the total number of binary indicator variables derived from categorical variables. Each categorical variable (eg, keyword, country, source) is transformed into binary dummy variables, leading to an indicator matrix.51 Let
is the total number of binary indicator variables derived from categorical variables. Each categorical variable (eg, keyword, country, source) is transformed into binary dummy variables, leading to an indicator matrix.51 Let  be the complete indicator matrix (concatenated binary variables),
be the complete indicator matrix (concatenated binary variables), 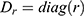 where
where  is the vector of row masses,
is the vector of row masses, 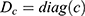 , where
, where  is the vector of column masses. MCA performs SVD on the standardized matrix
is the vector of column masses. MCA performs SVD on the standardized matrix 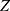 .
.
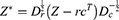
The principal coordinates are extracted similar to CA, giving a geometric representation of the relationships between modalities. In bibliometric analysis, particularly when using the Bibliometrix package in R, the conceptualStructure function provides a robust way to explore the thematic organization of scientific literature. By specifying field = “ID”, the analysis is based on author keywords, which are crucial indicators of a paper’s content and help to map the conceptual structure of a research domain. Author keywords are selected by the authors themselves and typically reflect the main themes and focus of their work, making them an ideal proxy for identifying key topics in a dataset.
The parameter method = “MCA” indicates that the technique being applied is Multiple Correspondence Analysis. MCA is especially effective in reducing multidimensional categorical data—such as collections of keywords—into a low-dimensional space that can be easily visualized and interpreted. Unlike traditional Correspondence Analysis, which only handles two categorical variables at a time, MCA allows for simultaneous analysis of multiple variables, making it particularly powerful when analyzing a large set of documents with diverse descriptors.
Setting minDegree = 5 ensures that only keywords appearing in at least five documents are considered in the analysis. This threshold filters out low-frequency terms that may add noise rather than value to the structure, thus sharpening the focus on more relevant and widely used concepts. Similarly, k.max = 5 specifies that the algorithm will attempt to identify up to five clusters of related keywords. These clusters represent dominant research themes within the literature, as determined by patterns of co-occurrence and conceptual similarity. The output of this process includes a factor map that visually represents the relationships among keywords and their associated documents in a reduced dimensional space. In these maps, terms that are positioned closely together tend to appear in similar contexts across different documents, suggesting thematic or conceptual proximity. These visualizations aid in identifying dominant research areas, understanding the interrelations between topics, and revealing how different themes cluster within the scientific field. This approach provides valuable insights into the structure of a research landscape and helps scholars discern emerging trends, gaps, and focal points within their domain of study.
Data Set
This study has a high degree of novelty over previous analyses due to its much wider scope of over 34 thousand publications, as well as the use of a combination of modern analytical devices such as R with Bibliometrix packages. This approach enables integration between network-based visualization, situational analysis, and high-precision topical evolution modeling. The study’s main focus is to uncover temporal dynamics in scientific publications, highlighting the surge in new terms such as transfer learning, federated learning, multi-omic integration, and explainable AI that have dominated literature in the past 2 years. In this paper, the approach used is quantitative and exploratory based on bibliometric analysis by utilizing open-source software R and the Bibliometrix library. The dataset analyzed is sourced from the Scopus database, which is one of the largest and most comprehensive repositories for scientific publications. Data retrieval took place in May 2025 using the main keyword “cancer” AND “deep” AND “learning” which resulted in a total of 34,218 relevant documents and met the inclusion criteria as shown in Table 1.
 |
Table 1 Main Information |
The initial process involves extracting the metadata from the BibTeX file from the Scopus download, which is then cleared to remove the duplicates and inappropriate publications. The data is then loaded into the R environment and analyzed using key functions in the Bibliometrix package such as biblioshiny(), summary(), and networkPlot().
All analyses are run in the latest version of the RStudio computing environment. After cleaning with relevant journals, the focus of the analysis continues to monitor trends of key information about the data, with the analysis time range covering the period 2022 to 2025. The selection of this period is based on reasons for identifying the latest trends and significant changes in the focus of research, as well as for analyzing the emergence of new dominating terms in the field of applying deep learning to cancer in the past two years.
Results
This study showed significant developments in research that combined deep learning with cancer treatment, based on data covering more than 19,000 relevant documents, with an analysis period from 2022 to 2025. With a very high annual growth rate of 91.54%, it can be seen clearly that this topic has experienced a significant spike in recent years, reflecting increasing interest and investment in this field. The data also show that the average age of publication is only 1.23 years old, which indicates that most of these studies are highly relevant to the current trends in deep learning technology for cancer.
With an average citations per document of 4787, the publication has had a major impact in scientific literature, reflecting the impact these studies have had on the global scientific community. Collaboration between authors is also an interesting aspect, with an average co-author per document reaching 6.02 people. This indicates that many publications involve research teams from various backgrounds and expertise, as well as demonstrate the importance of collaboration in the development of new technologies and methods for cancer diagnosis and treatment. In addition, about 24.44% of publications recorded international collaboration, which showed the importance of cross-country cooperation in solving global challenges in the field of oncology.
Most of these publications consist of journal articles, with a total of 11,338 documents, suggesting that most of the research findings were published in scientific journals that had a major impact. In addition, many publications were also present in the form of conference papers (5277 documents) and books (29 documents), showing variations in the distribution format of research results in various academic and scientific forums. In addition, research in this field has identified emerging topic trends, such as transfer learning, federated learning, and explainable AI, which have increasingly dominated literature in recent years, reflecting efforts to develop more transparent and understandable AI technologies in the context of cancer treatment. Using more extensive and up-to-date data, as well as modern analytical tools such as Bibliometrix and RStudio, the study successfully provided a more comprehensive picture of the dynamics of deep learning and cancer research. While demonstrating how scientific collaboration and multi-omic data integration continue to drive developments in this technology for the future of cancer treatment.
Most Relevant Sources
In studies of the application of deep learning to cancer treatments, a number of journal and conference sources have contributed greatly to the development of literature in this area. Among the various existing sources, some publications have emerged as major contributors to the promotion of deep learning technology knowledge and application to the medical field, especially in the context of cancer. A very dominant source is Lecture Notes in Networks and Systems, with 406 articles offering much research related to network engineering and systems. These articles form the foundation for understanding and application of deep learning in analyzing complex medical data, especially in the field of cancer as shown in Figure 1. These major contributions include a new understanding of how tissue techniques can be optimized for cancer diagnosis and therapy. In addition, Biomedical Signal Processing and Control with 392 articles also provides deep insight into biomedical signal processing. This is particularly relevant for the application of deep learning, especially in processing large and diverse medical signals to identify cancer-related patterns.
 |
Figure 1 Most relevant sources. This figure displays the number of documents published per source, sorted from lowest to highest. Each bubble represents a specific source, and its size corresponds to the number of documents. The numbers inside the bubbles indicate the exact document counts. |
Another very relevant source is Scientific Reports (381 articles), which serves as a platform for a variety of scientific studies that integrate a variety of new technologies into medicine, including deep learning. These articles reveal important findings regarding the use of AI technology to diagnose, forecast, and treat cancer, strengthening AI’s contribution to the field of oncology. Cancer (312 articles) and IEEE Access (312 articles) are two other journals that consistently focus on innovative research in AI applications in the field of cancer, ranging from basic research to clinical applications. In addition, Computers in Biology and Medicine (300 articles) played a major role in excavating computing applications in the medical world, with an emphasis on the use of deep learning for increasingly large and complex medical data analyses. This is especially important given the increasing volume and diversity of medical data in cancer diagnosis and treatment. Diagnostics (298 articles) are also a very relevant source, given that the journal specializes in diagnostic engineering research closely related to AI’s progress in detecting cancer.
Furthermore, Frontiers in Oncology (261 articles) focused on the development and application of the latest technology in oncology, where deep learning plays a key role in identifying and classifying cancers based on patterns found in medical data. Another significant journal is Multimedia Tools and Applications (227 articles), which discusses how multimedia technology can be combined with deep learning to improve visualization and data understanding capabilities in the context of cancer treatment. Overall, these sources highlight the diversity and depth of research in the field of deep learning for cancer. From aspects of biomedical signal processing to broader applications in diagnostic and therapy systems, this literature shows how advances in information technology and AI are increasingly leading to increased efficiency in cancer care. This paved the way for further development in more personalized and data-based cancer therapy, making this field increasingly relevant and important in today’s medical world.
From the analysis of relevant literature sources in the field of biomedicine, especially those related to the application of deep learning in cancer diagnosis and therapy, it can be seen that some journals have had a major impact, both in academic research and in their application in the medical field. DIAGNOSTICS, with h-index 31 and g-index 42, stands out with a fairly high m-index of 7.75. This journal, although only published in 2022, has recorded 3450 citations and published 298 articles. This indicates that DIAGNOSTICS played a major role in the development of current technology-based diagnostic techniques, including the use of deep learning for medical image processing. This source contributes significantly to addressing the challenges of early diagnosis of cancer through the use of advanced algorithms that accurately analyze medical image data. The following sources that show significant impact are Biomedical Signal Processing and Control published in 2023. The journal has h-index 29 and g-index 42, with m-index 9.667, which signifies a tremendous impact in a short time. With 3509 quotes and 392 articles, Biomedical Signal Processing and Control focuses on the processing of biomedical signals applied in disease detection and therapy, especially cancer. It illustrates how AI-based signal processing techniques can help in the preparation of more precise and personalized treatment protocols in Table 2.
 |
Table 2 Sources’ Local Impact |
In addition, Computers in Biology and Medicine, which have h-index 29 and g-index 45, have a significant impact with 3053 citations. Focusing on computational applications in biology and medicine, the journal discusses deep learning integration in biomedical data analysis, which is important for a deeper understanding of the biological processes involved in cancer. Its advantages in linking technology with medical practice provide useful insights for the development of more efficient and precise diagnostic tools in dealing with cancer. Scientific Reports, with h-indexes 29 and 3138 citations, played an important role in providing a platform for researchers to share their findings on applicable technological advances in medicine. The journal focuses not only on current technologies, but also on interdisciplinary research involving a variety of approaches, including AI and deep learning, in addressing a variety of medical challenges.
The journals Cancer and IEEE Access show a very large contribution to developing AI technology-based medical solutions. With 312 articles and over 2700 citations, Cancer has become an important reference source in cancer research, particularly in integrating new technologies into medicine and diagnosis. IEEE Access, although published in 2023, with 312 articles and more than 2500 citations, further solidifies its position as a major source of healthcare AI technology, which plays a role in increasing the effectiveness of cancer diagnosis and treatment.
Other journals such as Expert Systems with Applications and Multimedia Tools and Applications also showed significant impact, with 1274 and 1792 quotes, respectively. Both play a role in developing intelligent systems and multimedia applications that are highly relevant to deep learning-based medical data processing and cancer. This suggests that the field of deep learning research is not only limited to statistical algorithms, but also involves a broader intelligent system approach to improving diagnostic and therapeutic processes in cancer treatment.
Medical Image Analysis and Frontiers in Oncology have a particular focus on medical image processing and deep learning applications in cancer detection. With m-indexes 6 and 4, respectively, these journals provide important insight in understanding how current technologies can be applied to improve accuracy and efficiency in cancer diagnosis through more in-depth medical image analysis.
Overall, despite variations in the citation index and its impact, these journals reflect a strong trend in deep learning technology integration to improve cancer diagnosis and therapy. The emphasis on synergy between signal processing, medical image analysis, and AI applications suggests that we are on the verge of a major breakthrough in the medical field. This provides great expectations for the progress of more targeted and data-driven cancer treatment, and potentially reduces the burden of the disease at a global level.
Most Relevant Affiliation
The analysis of affiliates in this field of research illustrates the vast global landscape, in which a number of universities and medical centers stand out in terms of the number of published articles as shown in Figure 2. At the top of the list, Fudan University led with 324 articles, followed by Sun Yat-sen University with 299 articles, and Southern Medical University with 270 articles. These institutions represent a significant part of the research output, particularly in the medical and biomedical sciences, which reflects their strategic focus on advancing research in healthcare and technology.
 |
Figure 2 Most relevant affiliation. This figure illustrates the distribution of documents by author affiliation. Each bubble represents an institution, and its size corresponds to the number of documents published by that institution. The numbers inside the bubbles indicate the exact document counts. |
In addition, Harvard Medical School (259 articles) and Sichuan University (244 articles) also contributed greatly to the research world, showing their important roles in advanced research, especially in cancer and medical technology. The University of Texas MD Anderson Cancer Center with 223 articles is also a key player, strengthening its status as the world’s leading cancer research center.
Among other universities that have also played a significant role in research are Shanghai Jiao Tong University (227 articles), Central South University (220 articles), and the University of California (220 articles), all of which have strong research programs and have a major impact in their respective fields. This pattern highlights the importance of collaboration in various fields of research, ranging from bioengineering to cancer treatment and medical imaging.
The University of Toronto and Stanford University, known for their contributions to medicine, public health, and technology, are also important actors in the research community, with more than 150 articles each. The growing influence of Asian universities, such as Zhejiang University and Tsinghua University, shows an increased global focus on research excellence outside traditional Western centers.
As an illustration of the distribution of the output of this study is described in Figure 2, we can see some important patterns that can be used as reflection materials. First, there is strong dominance of universities and medical centers in China, such as Fudan University, Sun Yat-sen University, and Sichuan University, which show how fast research progresses in the country, especially in the fields of biomedical, health, and technology. It reflects how the Chinese government’s policies supporting research and innovation began to yield significant results on a global scale.
Second, medical and cancer institutions such as Harvard Medical School, MD Anderson Cancer Center, and Memorial Sloan Kettering Cancer Center show consistency in their contributions to cancer research and medical innovation. This confirms the importance of international collaboration in encouraging new discoveries and solutions to global health challenges.
In addition, it is also important to note that international collaboration is increasingly playing a very large role. Prominent institutions, although distributed around the world, often collaborate on transnational research, forming a network that can address shared global challenges. The increasingly calculated role of universities in Asia such as Zhejiang University and Tsinghua University suggests that research influence is now not limited to the West, but is growing rapidly in the Asian region, which will continue to be a major player in scientific and technological innovation in the future.
Corresponding Author’s Countries and Most Cited Countries
Our findings provide insight into countries’ contributions to global scientific publications, with China, India, and the United States at the top of the list in terms of the number of articles published. China led with 4773 articles, covering nearly a quarter of the total publication. India also showed significant strength with 3531 articles. It reflects the dominance of major countries in the research world, especially in the fields of technology, medicine, and science, where they play a major role in the innovation and development of science as shown in Figure 3.
 |
Figure 3 Collaboration MCP and SCP. This figure compares Multiple Country Publications (MCP) and Single Country Publications (SCP) among contributing authors. MCP represents international collaborations involving authors from more than one country, while SCP represents publications authored within a single country. The bar lengths (or bubble sizes, if applicable) indicate the number of documents under each category. |
But what’s interesting about this data is the pattern of collaboration that appears in scientific publications. Countries such as China and India are mostly dominated by writers who work independently as corresponding authors (SCPs), with most articles published by one main author. Nevertheless, collaboration remains important, as seen in the percentage of articles with multiple corresponding authors (MCPs), which are lower in these major countries. This could indicate that while individual contributions are important, broader collaboration outside their country also plays a role in the quality and impact of scientific publications.
On the other hand, countries such as Saudi Arabia and Pakistan are showing a greater tendency toward collaboration. This is reflected in the percentage of articles with higher multiple corresponding authors in both countries. This may indicate that, despite their lower number of publications, collaboration is becoming an important strategy to increase the visibility and influence of their research at the global level. This collaboration can also accelerate research progress by utilizing the expertise of various international institutions.
In addition, countries such as Indonesia with a lower number of publications (109 articles) showed a tendency to work more individually. This shows that although Indonesia contributes to global research, they tend to focus on domestic or local research. This can be an indication of the need for increased international cooperation and integration in global research networks to increase the impact and quality of Indonesian research.
Overall, we highlights the importance of collaboration in the world of scientific research. Although major countries dominate in terms of the number of publications, other countries that tend to collaborate more can benefit from international cooperation to improve the quality and visibility of their research.
The data on the countries with the highest number of citations provides an interesting picture of the global scientific impact described in Figure 4. China, India, and the United States dominate in terms of the total number of situations (TCs), reflecting their great contribution to global research. China, with 23,716 citations, shows how wide the country’s research scope is. Although India has a lower number of citations than China (13,755), this figure still reflects that India’s research has a significant impact on the global scientific community. On the other hand, the United States with 10,115 citations has a higher average article citations of 6.30, which show greater quality and influence than scientific works originating in the country.
 |
Figure 4 Most cited countries. This figure shows the countries with the highest citation counts. Each bar (or bubble, if applicable) represents a country, and its length/size corresponds to the total number of citations received. Numbers inside or beside the bars indicate the exact citation counts for each country. |
More interesting, however, are the countries with very high average citations despite their relatively lower totality. For example, Qatar, with 466 citations, has an average article citations of 12.90, which is one of the highest on this list. This shows that although their publications are not as much of a major country, the scientific work originating from Qatar is highly regarded and widely referred to by other researchers. Smaller countries such as Ireland (12.10), Ethiopia (10.30), and Switzerland (9.90) also showed striking figures in terms of average citations, indicating high quality in their research despite lower publication volume.
Countries such as Indonesia and Algeria with lower citations (218 and 214, respectively) have also lower citations. This may indicate that while these countries contribute to global research, their works may not receive the same recognition in terms of citations as compared to countries with more publications or more international collaborations. Overall, this reveals the importance of the quality of research reflected in the number of citations per article. Countries with high citations such as Qatar and Ireland have shown that quality can outperform quantity in terms of scientific influence. Major countries with a high number of publications, such as China and the United States, also show that they have a great influence both in the number of publications and in the impact of citations.
Most Global Cited Documents
Table 3 showcases the top 50 most globally cited scientific documents, highlighting their profound impact and central role in advancing research at the intersection of medicine and artificial intelligence (AI). These influential works not only boast remarkable citation records but also contribute groundbreaking methodologies and transformative insights—particularly in the realms of medical imaging, cancer diagnostics, and the integration of machine learning (ML) into clinical practice. Their prominence underscores the growing synergy between computational innovation and healthcare solutions, positioning them as foundational references for both current research and future breakthroughs.
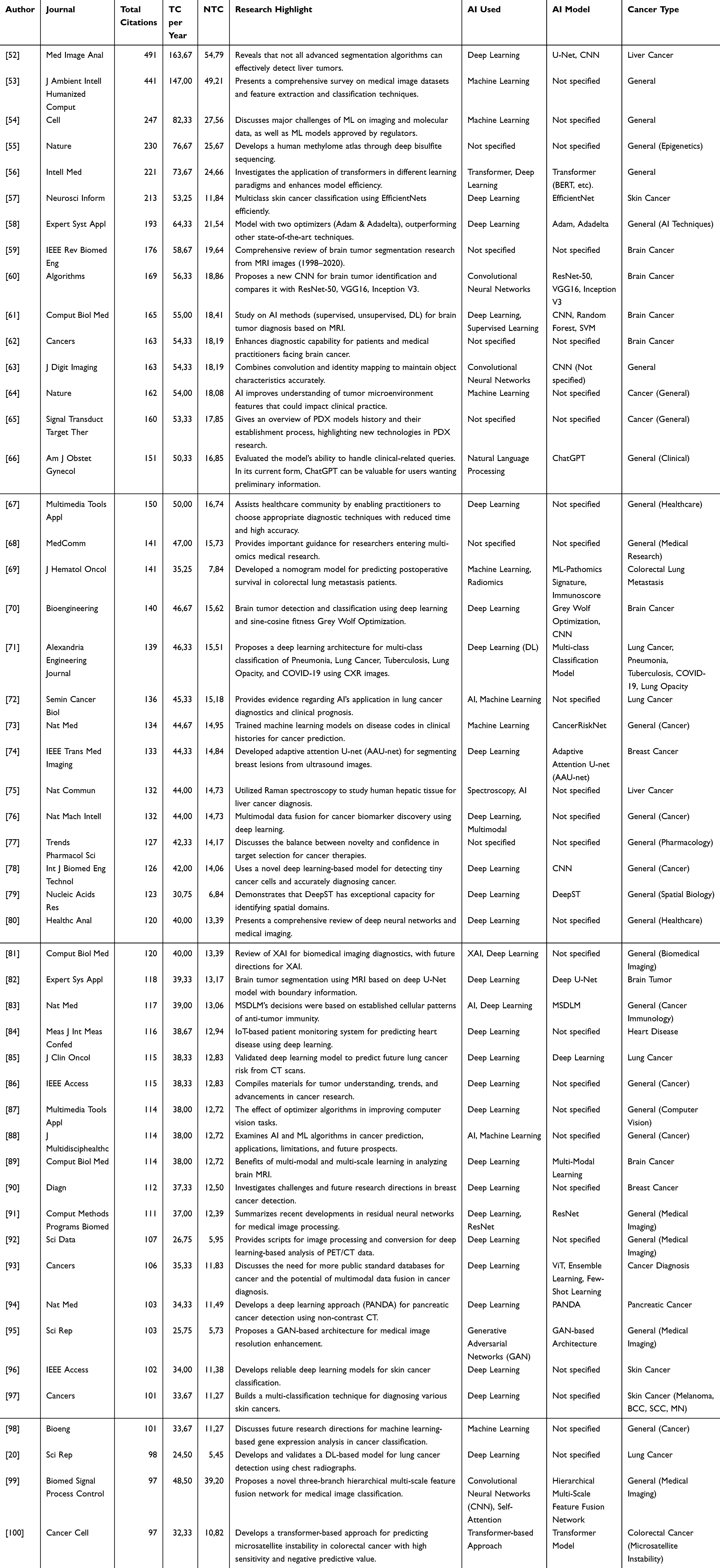 |
Table 3 Most Cited Documents |
These documents present a strong global trend in AI integration for medical diagnosis, especially brain imaging and cancer. The high degree of normalization of citations in some articles suggests that the scientific influence is not only quantitatively broad but also contextually relevant. Articles from reputable journals such as Nature and Cell also show high scientific validation, marking an important meeting point between basic science, cutting-edge technology, and clinical applications.
This collection of documents with the highest citations marks significant developments in the use of artificial intelligence (AI) technology and machine learning in the health field, especially in medical imaging-based diagnostics. Article Bilic et al (2023), as the most widely criticized, is an important marker that the effectiveness of the algorithm cannot be judged only by technical metrics, but also by applicative contexts such as organ type or targeted tumor type. This reinforces the narrative that cross-domain validation is essential in the development of AI-based systems in the medical field.
Besides, articles like those written by Kumar et al (2023) and Soomro et al (2023) show great value from literature studies or systematic reviews. In this age of knowledge acceleration, a comprehensive review of datasets, classification techniques, and research trends over two decades has become an important asset for new researchers and policymakers. The high number of citations in this type of article also signifies the need for a comprehensive knowledge structure as the foundation of subsequent innovations.
Several other studies, such as those written by Loyfere et al (2023) and Sorin et al (2023), it showed a cross-disiplin approach that began to dominate the global scientific landscape. Both combine genetic sequencing, biomolecular, and AI methods to generate deep insight into tumor micro-environment and genetic expression. It depicts a new direction of health research in which bioinformatics, precision medicine, and AI technology come together to answer complex challenges in the modern medical world.
Interestingly, transformer and CNN usage trends in articles such as He et al (2023) and Mahmud et al (2023) demonstrate the architectural evolution of AI models from mere image recognition to more complex and interpretive spatial representations. This phenomenon opens up great opportunities in building a clinical decision support system (CDSS) that is not only accurate, but also able to provide visual reasoning that health workers can understand. Thus, this trend of highlighted documents reflects not only technical success, but also the transition to more ethical, transparent, and applicative AI in real terms.
Most Frequent Words
The increasing frequency of words such as deep learning, machine learning, and convolutional neural networks indicates that the revolution of artificial intelligence in the medical world is not just a technological trend, but has been transformed into a new paradigm in how humans understand, map, and intervene in disease. This phenomenon reflects a major shift from a clinical intuition-based approach to a data- and algorithm-based approach. When deep learning models begin to rival, or even surpass the performance of human clinicians in certain tasks, an important question arises: not just how do algorithms work, but how far are we prepared to adopt and account for the decisions produced by machines as shown in Figure 5.
 |
Figure 5 Most frequent Keyword Plus. This figure presents the most frequently occurring Keywords Plus in the dataset. The size of each bar or bubble reflects the number of occurrences, and the labels indicate the exact frequency for each keyword. |
The dominance of terms such as “diagnostic imaging”, “diagnostic imaging”, and “diagnostic test accuracy study” suggests that the main concern of current research is not just early detection, but on ethically and clinically reliable diagnostic accuracy. With the emergence of diseases such as lung cancer and breath cancer at the top of the list, it can be read that the current focus of global research targets diseases with high mortality and high morphological complexity—where misdiagnosis has great implications for the patient’s quality of life. The key to model excellence lies not only in its algorithms, but in how it integrates optimal sensitivity and specificity values evenly.
In the deeper spectrum, terms such as “radiomics”, “histopathology”, “feature extraction”, and “transfer learning” suggest that research does not stop at visualization, but instead breaks the limits of interpretation into more deep biological representations. This is where artificial intelligence plays a transformative role: not just as a clinical aid, but as a means of dismantling disease microstructures—a domain previously accessible only through experimental laboratories or invasive biopsy. Thus, AI in medicine is not only about efficiency, but also about bringing fairness to access to state-of-the-art diagnostic technologies, especially to countries with limited resources.
Finally, the emergence of terms such as controlled studies, cohort analysis, and retrospective studies suggests that there is methodological caution in integrating AI into healthcare systems. Research is no longer solely oriented towards technological novelty, but also takes into account the validity of causality and clinical relevance. In this context, evidence-based approaches have begun to form strong nodes with data-driven approaches. The medical world now stands at the historical crossroads between humanism and automation—where technology must remain on the ethical side, and scientific progress must be constantly tested by empathy for human suffering.
Trending Topics
Keyword analysis results show that cancer research is now in a very rapid digital transformation phase. AI has become a strategic partner in efforts to detect, diagnose, predict, and treat cancer. However, this integration must continue to be accompanied by data usage ethics, clinical validation, and multidisciplinary collaboration to ensure that the benefits are not only technological but also transformative in the global healthcare system.
The results of analysis of the keyword plus Figure 6A and keyword author Figure 6B confirmed that in recent years, cancer research has been greatly influenced by advances in artificial intelligence technology, especially deep learning and convolutional neural network (CNN). Very high frequencies for keywords such as deep learning (21,698) and CNN (4894) suggest that this approach has become a major tool in medical image processing to detect, classify, and predict the presence of cancer, including lung and breast cancer. This trend is in line with the urgent need for faster, more accurate, and non-invasive cancer diagnosis. In the context of cancer, time is a crucial factor. Early detection has a profound effect on prognosis and the success of therapy. Therefore, the use of AI to accelerate and improve accuracy in reading MRI, CT-scan, and mammogram results is vital, especially in areas with limited medical specialists.
 |
Figure 6 Most frequent Keyword Plus. (A and B) illustrate the temporal trends of the most frequent Keywords Plus across the dataset. Each dot represents the appearance of a keyword in a given year, and the size of the dot reflects the frequency of the term. The horizontal lines indicate the time span during which the keyword was actively used in publications. (A) highlights terms with higher frequencies (5000–20,000 occurrences), while (B) shows emerging and specialized terms (2000–8000 occurrences). |
The consistent emergence of keywords such as medical imaging, diagnostic imaging, and image segmentation in 2023–2024 reinforces the conclusion that AI has integrated into modern diagnostic infrastructures. Even concepts such as image enhancement and feature extraction, which were previously computer engineering domains, are now an integral part of cancer research clinics and labs. This marks a new chapter of the convergence of technology and healthcare. Meanwhile, topics such as sensitivity and specificity, diagnostic accuracy, and receiver operating characteristics reflect the scientific community’s concern for the validity of AI models. In the context of cancer, misdiagnosis can be fatal. Therefore, performance testing of models with classical statistical parameters is still urgently needed. This is a reminder that AI-based approaches must remain based on rigorous scientific principles and can be clinically accounted.
The emergence of computer-aided diagnosis, machine-learning, and computer-assisted tomography also suggests that AI does not replace the role of doctors, but rather strengthens it. AI is positioned as a second reader or clinical assistant that helps speed up decision making. In cancer diagnosis, especially brain, lung, and breast tumors, this role becomes very strategic because it is able to filter out large numbers of anomalies with high consistency. In addition to technical aspects, keyword trends such as cohort analysis, controlled studies, and retrospective studies show that cancer research still demands a strong epidemiological approach. AI can excel in prediction, but to establish causality and formulate public policy requires rigorous classical research design. This combination of approaches signifies a paradigm shift from evidence-based medicine to AI-assisted evidence-based practice.
The emergence of topics such as Epstein–Barr virus infections and histopathology also suggests that cancer research relies not only on image, but also on molecular and immunology. Epstein–Barr, for example, is a known virus associated with nasopharyngeal cancer. In this context, AI has also begun to be used to analyze gene expression, DNA methylation, to classification of immune cells. This asserts that AI not only becomes a visualization tool, but also a molecular instrument. Keywords such as radiomics, transfer learning, and deep neural networks indicate that cutting-edge AI techniques are used to extract hidden information from image and genomic data. Radiomics, for example, allows the extraction of quantitative features from medical images that were previously invisible to the human eye. Transfer learning accelerates the adoption of models in new domains with little data. This is relevant in the context of rare cancers where the number of cases is limited. Temporarily, analysis shows that the dominance of deep learning, medical imaging, and CNN has occurred since 2023 with consistent projections until 2025. This reflects that the field is not yet saturated and there are still many innovation spaces, especially on sub-topics such as electrotherapeutics, photointerpretation, and arthroplasty. The emergence of these new topics suggests that AI penetration into clinical domains is becoming widespread and unstoppable.
Co-Occurences
To increase the understanding of co-occurrence in the context of cancer and AI research, consider the parameters used in this tissue analysis. This analysis uses several parameters to manage and optimize the representation of relationships between keywords, as well as to explore further insights into collaboration and inter-concept relationships in AI-based cancer research. Network layout settings are automatically used to organize nodes (points) and edges (relationships) in the network. With automatic layout, each node’s position is based on a principle that prioritizes inter-element relationships, which aids in network visualization so as to facilitate understanding of key word relationships as shown in Figure 7. This automatic layout facilitates the identification of patterns in cancer and AI research. The clustering algorithm used in this analysis is Walktrap, which allows for the division of keywords into more organized groups. This algorithm identifies subgroups within tissues based on their proximity, thus helping in mapping keywords related to cancer and AI into more relevant categories. For example, keywords such as deep learning and convolutional neural networks will tend to be in the same group, indicating a close relationship between the two technologies in cancer research.
 |
Figure 7 Most frequent Keyword Plus. This figure presents a network visualization of the most frequent Keywords Plus, showing their relationships based on co-occurrence within the dataset. Node size represents the frequency of each keyword, while edge thickness indicates the strength of co-occurrence between terms. Clusters are visually grouped to highlight thematic research areas. |
Normalization using association aims to measure how strong the relationships between keywords in the network are. In this case, the association helps to assess whether the two keywords that often appear together in the literature have significant correlations. For example, if lung cancer and deep learning keywords often appear together in research, high associations will show that AI technology has a strong application in lung cancer diagnosis. In this analysis, Node Color by Year is not enabled, which means that the color of the node is not based on the year of publication or trend development. Instead, the main focus is on grouping keywords and their interrelationships regardless of specific time. However, without year-based coloring, we can still gain a strong understanding of key concepts that are constantly evolving in cancer and AI research.
The number of nodes in this analysis refers to the keywords being analyzed. Each keyword that appears in cancer-related publications and AI becomes a node in the network. By identifying the number of nodes, we can measure how many concepts or topics relevant to cancer research and AI are explored in the literature. Repulsion forces are used to ensure that the nodes connected in the network are not stacked on top of each other and have space to be clearly separated. This parameter aims to provide sufficient distance between nodes, facilitate network visualization, and ensure that the related keywords remain visible separately but still show a clear relationship with each other. In this analysis, Remove Isolated Nodes is enabled, which means that keywords that do not have a direct relationship with other keywords will be removed from the network. This is important because it ensures that the formed tissue actually reflects keywords that have significant relevance in cancer and AI research, eliminating keywords that may arise by chance or have no effect on the main context. The minimum number of edges (relationships) used to maintain connections between nodes helps focus analysis on keywords that have more frequent interactions in publications. In the context of cancer research, it ensures that only relevant and frequently co-occurring keywords are taken into account, allowing us to gain a more meaningful insight into the relationship between AI technology and cancer disease.
Keywords of deep learning emerged as a central element in co-occurrence analysis, suggesting that this technology was the backbone in cancer research. Deep learning, especially using convolutional neural networks (CNNs), has been shown to be very effective in analyzing medical images, such as radiological or histopathological images, to detect cancer at an early stage. This opens up great opportunities to improve diagnosis accuracy, speed up identification, and reduce human errors described in Figure 8. Medical imaging, including techniques such as magnetic resonance imaging (MRI) and computerized tomography (CT), is closely related to AI technology. In cancer research, AI is used to process medical images more deeply and more quickly, enabling faster and more accurate tumor identification. This technology utilizes image segmentation and image enhancement techniques to improve image quality and facilitate cancer detection, for example, in the case of lung or breast cancer.
Figure 8 Continued. Figure 8 Conceptual structure maps using bibliometric techniques. (A–D) present visual representations of conceptual structures derived from the research corpus. (A) shows the Correspondence Analysis based on Keywords Plus, (B) shows the Correspondence Analysis based on Author Keywords, (C) shows the Multiple Correspondence Analysis (MCA) using Keywords Plus, and (D) shows the Multiple Correspondence Analysis (MCA) based on Author Keywords. These plots illustrate semantic relationships and thematic clustering, enabling identification of the main research topics and their interconnections.

Keywords for diagnosis and diagnosis highlight the crucial role AI plays in predicting and diagnosing different types of cancer. Through large and complex data analysis, AI models are able to find patterns that cannot be detected by conventional methods. This is particularly important in early identification of cancer, which increases the chances of successful treatment. Many cancer studies rely on controlled studies to test the effectiveness of various medical therapies or procedures. Controlled studies and major clinical studies identified in this analysis show that AI can contribute greatly to designing and analyzing data from these studies. AI can help manage patient data more efficiently and identify useful patterns for clinical assessment. Keywords algorithms and neural networks emphasize the importance of developing advanced algorithms used in cancer data analysis. For example, AI algorithms can be used to model complex relationships in genetic or molecular biology data, allowing a deeper understanding of cancer risk factors and their developmental mechanisms. One of the major challenges in cancer diagnosis is ensuring high accuracy. Diagnostic accuracy, sensitivity, and specificity are highly considered aspects of the development of AI models for cancer. The use of AI can increase diagnosis accuracy by reducing human error and increasing consistency in medical image interpretation. AI has also begun to be used in support of computer-aided diagnosis (CAD), a system that helps doctors diagnose and plan medical procedures. AI-based CAD enables increased accuracy in determining cancer types and plans the most appropriate therapy for patients.
The transfer learning keyword suggests that cancer research utilizes AI models that can be applied to multiple domains with few adjustments. With transfer learning, AI models that have been trained in one type of data (eg, breast image) can be applied to other data (eg, lung image), which is very useful for expanding AI applications in cancer research without requiring very large training data. Radiomics, which deals with radiomics, uses medical image data analysis to explore the microscopic characteristics of tumors. Through AI analysis, this information can be explored to provide more in-depth insight into the nature and potential of tumors, which ultimately supports the development of more personalized therapy. With more sophisticated tools such as predictive models and image analysis, researchers can devise a more appropriate approach to treating cancer patients. Through deep data analysis, AI provides faster, more efficient, and more targeted solutions in planning treatments that fit the patient’s condition.
Factorial Analysis
Factorial analysis that utilizes CA and MCA on different types of keywords helps researchers and policymakers understand how cancer and AI research is progressing. These findings provide a strong basis for forming funding strategies, compiling academic curricula, or focusing collaboration between institutions in this rapidly growing field. Identification of dominant conceptual dimensions is also important to map future research roadmaps (roadmaps). Factorial analysis or factorial analysis is used to identify and visualize latent dimensions (hidden) in bibliometric data sets. In the context of cancer and AI research, this technique helps to explore conceptual structures through frequently emerging keywords. This method simplifies data complexity and allows identification of the theme cluster underlying the vast literature as shown in Figure 8.
The Correspondence Analysis (CA) method with Keyword Plus produces the first dimension (DIM1) describing 36.05% of the total data variation, while DIM2 accounts for 8.73%. This shows that more than a third of conceptual information can be represented in just one dimension. Keyword Plus, generated automatically by indexing systems such as Web of Science, describes key research-related topics, and is powerful in revealing common themes of cancer research involving AI. In contrast to Keyword Plus, analysis of Author Keyword showed significantly lower variance: only 5.27% for DIMM1 and 3.73% for DIMM2. This indicates that keywords manually defined by the author do not significantly capture strong latent structures in the data. This could be due to variations in terminology or inconsistencies in the use of terms by different authors.
As the analysis was expanded to Multiple Correspondence Analysis, there was a significant increase in the proportion of the described variation. MCA allows simultaneous analysis of more than two categories or data dimensions. In bibliometric contexts, this provides a deeper understanding of complex relationships between various keywords. Multiple Correspondence Analysis with Keyword Plus produced remarkable results, with DIMM1 accounting for 80.01% of the variance, and DIMM2 at 8.76%. Figure 8 indicates that major themes in cancer and AI research are highly concentrated on one major conceptual axis. The size of DIMM1 contributions also indicates that there is a great similarity in the way themes such as deep learning, medical imaging, and diagnosis are shared.
MCA on Author Keyword generated 37.21% for DIMM1 and 14.66% for DIMM2. Although higher than CA, this value is still much lower than MCA on Keyword Plus. However, a more equitable distribution of variation between DIMM1 and DIMM2 shows that there are two important axes representing the dominant themes in research, reflecting the diversity of terminology and the research approach of authors. DIM1 generally reflects the main dimensions of research—eg, technology-based approaches such as deep learning, convolutional neural networks, and image analysis. Meanwhile, DIM2 can reflect secondary dimensions such as break cancer, lung cancer, histopathology, or methods of validation (diagnostic accuracy, sensitivity, and specificity).
The results of the analysis show that Keyword Plus provides a more uniform and structured trend picture in AI-based cancer research. It is suitable for use when wanting to understand large consistent themes in literature and establishing an early taxonomy for research topics. When an area like AI in cancer diagnosis progresses rapidly, Keyword Plus becomes an important tool to capture the emergence of new technologies or methods. Although the Author Keyword provides a lower proportion of variation, these keywords remain relevant to detecting new, special, or micro-trend topics. Terms such as radiomics, transfer learning, or neural networks may appear more quickly through keywords from authors than automated systems, making them an important tool for horizon scanning studies as shown in Table 4.
 |
Table 4 Total Variance |
One of the notable findings of Multiple Correspondence Analysis (MCA) on Keyword Plus is the emergence of keywords such as histopathology, human tissues, and computerized tomography. All three reflect imaging-based diagnostic approaches and biological tissue studies, which form the foundation in the development of AI models for accurate and non-invasive detection of cancer.
The emergence of histopathology and human tissues signifies the importance of real biomedical data in training artificial intelligence algorithms. This suggests that cancer research is not only focused on the computational aspect, but also highly integrated with the field of clinical medicine. Computerized tomography (CT) is a major source of imaging data that is often processed by AI in the classification of cancer types, especially the lungs and brain.
On the MCA Author Keyword, there appears to be dominance of popular deep learning architectures such as VGG16, ResNet50, and U-Net. The emergence of these models suggests that most AI-based cancer research relies on Convolutional Neural Networks (CNN) which has been shown to be effective in visual pattern recognition of medical images.
In addition to the AI model, MCA also features an explicit focus on specific types of cancer such as skin cancer, melanoma, and prostate cancer. This indicates that AI applications are not uniform across all types of cancers, but are highly dependent on data availability, visual characteristics of the disease, and their prevalence in the population.
The emergence of keywords such as mammography, digital pathology, radiotherapy, and ultrasound in the MCA Author Keyword expands the spectrum of imaging modality analyzed by AI. This indicates that the multi-modal approach (the combination of data from multiple sources) is increasingly becoming a trend in research to improve the accuracy of cancer diagnosis.
The terms histopathological images and radiomics indicate the trend of integrating quantitative data from medical images to produce signatures or biological markers. Radiomics, in particular, is an area that utilizes AI to extract numerical features from tumor images for prediction of therapy responses or prognosis, marking the shift from conventional visual diagnosis to data-based predictive approaches.
In Correspondence Analysis on Keyword Plus, findings such as image enhancement, lung cancer, and transfer learning show a focus on engineering and practical application aspects. Image enhancement is used to improve image quality before classification, while transfer learning allows training models with limited data—a critical strategy in medical research.
The emergence of transfer learning on CA Keyword Plus underscores the urgent need for efficiency in training AI models on limited and sensitive medical data. In the context of cancer, where manual annotation data is very expensive and difficult to obtain, this strategy allows for faster adoption of AI technology in medical institutions.
In Correspondence Analysis of Author Keywords, keywords such as attention mechanisms, transformers, and CNN appear. This indicates an evolution in the approach of AI models from traditional CNNs to attention-based models, such as Transformer which was originally popular in the NLP field but is now used in medical image analysis.
Conclusion
This study provides a comprehensive bibliometric analysis of the intersection between artificial intelligence (AI) and medical research, highlighting influential publications, emerging trends, and conceptual structures within the domain. Through the integration of various statistical and visual methods such as Correspondence Analysis (CA) and Multiple Correspondence Analysis (MCA), we were able to map the intellectual and thematic landscape of the field. The identification of dominant research themes, ranging from cancer diagnostics to deep learning-based medical imaging, underscores the pivotal role AI plays in transforming healthcare delivery and decision-making. The results demonstrate a rapidly growing body of literature, with several key documents exhibiting exceptionally high citation impact, reflecting both methodological innovation and practical relevance. Clustering and factor mapping revealed strong semantic relationships among terms, indicating that AI applications are increasingly focused on improving diagnostic accuracy, efficiency, and clinical outcomes. In summary, the integration of AI into medical research is not only expanding but also becoming more specialized and impactful. This bibliometric study serves as a valuable reference for researchers, policymakers, and practitioners aiming to navigate and contribute to this evolving field. Future investigations may benefit from longitudinal studies and dynamic topic modeling to track the evolution of AI in medicine more granularly over time. Future research may benefit from integrating bibliometric insights with empirical clinical data, cross-domain comparative analyses, and dynamic topic modeling, in order to capture the temporal evolution, translational impact, and ethical dimensions of AI applications in medicine.
Data Sharing Statement
The source code and the material and findings data of this study are openly available in full access by the corresponding author.
Acknowledgment
Rezzy Eko Caraka and Khairunnisa Supardi contributed equally as first authors and were responsible for the conceptualization of this study. Rezzy Eko Caraka and Rung Ching Chen contributed equally and are designated as co-corresponding authors. The authors express their sincere gratitude to Universitas Padjadjaran and the Vibrant Academic Community of Telkom University for their support in scholarly publications. This work was partially supported by internal research funding from the authors’ respective institutions.
Disclosure
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
References
1. Tjindarbumi D, Mangunkusumo R. Cancer in Indonesia, present and future. Jpn J Clin Oncol. 2002;32(suppl 1):S17–21. doi:10.1093/jjco/hye123
2. Martina D, Kustanti CY, Dewantari R, et al. Opportunities and challenges for advance care planning in strongly religious family-centric societies: a Focus group study of Indonesian cancer-care professionals. BMC Palliat Care. 2022;21(1). doi:10.1186/s12904-022-01002-6
3. Permitasari NPAL, Satibi S, Kristina SA. National burden of cancers attributable to secondhand smoking in Indonesia. Asian Pacific J Cancer Prevention. 2018;19(7):1951–1955. doi:10.22034/APJCP.2018.19.7.1951
4. Pardamean B, Baurley JW, Pardamean CI, Figueiredo JC. Changing colorectal cancer trends in Asians. Int J Colorectal Dis. 2016;31(8):1537–1538. doi:10.1007/s00384-016-2564-z
5. Zhao L, Cho WC, Nicolls MR. Colorectal cancer-associated microbiome patterns and signatures. Front Genet. 2021;12. doi:10.3389/fgene.2021.787176.
6. Billy M, Sholihah H, Andanni K, Anggraeni MI, Siregar SM, Mirtha LT. Obesity as predictor of mortality of colorectal cancer: an evidence-based case report. Acta Med Indones. 2016;48(3):242–246.
7. Hassan MR, Hossain MM, Begg RK, Ramamohanarao K, Morsi Y. Breast-Cancer identification using HMM-fuzzy approach. Comput Biol Med. 2010;40(3):240–251. doi:10.1016/j.compbiomed.2009.11.003
8. Hao K-J, Jia X, Dai WT, et al. Mapping intellectual structures and research hotspots of triple negative breast cancer: a bibliometric analysis. Front Oncol. 2022;11. doi:10.3389/fonc.2021.689553
9. Shi J, Duan Y. Knowledge-map and research trends of circulating tumor cells in breast cancer: a scientometric analysis. Discover Oncol. 2024;15(1). doi:10.1007/s12672-024-01385-3
10. Gichoya JW, Banerjee I, Bhimireddy AR, et al. AI recognition of patient race in medical imaging: a modelling study. Lancet Digit Health. 2022;4(6):e406–e414. doi:10.1016/S2589-7500(22)00063-2
11. Kijewski S, Ronchi E, Vayena E. International Organisations and the Global Governance of AI in Health; 2024. doi:10.4337/9781802205657.00024
12. Ghoshal A, Tucker B, Sanghera B, Lup Wong W. Estimating uncertainty in deep learning for reporting confidence to clinicians in medical image segmentation and diseases detection. WILEY. 2019;1–34.
13. Vandromme M, Jacques J, Taillard J, Jourdan L, Dhaenens C. A scalable biclustering method for heterogeneous medical data. LNCS. 2016;10122. doi:10.1007/978-3-319-51469-7_6.
14. Uitert MV, Meuleman W, Wessels L. Biclustering sparse binary genomic data. J Comput Biol. 2008;15(10):1329–1345. doi:10.1089/cmb.2008.0066
15. M.Repetto G, Jaramillo BR. Rare diseases: genomics and public health. Applied genomics and public health. 2020;37–51.
16. Huda SB, Noureen N. MTBGD: mutli type biclustering for genomic Data, in
17. Cabrera AP, Monickaraj F, Rangasamy S, Hobbs S, McGuire P, Das A. Do Genomic Factors Play a Role in Diabetic Retinopathy? J Clin Med. 2020;9(1):216.
18. Moutarde F. Deep-Learning: General principles + Convolutional Neural Networks. 2018.
19. din NMU, Dar RA, Rasool M, Assad A. Breast cancer detection using deep learning: datasets, methods, and challenges ahead. Comput Biol Med. 2022;149. doi:10.1016/j.compbiomed.2022.106073.
20. Shimazaki A, Ueda D, Choppin A, et al. Deep learning-based algorithm for lung cancer detection on chest radiographs using the segmentation method. Sci Rep. 2022;12(1). doi:10.1038/s41598-021-04667-w
21. Talukder MA, Islam MM, Uddin MA, Akhter A, Hasan KF, Moni MA. Machine learning-based lung and colon cancer detection using deep feature extraction and ensemble learning. Expert Syst Appl. 2022;205. doi:10.1016/j.eswa.2022.117695.
22. Girsang AS, Nugraha DBGKJ. Age classification of moviegoers based on facial image using deep learning. TEM J. 2022;11(3):1406–1415. doi:10.18421/TEM113-52
23. Chiou T-W, Yen C-I, Hsiao Y-C, Chen H-C. AI prediction for post-lower blepharoplasty age reduction. Aesthet Surg J. 2024;44(12):NP922–NP930. doi:10.1093/asj/sjae182
24. Na W, Lee IJ, Koh I, Kwon M, Song YS, Lee SH. Cancer-specific functional profiling in microsatellite-unstable (MSI) colon and endometrial cancers using combined differentially expressed genes and biclustering analysis. Medicine. 2023;102(19):E33647. doi:10.1097/MD.0000000000033647
25. Moral-Munoz JA, Arroyo Morales M, Díaz Rodríguez CL, Herrera Viedma E. Thematic trends in complementary and alternative medicine applied in cancer-related symptoms. J Data Inf Sci. 2018;3(2):1–19.
26. Dey L, Mukhopadhyay A. Biclustering-based association rule mining approach for predicting cancer-associated protein interactions. IET Syst Biol. 2019;13(5):234–242. doi:10.1049/iet-syb.2019.0045
27. Sudhakar A. History of cancer, ancient and modern treatment methods. J Cancer Sci Ther. 2009;01(02):i–iv. doi:10.4172/1948-5956.100000e2
28. Organization WH. Accelerating cervical cancer elimination report by the director-general cervical cancer: a global public health priority. 94, Available from:http://apps.who.int/iris/bitstream/handle/10665/272534/WHO-NMH-NVI-18.8-eng.pdf?ua=1.
29. Campra M, Riva P, Oricchio G, Brescia V. Bibliometrix analysis of medical tourism. Health Serv Manage Res. 2022;35(3):172–188. doi:10.1177/09514848211011738
30. Ejaz H, Zeeshan HM, Ahmad F, et al. Bibliometric analysis of publications on the omicron variant from 2020 to 2022 in the Scopus database using R and VOSviewer. Int J Environ Res Public Health. 2022;19(19). doi:10.3390/ijerph191912407
31. Thomas B, Joseph J, Jose J. Explorative bibliometric study of medical image analysis: unveiling trends and advancements. Scient Visual. 2023;15(5):35–49. doi:10.26583/sv.15.5.04
32. Wei W, Jiang Z. A bibliometrix-based visualization analysis of international studies on conversations of people with aphasia: present and prospects. Heliyon. 2023;9(6). doi:10.1016/j.heliyon.2023.e16839
33. Yumnam G, Singh CI. A scientometric visualization of 32 years of leukemia research in India. Sci Technol Libr. 2024;43(1):98–116. doi:10.1080/0194262X.2023.2181279
34. Haris A, Aini Q. Bibliometric analysis of electronic medical records (EMR) acceptance and adoption: trends, insights, and future directions. J Angiother. 2024;8(5). doi:10.25163/angiotherapy.859700
35. Meşe S. A bibliometric analysis of transplantation and non-pharmacology. Exp Clin Transplant. 2024;22(12):947–956. doi:10.6002/ect.2024.0056
36. Kumar D, Shandilya AK, Srivastava S. The journey of F1000Research since inception: through bibliometric analysis. F1000Res. 2023;12. doi:10.12688/f1000research.134244.2.
37. Nayak S, Behera DK, Shetty J, Shetty A, Kumar S, Shenoy SS. Bibliometric analysis of scientific publications on health care insurance in India from 2000 to 2021. Int J Healthc Manag. 2023;16(2):188–196. doi:10.1080/20479700.2022.2085848
38. Kaur GK, Manchanda N, Singla S, Modi SK, Rana PS, Sihag D. WoS Driven Bibliometric Analysis on Genetic Disease Prediction Using Artificial Intelligence, in
39. Hamidi A, Khosravi A, Hejazi R, FatemehTorabi Abtin A. A scientometric approach to psychological research during the COVID-19 pandemic. Curr Psychol. 2024;43(1):155–164. doi:10.1007/s12144-023-04264-2
40. Moid A, Raza MM, Javed M, Jahan K. Global research mapping in records and archives management: an investigation. Global Knowledge Memory Commun. 2024. doi:10.1108/GKMC-08-2023-0307
41. Kumari A, Kumar S. Data science in healthcare- a bibliometric study and analysis. CCIS. 2025;2382. doi:10.1007/978-3-031-86069-0_27.
42. Alfahad OA, Rehman TU, Woodman A, Malaekah EA, Rasheed M. Mapping knowledge and themes trends in the cybersecurity of medical devices: a bibliometric Investigation. Sci Technol Libr. 2024;43(4):368–378. doi:10.1080/0194262X.2023.2274547
43. Caraka RE, Wardhana IW, Kim Y, et al. Connectivity, sport events, and tourism development of Mandalika’s special economic zone: a perspective from big data cognitive analytics. Cogent Bus Manage. 2023;10(1). doi:10.1080/23311975.2023.2183565
44. Roberti de Siqueira F, Schwartz WR, Pedrini H. Multi-scale gray level co-occurrence matrices for texture description. Neurocomputing. 2013;120:336–345. doi:10.1016/j.neucom.2012.09.042
45. Ramamurthy B, Chandran KR. Content based medical image retrieval with texture content using gray level co-occurrence matrix and K-means clustering algorithms department of CIS, PSG College of Technology, Coimbatore, India. J Computer Sci. 2012;8(7):1070–1076.
46. Hudaefi FA, Caraka RE, Wahid H. Zakat administration in times of COVID-19 pandemic in Indonesia: a knowledge discovery via text mining. Int J Islamic Middle Eastern Finance Manag. 2021;15: 271–86.
47. Pledger S, Arnold R. Multivariate methods using mixtures: correspondence analysis, scaling and pattern-detection. Comput Stat Data Anal. 2014;71:241–261. doi:10.1016/j.csda.2013.05.013
48. ter Braak CJF, Verdonschot PFM. Canonical correspondence analysis and related multivariate methods in aquatic ecology. Aquat Sci. 1995. doi:10.1007/BF00877430
49. Cuadras CM, Greenacre M. A short history of statistical association: from correlation to correspondence analysis to copulas. J Multivar Anal. 2022;188. doi:10.1016/j.jmva.2021.104901.
50. Brissaud C. Multiple Correspondence Analysis. 2023.
51. Ringrose TJ. Alternative bootstrap confidence regions for multiple correspondence analysis. Commun Stat Simul Comput. 2024. doi:10.1080/03610918.2024.2330716
52. Bilic P, Christ P, Li HB, et al. The liver tumor segmentation benchmark (LiTS). Med Image Anal. 2023;84. doi:10.1016/j.media.2022.102680
53. Kumar Y, Koul A, Singla R, Ijaz MF. Artificial intelligence in disease diagnosis: a systematic literature review, synthesizing framework and future research agenda. J Ambient Intell Humaniz Comput. 2023;14(7):8459–8486. doi:10.1007/s12652-021-03612-z
54. Swanson K, Wu E, Zhang A, Alizadeh AA, Zou J. From patterns to patients: advances in clinical machine learning for cancer diagnosis, prognosis, and treatment. Cell. 2023;186(8):1772–1791. doi:10.1016/j.cell.2023.01.035
55. Loyfer N, Magenheim J, Peretz A, et al. A DNA methylation atlas of normal human cell types. Nature. 2023;613(7943):355–364. doi:10.1038/s41586-022-05580-6
56. He K, Gan C, Li Z, et al. Transformers in medical image analysis. Intelligent Med. 2023;3(1):59–78. doi:10.1016/j.imed.2022.07.002
57. Ali K, Shaikh ZA, Khan AA, Laghari AA. Multiclass skin cancer classification using EfficientNets – a first step towards preventing skin cancer. Neurosci Info. 2022;2(4). doi:10.1016/j.neuri.2021.100034
58. Anand V, Gupta S, Koundal D, Singh K. Fusion of U-net and CNN model for segmentation and classification of skin lesion from dermoscopy images. Expert Syst Appl. 2023;213. doi:10.1016/j.eswa.2022.119230.
59. Soomro TA, Zheng L, Afifi AJ, et al. Image segmentation for MR brain tumor detection using machine learning: a review. IEEE Rev Biomed Eng. 2023;16:70–90. doi:10.1109/RBME.2022.3185292
60. Mahmud MI, Mamun M, Abdelgawad A. A deep analysis of brain tumor detection from MR images using deep learning networks. Algorithms. 2023;16(4). doi:10.3390/a16040176
61. Ranjbarzadeh R, Caputo A, Tirkolaee EB, Ghoushchi SJ, Bendechache M. Brain tumor segmentation of MRI images: a comprehensive review on the application of artificial intelligence tools. Comput Biol Med. 2023;152. doi:10.1016/j.compbiomed.2022.106405.
62. Abdusalomov AB, Mukhiddinov M, Whangbo TK. Brain tumor detection based on deep learning approaches and magnetic resonance imaging. Cancers. 2023;15(16). doi:10.3390/cancers15164172
63. Kashyap R. Stochastic dilated residual ghost model for breast cancer detection. J Digit Imaging. 2023;36(2):562–573. doi:10.1007/s10278-022-00739-z
64. Sorin M, Rezanejad M, Karimi E, et al. Single-cell spatial landscapes of the lung tumour immune microenvironment. Nature. 2023;614(7948):548–554. doi:10.1038/s41586-022-05672-3
65. Liu Y, Wu W, Cai C, Zhang H, Shen H, Han Y. Patient-derived xenograft models in cancer therapy: technologies and applications. Signal Transduct Target Ther. 2023;8(1). doi:10.1038/s41392-023-01419-2
66. Grünebaum A, Chervenak J, Pollet SL, Katz A, Chervenak FA. The exciting potential for ChatGPT in obstetrics and gynecology. Am J Obstet Gynecol. 2023;228(6):696–705. doi:10.1016/j.ajog.2023.03.009
67. Rana M, Bhushan M. Machine learning and deep learning approach for medical image analysis: diagnosis to detection. Multimed Tools Appl. 2023;82(17):26731–26769. doi:10.1007/s11042-022-14305-w
68. Chen C, Wang J, Pan D, et al. Applications of multi-omics analysis in human diseases. MedComm. 2023;4(4). doi:10.1002/mco2.315
69. Wang R, Dai W, Gong J, et al. Development of a novel combined nomogram model integrating deep learning-pathomics, radiomics and immunoscore to predict postoperative outcome of colorectal cancer lung metastasis patients. J Hematol Oncol. 2022;15(1). doi:10.1186/s13045-022-01225-3
70. ZainEldin H, Gamel SA, El-Kenawy ES, et al. Brain tumor detection and classification using deep learning and sine-cosine fitness grey wolf optimization. Bioengineering. 2023;10(1). doi:10.3390/bioengineering10010018
71. Alshmrani GMM, Ni Q, Jiang R, Pervaiz H, Elshennawy NM. A deep learning architecture for multi-class lung diseases classification using chest X-ray (CXR) images. Alexandria Eng J. 2023;64:923–935. doi:10.1016/j.aej.2022.10.053
72. Huang S, Yang J, Shen N, Xu Q, Zhao Q. Artificial intelligence in lung cancer diagnosis and prognosis: current application and future perspective. Acad Press. 2023. doi:10.1016/j.semcancer.2023.01.006
73. Placido D, Yuan B, Hjaltelin JX, et al. A deep learning algorithm to predict risk of pancreatic cancer from disease trajectories. Nat Med. 2023;29(5):1113–1122. doi:10.1038/s41591-023-02332-5
74. Chen G, Li L, Dai Y, Zhang J, Yap MH. AAU-Net: an adaptive attention U-net for breast lesions segmentation in ultrasound images. IEEE Trans Med Imaging. 2023;42(5):1289–1300. doi:10.1109/TMI.2022.3226268
75. Huang L, Sun H, Sun L, et al. Rapid, label-free histopathological diagnosis of liver cancer based on Raman spectroscopy and deep learning. Nat Commun. 2023;14(1):48. doi:10.1038/s41467-022-35696-2
76. Steyaert S, Pizurica M, Nagaraj D, et al. Multimodal data fusion for cancer biomarker discovery with deep learning. Nat Mach Intell. 2023;5(4):351–362. doi:10.1038/s42256-023-00633-5
77. Pun FW, Ozerov IV, Zhavoronkov A. AI-powered therapeutic target discovery. Trends Pharmacol Sci. 2023;44(9):561–572. doi:10.1016/j.tips.2023.06.010
78. Kashyap R. Histopathological image classification using dilated residual grooming kernel model. Int J Biomed Eng Technol. 2023;41(3):272–299. doi:10.1504/IJBET.2023.129819
79. Xu C, Jin X, Wei S, et al. DeepST: identifying spatial domains in spatial transcriptomics by deep learning. Nucleic Acids Res. 2022;50(22):E131. doi:10.1093/nar/gkac901
80. Mall PK, Singh PK, Srivastav S, et al. A comprehensive review of deep neural networks for medical image processing: recent developments and future opportunities. Healthcare Anal. 2023;4. doi:10.1016/j.health.2023.100216
81. Nazir S, Dickson DM, Akram MU. Survey of explainable artificial intelligence techniques for biomedical imaging with deep neural networks. Comput Biol Med. 2023;156. doi:10.1016/j.compbiomed.2023.106668.
82. Gab Allah AM, Sarhan AM, Elshennawy NM. Edge U-Net: brain tumor segmentation using MRI based on deep U-Net model with boundary information. Expert Syst Appl. 2023;213. doi:10.1016/j.eswa.2022.118833.
83. Foersch S, Glasner C, Woerl AC, et al. Multistain deep learning for prediction of prognosis and therapy response in colorectal cancer. Nat Med. 2023;29(2):430–439. doi:10.1038/s41591-022-02134-1
84. Ramkumar G, Seetha J, Priyadarshini R, Gopila M, Saranya G. IoT-based patient monitoring system for predicting heart disease using deep learning. Measurement. 2023;218:113235. doi:10.1016/J.MEASUREMENT.2023.113235
85. Mikhael PG, Wohlwend J, Yala A, et al. Sybil: a validated deep learning model to predict future lung cancer risk from a single low-dose chest computed tomography. J Clin Oncol. 2023;41(12):2191–2200. doi:10.1200/JCO.22.01345
86. Solanki S, Singh UP, Chouhan SS, Jain S. Brain tumor detection and classification using intelligence techniques: an overview. IEEE Access. 2023;11:12870–12886. doi:10.1109/ACCESS.2023.3242666
87. Hassan E, Shams MY, Hikal NA, Elmougy S. The effect of choosing optimizer algorithms to improve computer vision tasks: a comparative study. Multimed Tools Appl. 2023;82(11):16591–16633. doi:10.1007/s11042-022-13820-0
88. Zhang B, Shi H, Wang H. Machine learning and AI in cancer prognosis, prediction, and treatment selection: a critical approach. J Multidiscip Healthc. 2023;16:1779–1791. doi:10.2147/JMDH.S410301
89. Wu P, Wang Z, Zheng B, Li H, Alsaadi FE, Zeng N. AGGN: attention-based glioma grading network with multi-scale feature extraction and multi-modal information fusion. Comput Biol Med. 2023;152:106457. doi:10.1016/J.COMPBIOMED.2022.106457
90. Nasser M, Yusof UK. Deep learning based methods for breast cancer diagnosis: a systematic review and future direction. Diagnostics. 2023;13(1). doi:10.3390/diagnostics13010161
91. Xu W, Fu Y-L, Zhu D. ResNet and its application to medical image processing: research progress and challenges. Comput Methods Programs Biomed. 2023;240. doi:10.1016/j.cmpb.2023.107660.
92. Gatidis S, Hepp T, Früh M, et al. A whole-body FDG-PET/CT dataset with manually annotated tumor lesions. Sci Data. 2022;9(1). doi:10.1038/s41597-022-01718-3
93. Jiang X, Hu Z, Wang S, Zhang Y. Deep learning for medical image-based cancer diagnosis. Cancers. 2023;15(14). doi:10.3390/cancers15143608
94. Cao K, Xia Y, Yao J, et al. Large-scale pancreatic cancer detection via non-contrast CT and deep learning. Nat Med. 2023;29(12):3033–3043. doi:10.1038/s41591-023-02640-w
95. Ahmad W, Ali H, Shah Z, Azmat S. A new generative adversarial network for medical images super resolution. Sci Rep. 2022;12(1). doi:10.1038/s41598-022-13658-4
96. Mridha K, Uddin MM, Shin J, Khadka S, Mridha MF. An interpretable skin cancer classification using optimized convolutional neural network for a smart healthcare system. IEEE Access. 2023;11:41003–41018. doi:10.1109/ACCESS.2023.3269694
97. Tahir M, Naeem A, Malik H, Tanveer J, Naqvi RA, Lee S-W. DSCC_Net: multi-classification deep learning models for diagnosing of skin cancer using dermoscopic images. Cancers. 2023;15(7). doi:10.3390/cancers15072179
98. Alharbi F, Vakanski A. Machine learning methods for cancer classification using gene expression data: a review. Bioengineering. 2023;10(2). doi:10.3390/bioengineering10020173
99. Huo X, Sun G, Tian S, et al. HiFuse: hierarchical multi-scale feature fusion network for medical image classification. Biomed Signal Process Control. 2024;87:105534. doi:10.1016/J.BSPC.2023.105534
100. Wagner SJ, Reisenbüchler D, West NP, et al. Transformer-based biomarker prediction from colorectal cancer histology: a large-scale multicentric study. Cancer Cell. 2023;41(9):1650–1661.e4. doi:10.1016/J.CCELL.2023.08.002
 © 2025 The Author(s). This work is published and licensed by Dove Medical Press Limited. The
full terms of this license are available at https://www.dovepress.com/terms
and incorporate the Creative Commons Attribution
- Non Commercial (unported, 4.0) License.
By accessing the work you hereby accept the Terms. Non-commercial uses of the work are permitted
without any further permission from Dove Medical Press Limited, provided the work is properly
attributed. For permission for commercial use of this work, please see paragraphs 4.2 and 5 of our Terms.
© 2025 The Author(s). This work is published and licensed by Dove Medical Press Limited. The
full terms of this license are available at https://www.dovepress.com/terms
and incorporate the Creative Commons Attribution
- Non Commercial (unported, 4.0) License.
By accessing the work you hereby accept the Terms. Non-commercial uses of the work are permitted
without any further permission from Dove Medical Press Limited, provided the work is properly
attributed. For permission for commercial use of this work, please see paragraphs 4.2 and 5 of our Terms.